 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Explainable Deep Reinforcement Learning
Paper and Code
Feb 08, 2025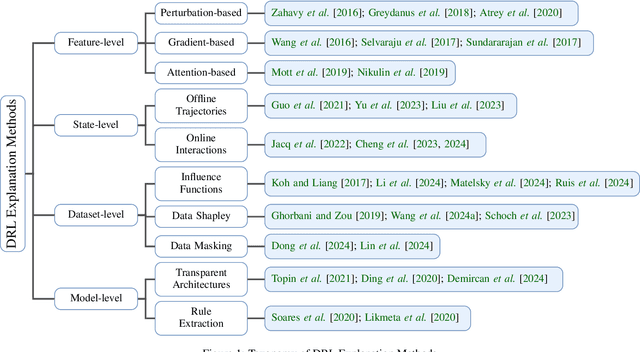

Deep Reinforcement Learning (DRL) has achieved remarkable success in sequential decision-making tasks across diverse domains, yet its reliance on black-box neural architectures hinders interpretability, trust, and deployment in high-stakes applications. Explainable Deep Reinforcement Learning (XRL) addresses these challenges by enhancing transparency through feature-level, state-level, dataset-level, and model-level explanation techniques. This survey provides a comprehensive review of XRL methods, evaluates their qualitative and quantitative assessment frameworks, and explores their role in policy refinement, adversarial robustness, and security. Additionally, we examine the integration of reinforcement learning with Large Language Models (LLMs), particularly through Reinforcement Learning from Human Feedback (RLHF), which optimizes AI alignment with human preferences. We conclude by highlighting open research challenges and future directions to advance the development of interpretable, reliable, and accountable DRL systems.