 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing the Delta: What Do Models Actually Learn from Preference Pairs?
Apr 09, 2026Preference optimization methods such as DPO and KTO are widely used for aligning language models, yet little is understood about what properties of preference data drive downstream reasoning gains. We ask: what aspects of a preference pair improve a reasoning model's performance on general reasoning tasks? We investigate two distinct notions of quality delta in preference data: generator-level delta, arising from the differences in capability between models that generate chosen and rejected reasoning traces, and sample-level delta, arising from differences in judged quality differences within an individual preference pair. To study generator-level delta, we vary the generator's scale and model family, and to study sample-level delta, we employ an LLM-as-a-judge to rate the quality of generated traces along multiple reasoning-quality dimensions. We find that increasing generator-level delta steadily improves performance on out-of-domain reasoning tasks and filtering data by sample-level delta can enable more data-efficient training. Our results suggest a twofold recipe for improving reasoning performance through preference optimization: maximize generator-level delta when constructing preference pairs and exploit sample-level delta to select the most informative training examples.
Building Coding Agents via Entropy-Enhanced Multi-Turn Preference Optimization
Sep 15, 2025Software engineering presents complex, multi-step challenges for Large Language Models (LLMs), requiring reasoning over large codebases and coordinated tool use. The difficulty of these tasks is exemplified by benchmarks like SWE-bench, where current LLMs still struggle to resolve real-world issues. A promising approach to enhance performance is test-time scaling (TTS), but its gains are heavily dependent on the diversity of model outputs. While standard alignment methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) are effective at aligning model outputs with human preferences, this process can come at the cost of reduced diversity, limiting the effectiveness of TTS. Additionally, existing preference optimization algorithms are typically designed for single-turn tasks and do not fully address the complexities of multi-turn reasoning and tool integration required for interactive coding agents. To bridge this gap, we introduce \sys, an entropy-enhanced framework that adapts existing preference optimization algorithms to the multi-turn, tool-assisted setting. \sys augments the preference objective to explicitly preserve policy entropy and generalizes learning to optimize over multi-turn interactions rather than single-turn responses. We validate \sys by fine-tuning a diverse suite of models from different families and sizes (up to 106B parameters). To maximize performance gains from TTS, we further propose a hybrid best-trajectory selection scheme combining a learned verifier model with model free approaches. On the \swebench leaderboard, our approach establishes new state-of-the-art results among open-weight models. A 30B parameter model trained with \sys ranks 1st on \lite and 4th on \verified on the open-weight leaderboard, surpassed only by models with over 10x more parameters(\eg$>$350B).
A Survey on Explainable Deep Reinforcement Learning
Feb 08, 2025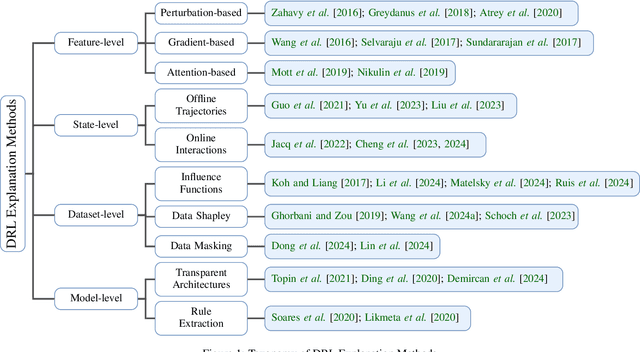

Deep Reinforcement Learning (DRL) has achieved remarkable success in sequential decision-making tasks across diverse domains, yet its reliance on black-box neural architectures hinders interpretability, trust, and deployment in high-stakes applications. Explainable Deep Reinforcement Learning (XRL) addresses these challenges by enhancing transparency through feature-level, state-level, dataset-level, and model-level explanation techniques. This survey provides a comprehensive review of XRL methods, evaluates their qualitative and quantitative assessment frameworks, and explores their role in policy refinement, adversarial robustness, and security. Additionally, we examine the integration of reinforcement learning with Large Language Models (LLMs), particularly through Reinforcement Learning from Human Feedback (RLHF), which optimizes AI alignment with human preferences. We conclude by highlighting open research challenges and future directions to advance the development of interpretable, reliable, and accountable DRL systems.
Soft-Label Integration for Robust Toxicity Classification
Oct 18, 2024



Toxicity classification in textual content remains a significant problem. Data with labels from a single annotator fall short of capturing the diversity of human perspectives. Therefore, there is a growing need to incorporate crowdsourced annotations for training an effective toxicity classifier. Additionally, the standard approach to training a classifier using empirical risk minimization (ERM) may fail to address the potential shifts between the training set and testing set due to exploiting spurious correlations. This work introduces a novel bi-level optimization framework that integrates crowdsourced annotations with the soft-labeling technique and optimizes the soft-label weights by Group Distributionally Robust Optimization (GroupDRO) to enhance the robustness against out-of-distribution (OOD) risk. We theoretically prove the convergence of our bi-level optimization algorithm. Experimental results demonstrate that our approach outperforms existing baseline methods in terms of both average and worst-group accuracy, confirming its effectiveness in leveraging crowdsourced annotations to achieve more effective and robust toxicity classification.
RICE: Breaking Through the Training Bottlenecks of Reinforcement Learning with Explanation
May 05, 2024



Deep reinforcement learning (DRL) is playing an increasingly important role in real-world applications. However, obtaining an optimally performing DRL agent for complex tasks, especially with sparse rewards, remains a significant challenge. The training of a DRL agent can be often trapped in a bottleneck without further progress. In this paper, we propose RICE, an innovative refining scheme for reinforcement learning that incorporates explanation methods to break through the training bottlenecks. The high-level idea of RICE is to construct a new initial state distribution that combines both the default initial states and critical states identified through explanation methods, thereby encouraging the agent to explore from the mixed initial states. Through careful design, we can theoretically guarantee that our refining scheme has a tighter sub-optimality bound. We evaluate RICE in various popular RL environments and real-world applications. The results demonstrate that RICE significantly outperforms existing refining schemes in enhancing agent performance.
Mitigating Query-Flooding Parameter Duplication Attack on Regression Models with High-Dimensional Gaussian Mechanism
Feb 06, 2020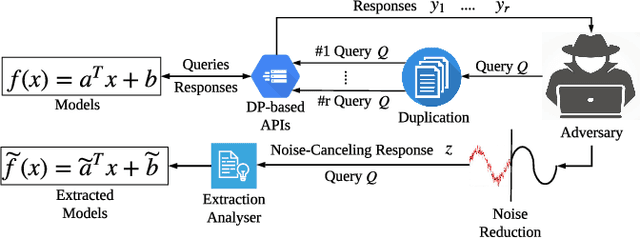
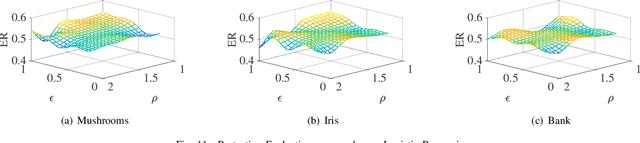
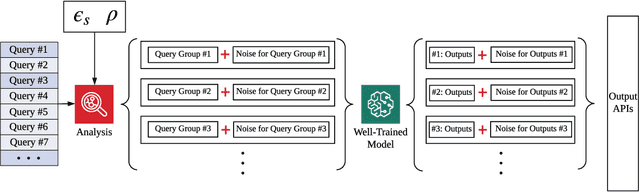
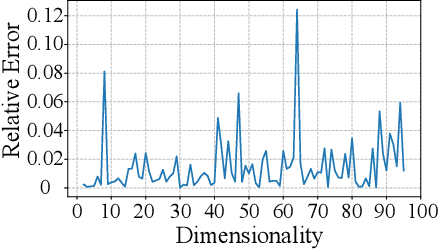
Public intelligent services enabled by machine learning algorithms are vulnerable to model extraction attacks that can steal confidential information of the learning models through public queries. Differential privacy (DP) has been considered a promising technique to mitigate this attack. However, we find that the vulnerability persists when regression models are being protected by current DP solutions. We show that the adversary can launch a query-flooding parameter duplication (QPD) attack to infer the model information by repeated queries. To defend against the QPD attack on logistic and linear regression models, we propose a novel High-Dimensional Gaussian (HDG) mechanism to prevent unauthorized information disclosure without interrupting the intended services. In contrast to prior work, the proposed HDG mechanism will dynamically generate the privacy budget and random noise for different queries and their results to enhance the obfuscation. Besides, for the first time, HDG enables an optimal privacy budget allocation that automatically determines the minimum amount of noise to be added per user-desired privacy level on each dimension. We comprehensively evaluate the performance of HDG using real-world datasets and shows that HDG effectively mitigates the QPD attack while satisfying the privacy requirements. We also prepare to open-source the relevant codes to the community for further research.