 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Reasoning Alignment: Reinforcement Learning from Hidden Representations
Mar 18, 2026We propose CRAFT, a red-teaming alignment framework that leverages model reasoning capabilities and hidden representations to improve robustness against jailbreak attacks. Unlike prior defenses that operate primarily at the output level, CRAFT aligns large reasoning models to generate safety-aware reasoning traces by explicitly optimizing objectives defined over the hidden state space. Methodologically, CRAFT integrates contrastive representation learning with reinforcement learning to separate safe and unsafe reasoning trajectories, yielding a latent-space geometry that supports robust, reasoning-level safety alignment. Theoretically, we show that incorporating latent-textual consistency into GRPO eliminates superficially aligned policies by ruling them out as local optima. Empirically, we evaluate CRAFT on multiple safety benchmarks using two strong reasoning models, Qwen3-4B-Thinking and R1-Distill-Llama-8B, where it consistently outperforms state-of-the-art defenses such as IPO and SafeKey. Notably, CRAFT delivers an average 79.0% improvement in reasoning safety and 87.7% improvement in final-response safety over the base models, demonstrating the effectiveness of hidden-space reasoning alignment.
ICON: Intent-Context Coupling for Efficient Multi-Turn Jailbreak Attack
Jan 28, 2026Multi-turn jailbreak attacks have emerged as a critical threat to Large Language Models (LLMs), bypassing safety mechanisms by progressively constructing adversarial contexts from scratch and incrementally refining prompts. However, existing methods suffer from the inefficiency of incremental context construction that requires step-by-step LLM interaction, and often stagnate in suboptimal regions due to surface-level optimization. In this paper, we characterize the Intent-Context Coupling phenomenon, revealing that LLM safety constraints are significantly relaxed when a malicious intent is coupled with a semantically congruent context pattern. Driven by this insight, we propose ICON, an automated multi-turn jailbreak framework that efficiently constructs an authoritative-style context via prior-guided semantic routing. Specifically, ICON first routes the malicious intent to a congruent context pattern (e.g., Scientific Research) and instantiates it into an attack prompt sequence. This sequence progressively builds the authoritative-style context and ultimately elicits prohibited content. In addition, ICON incorporates a Hierarchical Optimization Strategy that combines local prompt refinement with global context switching, preventing the attack from stagnating in ineffective contexts. Experimental results across eight SOTA LLMs demonstrate the effectiveness of ICON, achieving a state-of-the-art average Attack Success Rate (ASR) of 97.1\%. Code is available at https://github.com/xwlin-roy/ICON.
CSCBench: A PVC Diagnostic Benchmark for Commodity Supply Chain Reasoning
Jan 05, 2026Large Language Models (LLMs) have achieved remarkable success in general benchmarks, yet their competence in commodity supply chains (CSCs) -- a domain governed by institutional rule systems and feasibility constraints -- remains under-explored. CSC decisions are shaped jointly by process stages (e.g., planning, procurement, delivery), variety-specific rules (e.g., contract specifications and delivery grades), and reasoning depth (from retrieval to multi-step analysis and decision selection). We introduce CSCBench, a 2.3K+ single-choice benchmark for CSC reasoning, instantiated through our PVC 3D Evaluation Framework (Process, Variety, and Cognition). The Process axis aligns tasks with SCOR+Enable; the Variety axis operationalizes commodity-specific rule systems under coupled material-information-financial constraints, grounded in authoritative exchange guidebooks/rulebooks and industry reports; and the Cognition axis follows Bloom's revised taxonomy. Evaluating representative LLMs under a direct prompting setting, we observe strong performance on the Process and Cognition axes but substantial degradation on the Variety axis, especially on Freight Agreements. CSCBench provides a diagnostic yardstick for measuring and improving LLM capabilities in this high-stakes domain.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
Building Coding Agents via Entropy-Enhanced Multi-Turn Preference Optimization
Sep 15, 2025Software engineering presents complex, multi-step challenges for Large Language Models (LLMs), requiring reasoning over large codebases and coordinated tool use. The difficulty of these tasks is exemplified by benchmarks like SWE-bench, where current LLMs still struggle to resolve real-world issues. A promising approach to enhance performance is test-time scaling (TTS), but its gains are heavily dependent on the diversity of model outputs. While standard alignment methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) are effective at aligning model outputs with human preferences, this process can come at the cost of reduced diversity, limiting the effectiveness of TTS. Additionally, existing preference optimization algorithms are typically designed for single-turn tasks and do not fully address the complexities of multi-turn reasoning and tool integration required for interactive coding agents. To bridge this gap, we introduce \sys, an entropy-enhanced framework that adapts existing preference optimization algorithms to the multi-turn, tool-assisted setting. \sys augments the preference objective to explicitly preserve policy entropy and generalizes learning to optimize over multi-turn interactions rather than single-turn responses. We validate \sys by fine-tuning a diverse suite of models from different families and sizes (up to 106B parameters). To maximize performance gains from TTS, we further propose a hybrid best-trajectory selection scheme combining a learned verifier model with model free approaches. On the \swebench leaderboard, our approach establishes new state-of-the-art results among open-weight models. A 30B parameter model trained with \sys ranks 1st on \lite and 4th on \verified on the open-weight leaderboard, surpassed only by models with over 10x more parameters(\eg$>$350B).
TranSUN: A Preemptive Paradigm to Eradicate Retransformation Bias Intrinsically from Regression Models in Recommender Systems
May 20, 2025



Regression models are crucial in recommender systems. However, retransformation bias problem has been conspicuously neglected within the community. While many works in other fields have devised effective bias correction methods, all of them are post-hoc cures externally to the model, facing practical challenges when applied to real-world recommender systems. Hence, we propose a preemptive paradigm to eradicate the bias intrinsically from the models via minor model refinement. Specifically, a novel TranSUN method is proposed with a joint bias learning manner to offer theoretically guaranteed unbiasedness under empirical superior convergence. It is further generalized into a novel generic regression model family, termed Generalized TranSUN (GTS), which not only offers more theoretical insights but also serves as a generic framework for flexibly developing various bias-free models. Comprehensive experimental results demonstrate the superiority of our methods across data from various domains, which have been successfully deployed in two real-world industrial recommendation scenarios, i.e. product and short video recommendation scenarios in Guess What You Like business domain in the homepage of Taobao App (a leading e-commerce platform), to serve the major online traffic. Codes will be released after this paper is published.
GenoArmory: A Unified Evaluation Framework for Adversarial Attacks on Genomic Foundation Models
May 16, 2025

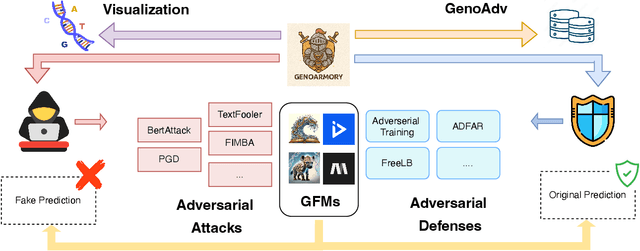

We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GenoArmory. Unlike existing GFM benchmarks, GenoArmory offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Additionally, we introduce GenoAdv, a new adversarial sample dataset designed to improve GFM safety. Empirically, classification models exhibit greater robustness to adversarial perturbations compared to generative models, highlighting the impact of task type on model vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
Missing Data Imputation by Reducing Mutual Information with Rectified Flows
May 16, 2025This paper introduces a novel iterative method for missing data imputation that sequentially reduces the mutual information between data and their corresponding missing mask. Inspired by GAN-based approaches, which train generators to decrease the predictability of missingness patterns, our method explicitly targets the reduction of mutual information. Specifically, our algorithm iteratively minimizes the KL divergence between the joint distribution of the imputed data and missing mask, and the product of their marginals from the previous iteration. We show that the optimal imputation under this framework corresponds to solving an ODE, whose velocity field minimizes a rectified flow training objective. We further illustrate that some existing imputation techniques can be interpreted as approximate special cases of our mutual-information-reducing framework. Comprehensive experiments on synthetic and real-world datasets validate the efficacy of our proposed approach, demonstrating superior imputation performance.
The Illusion of Role Separation: Hidden Shortcuts in LLM Role Learning (and How to Fix Them)
May 01, 2025Large language models (LLMs) that integrate multiple input roles (e.g., system instructions, user queries, external tool outputs) are increasingly prevalent in practice. Ensuring that the model accurately distinguishes messages from each role -- a concept we call \emph{role separation} -- is crucial for consistent multi-role behavior. Although recent work often targets state-of-the-art prompt injection defenses, it remains unclear whether such methods truly teach LLMs to differentiate roles or merely memorize known triggers. In this paper, we examine \emph{role-separation learning}: the process of teaching LLMs to robustly distinguish system and user tokens. Through a \emph{simple, controlled experimental framework}, we find that fine-tuned models often rely on two proxies for role identification: (1) task type exploitation, and (2) proximity to begin-of-text. Although data augmentation can partially mitigate these shortcuts, it generally leads to iterative patching rather than a deeper fix. To address this, we propose reinforcing \emph{invariant signals} that mark role boundaries by adjusting token-wise cues in the model's input encoding. In particular, manipulating position IDs helps the model learn clearer distinctions and reduces reliance on superficial proxies. By focusing on this mechanism-centered perspective, our work illuminates how LLMs can more reliably maintain consistent multi-role behavior without merely memorizing known prompts or triggers.
A Survey on Explainable Deep Reinforcement Learning
Feb 08, 2025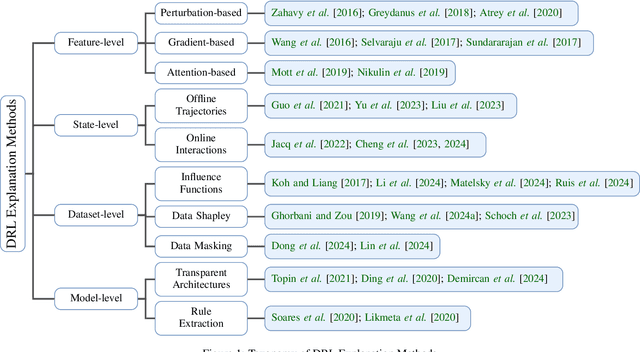

Deep Reinforcement Learning (DRL) has achieved remarkable success in sequential decision-making tasks across diverse domains, yet its reliance on black-box neural architectures hinders interpretability, trust, and deployment in high-stakes applications. Explainable Deep Reinforcement Learning (XRL) addresses these challenges by enhancing transparency through feature-level, state-level, dataset-level, and model-level explanation techniques. This survey provides a comprehensive review of XRL methods, evaluates their qualitative and quantitative assessment frameworks, and explores their role in policy refinement, adversarial robustness, and security. Additionally, we examine the integration of reinforcement learning with Large Language Models (LLMs), particularly through Reinforcement Learning from Human Feedback (RLHF), which optimizes AI alignment with human preferences. We conclude by highlighting open research challenges and future directions to advance the development of interpretable, reliable, and accountable DRL systems.