 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-R1: Protocol-Guided and Modality-Agnostic MLLM for Reliable ECG Interpretation
Feb 04, 2026Electrocardiography (ECG) serves as an indispensable diagnostic tool in clinical practice, yet existing multimodal large language models (MLLMs) remain unreliable for ECG interpretation, often producing plausible but clinically incorrect analyses. To address this, we propose ECG-R1, the first reasoning MLLM designed for reliable ECG interpretation via three innovations. First, we construct the interpretation corpus using \textit{Protocol-Guided Instruction Data Generation}, grounding interpretation in measurable ECG features and monograph-defined quantitative thresholds and diagnostic logic. Second, we present a modality-decoupled architecture with \textit{Interleaved Modality Dropout} to improve robustness and cross-modal consistency when either the ECG signal or ECG image is missing. Third, we present \textit{Reinforcement Learning with ECG Diagnostic Evidence Rewards} to strengthen evidence-grounded ECG interpretation. Additionally, we systematically evaluate the ECG interpretation capabilities of proprietary, open-source, and medical MLLMs, and provide the first quantitative evidence that severe hallucinations are widespread, suggesting that the public should not directly trust these outputs without independent verification. Code and data are publicly available at \href{https://github.com/PKUDigitalHealth/ECG-R1}{here}, and an online platform can be accessed at \href{http://ai.heartvoice.com.cn/ECG-R1/}{here}.
Attention Needs to Focus: A Unified Perspective on Attention Allocation
Jan 07, 2026The Transformer architecture, a cornerstone of modern Large Language Models (LLMs), has achieved extraordinary success in sequence modeling, primarily due to its attention mechanism. However, despite its power, the standard attention mechanism is plagued by well-documented issues: representational collapse and attention sink. Although prior work has proposed approaches for these issues, they are often studied in isolation, obscuring their deeper connection. In this paper, we present a unified perspective, arguing that both can be traced to a common root -- improper attention allocation. We identify two failure modes: 1) Attention Overload, where tokens receive comparable high weights, blurring semantic features that lead to representational collapse; 2) Attention Underload, where no token is semantically relevant, yet attention is still forced to distribute, resulting in spurious focus such as attention sink. Building on this insight, we introduce Lazy Attention, a novel mechanism designed for a more focused attention distribution. To mitigate overload, it employs positional discrimination across both heads and dimensions to sharpen token distinctions. To counteract underload, it incorporates Elastic-Softmax, a modified normalization function that relaxes the standard softmax constraint to suppress attention on irrelevant tokens. Experiments on the FineWeb-Edu corpus, evaluated across nine diverse benchmarks, demonstrate that Lazy Attention successfully mitigates attention sink and achieves competitive performance compared to both standard attention and modern architectures, while reaching up to 59.58% attention sparsity.
Advanced Global Wildfire Activity Modeling with Hierarchical Graph ODE
Jan 04, 2026Wildfires, as an integral component of the Earth system, are governed by a complex interplay of atmospheric, oceanic, and terrestrial processes spanning a vast range of spatiotemporal scales. Modeling their global activity on large timescales is therefore a critical yet challenging task. While deep learning has recently achieved significant breakthroughs in global weather forecasting, its potential for global wildfire behavior prediction remains underexplored. In this work, we reframe this problem and introduce the Hierarchical Graph ODE (HiGO), a novel framework designed to learn the multi-scale, continuous-time dynamics of wildfires. Specifically, we represent the Earth system as a multi-level graph hierarchy and propose an adaptive filtering message passing mechanism for both intra- and inter-level information flow, enabling more effective feature extraction and fusion. Furthermore, we incorporate GNN-parameterized Neural ODE modules at multiple levels to explicitly learn the continuous dynamics inherent to each scale. Through extensive experiments on the SeasFire Cube dataset, we demonstrate that HiGO significantly outperforms state-of-the-art baselines on long-range wildfire forecasting. Moreover, its continuous-time predictions exhibit strong observational consistency, highlighting its potential for real-world applications.
Rethinking the Spatio-Temporal Alignment of End-to-End 3D Perception
Dec 29, 2025Spatio-temporal alignment is crucial for temporal modeling of end-to-end (E2E) perception in autonomous driving (AD), providing valuable structural and textural prior information. Existing methods typically rely on the attention mechanism to align objects across frames, simplifying the motion model with a unified explicit physical model (constant velocity, etc.). These approaches prefer semantic features for implicit alignment, challenging the importance of explicit motion modeling in the traditional perception paradigm. However, variations in motion states and object features across categories and frames render this alignment suboptimal. To address this, we propose HAT, a spatio-temporal alignment module that allows each object to adaptively decode the optimal alignment proposal from multiple hypotheses without direct supervision. Specifically, HAT first utilizes multiple explicit motion models to generate spatial anchors and motion-aware feature proposals for historical instances. It then performs multi-hypothesis decoding by incorporating semantic and motion cues embedded in cached object queries, ultimately providing the optimal alignment proposal for the target frame. On nuScenes, HAT consistently improves 3D temporal detectors and trackers across diverse baselines. It achieves state-of-the-art tracking results with 46.0% AMOTA on the test set when paired with the DETR3D detector. In an object-centric E2E AD method, HAT enhances perception accuracy (+1.3% mAP, +3.1% AMOTA) and reduces the collision rate by 32%. When semantics are corrupted (nuScenes-C), the enhancement of motion modeling by HAT enables more robust perception and planning in the E2E AD.
X-ray Insights Unleashed: Pioneering the Enhancement of Multi-Label Long-Tail Data
Dec 24, 2025Long-tailed pulmonary anomalies in chest radiography present formidable diagnostic challenges. Despite the recent strides in diffusion-based methods for enhancing the representation of tailed lesions, the paucity of rare lesion exemplars curtails the generative capabilities of these approaches, thereby leaving the diagnostic precision less than optimal. In this paper, we propose a novel data synthesis pipeline designed to augment tail lesions utilizing a copious supply of conventional normal X-rays. Specifically, a sufficient quantity of normal samples is amassed to train a diffusion model capable of generating normal X-ray images. This pre-trained diffusion model is subsequently utilized to inpaint the head lesions present in the diseased X-rays, thereby preserving the tail classes as augmented training data. Additionally, we propose the integration of a Large Language Model Knowledge Guidance (LKG) module alongside a Progressive Incremental Learning (PIL) strategy to stabilize the inpainting fine-tuning process. Comprehensive evaluations conducted on the public lung datasets MIMIC and CheXpert demonstrate that the proposed method sets a new benchmark in performance.
VSA:Visual-Structural Alignment for UI-to-Code
Dec 23, 2025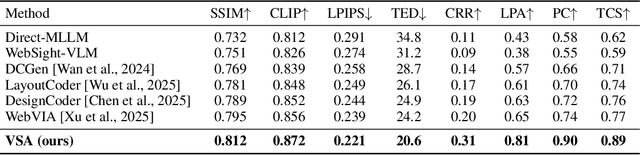
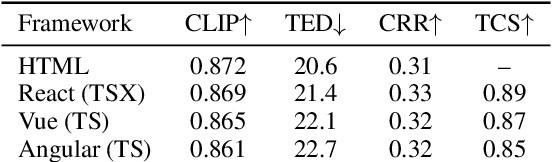
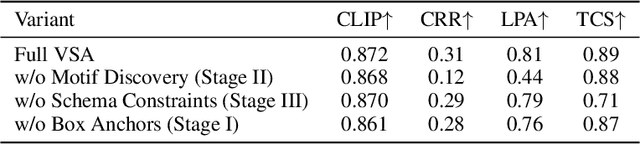
The automation of user interface development has the potential to accelerate software delivery by mitigating intensive manual implementation. Despite the advancements in Large Multimodal Models for design-to-code translation, existing methodologies predominantly yield unstructured, flat codebases that lack compatibility with component-oriented libraries such as React or Angular. Such outputs typically exhibit low cohesion and high coupling, complicating long-term maintenance. In this paper, we propose \textbf{VSA (VSA)}, a multi-stage paradigm designed to synthesize organized frontend assets through visual-structural alignment. Our approach first employs a spatial-aware transformer to reconstruct the visual input into a hierarchical tree representation. Moving beyond basic layout extraction, we integrate an algorithmic pattern-matching layer to identify recurring UI motifs and encapsulate them into modular templates. These templates are then processed via a schema-driven synthesis engine, ensuring the Large Language Model generates type-safe, prop-drilled components suitable for production environments. Experimental results indicate that our framework yields a substantial improvement in code modularity and architectural consistency over state-of-the-art benchmarks, effectively bridging the gap between raw pixels and scalable software engineering.
Copy-Paste to Mitigate Large Language Model Hallucinations
Oct 01, 2025While Retrieval-Augmented Generation (RAG) enables large language models (LLMs) to generate contextually grounded responses, contextual faithfulness remains challenging as LLMs may not consistently trust provided context, leading to hallucinations that undermine reliability. We observe an inverse correlation between response copying degree and context-unfaithful hallucinations on RAGTruth, suggesting that higher copying degrees reduce hallucinations by fostering genuine contextual belief. We propose CopyPasteLLM, obtained through two-stage high-copying response preference training. We design three prompting methods to enhance copying degree, demonstrating that high-copying responses achieve superior contextual faithfulness and hallucination control. These approaches enable a fully automated pipeline that transforms generated responses into high-copying preference data for training CopyPasteLLM. On FaithEval, ConFiQA and PubMedQA, CopyPasteLLM achieves best performance in both counterfactual and original contexts, remarkably with 12.2% to 24.5% accuracy improvements on FaithEval over the best baseline, while requiring only 365 training samples -- 1/50th of baseline data. To elucidate CopyPasteLLM's effectiveness, we propose the Context-Parameter Copying Capturing algorithm. Interestingly, this reveals that CopyPasteLLM recalibrates reliance on internal parametric knowledge rather than external knowledge during generation. All codes are available at https://github.com/longyongchao/CopyPasteLLM
Building Coding Agents via Entropy-Enhanced Multi-Turn Preference Optimization
Sep 15, 2025Software engineering presents complex, multi-step challenges for Large Language Models (LLMs), requiring reasoning over large codebases and coordinated tool use. The difficulty of these tasks is exemplified by benchmarks like SWE-bench, where current LLMs still struggle to resolve real-world issues. A promising approach to enhance performance is test-time scaling (TTS), but its gains are heavily dependent on the diversity of model outputs. While standard alignment methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) are effective at aligning model outputs with human preferences, this process can come at the cost of reduced diversity, limiting the effectiveness of TTS. Additionally, existing preference optimization algorithms are typically designed for single-turn tasks and do not fully address the complexities of multi-turn reasoning and tool integration required for interactive coding agents. To bridge this gap, we introduce \sys, an entropy-enhanced framework that adapts existing preference optimization algorithms to the multi-turn, tool-assisted setting. \sys augments the preference objective to explicitly preserve policy entropy and generalizes learning to optimize over multi-turn interactions rather than single-turn responses. We validate \sys by fine-tuning a diverse suite of models from different families and sizes (up to 106B parameters). To maximize performance gains from TTS, we further propose a hybrid best-trajectory selection scheme combining a learned verifier model with model free approaches. On the \swebench leaderboard, our approach establishes new state-of-the-art results among open-weight models. A 30B parameter model trained with \sys ranks 1st on \lite and 4th on \verified on the open-weight leaderboard, surpassed only by models with over 10x more parameters(\eg$>$350B).
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Model Merging for Knowledge Editing
Jun 14, 2025Large Language Models (LLMs) require continuous updates to maintain accurate and current knowledge as the world evolves. While existing knowledge editing approaches offer various solutions for knowledge updating, they often struggle with sequential editing scenarios and harm the general capabilities of the model, thereby significantly hampering their practical applicability. This paper proposes a two-stage framework combining robust supervised fine-tuning (R-SFT) with model merging for knowledge editing. Our method first fine-tunes the LLM to internalize new knowledge fully, then merges the fine-tuned model with the original foundation model to preserve newly acquired knowledge and general capabilities. Experimental results demonstrate that our approach significantly outperforms existing methods in sequential editing while better preserving the original performance of the model, all without requiring any architectural changes. Code is available at: https://github.com/Applied-Machine-Learning-Lab/MM4KE.
* 11 pages, 3 figures