 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Role Separation: Hidden Shortcuts in LLM Role Learning (and How to Fix Them)
May 01, 2025Large language models (LLMs) that integrate multiple input roles (e.g., system instructions, user queries, external tool outputs) are increasingly prevalent in practice. Ensuring that the model accurately distinguishes messages from each role -- a concept we call \emph{role separation} -- is crucial for consistent multi-role behavior. Although recent work often targets state-of-the-art prompt injection defenses, it remains unclear whether such methods truly teach LLMs to differentiate roles or merely memorize known triggers. In this paper, we examine \emph{role-separation learning}: the process of teaching LLMs to robustly distinguish system and user tokens. Through a \emph{simple, controlled experimental framework}, we find that fine-tuned models often rely on two proxies for role identification: (1) task type exploitation, and (2) proximity to begin-of-text. Although data augmentation can partially mitigate these shortcuts, it generally leads to iterative patching rather than a deeper fix. To address this, we propose reinforcing \emph{invariant signals} that mark role boundaries by adjusting token-wise cues in the model's input encoding. In particular, manipulating position IDs helps the model learn clearer distinctions and reduces reliance on superficial proxies. By focusing on this mechanism-centered perspective, our work illuminates how LLMs can more reliably maintain consistent multi-role behavior without merely memorizing known prompts or triggers.
LLMs in Software Security: A Survey of Vulnerability Detection Techniques and Insights
Feb 12, 2025Large Language Models (LLMs) are emerging as transformative tools for software vulnerability detection, addressing critical challenges in the security domain. Traditional methods, such as static and dynamic analysis, often falter due to inefficiencies, high false positive rates, and the growing complexity of modern software systems. By leveraging their ability to analyze code structures, identify patterns, and generate repair sugges- tions, LLMs, exemplified by models like GPT, BERT, and CodeBERT, present a novel and scalable approach to mitigating vulnerabilities. This paper provides a detailed survey of LLMs in vulnerability detection. It examines key aspects, including model architectures, application methods, target languages, fine-tuning strategies, datasets, and evaluation metrics. We also analyze the scope of current research problems, highlighting the strengths and weaknesses of existing approaches. Further, we address challenges such as cross-language vulnerability detection, multimodal data integration, and repository-level analysis. Based on these findings, we propose solutions for issues like dataset scalability, model interpretability, and applications in low-resource scenarios. Our contributions are threefold: (1) a systematic review of how LLMs are applied in vulnerability detection; (2) an analysis of shared patterns and differences across studies, with a unified framework for understanding the field; and (3) a summary of key challenges and future research directions. This work provides valuable insights for advancing LLM-based vulnerability detection. We also maintain and regularly update latest selected paper on https://github.com/OwenSanzas/LLM-For-Vulnerability-Detection
Large Language Models in Software Security: A Survey of Vulnerability Detection Techniques and Insights
Feb 10, 2025Large Language Models (LLMs) are emerging as transformative tools for software vulnerability detection, addressing critical challenges in the security domain. Traditional methods, such as static and dynamic analysis, often falter due to inefficiencies, high false positive rates, and the growing complexity of modern software systems. By leveraging their ability to analyze code structures, identify patterns, and generate repair sugges- tions, LLMs, exemplified by models like GPT, BERT, and CodeBERT, present a novel and scalable approach to mitigating vulnerabilities. This paper provides a detailed survey of LLMs in vulnerability detection. It examines key aspects, including model architectures, application methods, target languages, fine-tuning strategies, datasets, and evaluation metrics. We also analyze the scope of current research problems, highlighting the strengths and weaknesses of existing approaches. Further, we address challenges such as cross-language vulnerability detection, multimodal data integration, and repository-level analysis. Based on these findings, we propose solutions for issues like dataset scalability, model interpretability, and applications in low-resource scenarios. Our contributions are threefold: (1) a systematic review of how LLMs are applied in vulnerability detection; (2) an analysis of shared patterns and differences across studies, with a unified framework for understanding the field; and (3) a summary of key challenges and future research directions. This work provides valuable insights for advancing LLM-based vulnerability detection. We also maintain and regularly update latest selected paper on https://github.com/OwenSanzas/LLM-For-Vulnerability-Detection
Combining Supervised and Un-supervised Learning for Automatic Citrus Segmentation
May 04, 2021
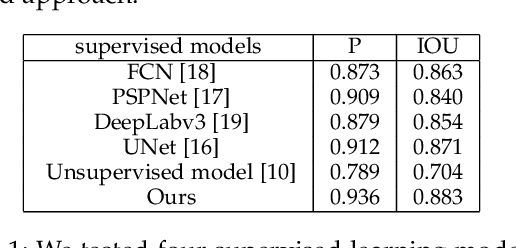


Citrus segmentation is a key step of automatic citrus picking. While most current image segmentation approaches achieve good segmentation results by pixel-wise segmentation, these supervised learning-based methods require a large amount of annotated data, and do not consider the continuous temporal changes of citrus position in real-world applications. In this paper, we first train a simple CNN with a small number of labelled citrus images in a supervised manner, which can roughly predict the citrus location from each frame. Then, we extend a state-of-the-art unsupervised learning approach to pre-learn the citrus's potential movements between frames from unlabelled citrus's videos. To take advantages of both networks, we employ the multimodal transformer to combine supervised learned static information and unsupervised learned movement information. The experimental results show that combing both network allows the prediction accuracy reached at 88.3$\%$ IOU and 93.6$\%$ precision, outperforming the original supervised baseline 1.2$\%$ and 2.4$\%$. Compared with most of the existing citrus segmentation methods, our method uses a small amount of supervised data and a large number of unsupervised data, while learning the pixel level location information and the temporal information of citrus changes to enhance the segmentation effect.
Reaching Data Confidentiality and Model Accountability on the CalTrain
Dec 07, 2018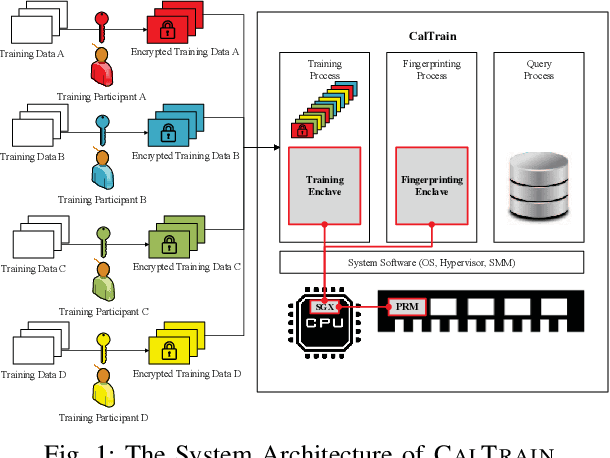
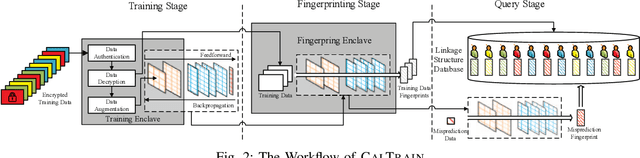

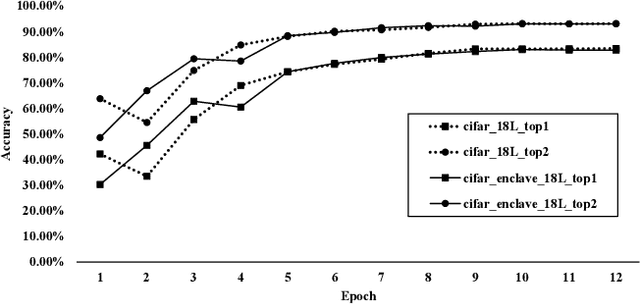
Distributed collaborative learning (DCL) paradigms enable building joint machine learning models from distrusting multi-party participants. Data confidentiality is guaranteed by retaining private training data on each participant's local infrastructure. However, this approach to achieving data confidentiality makes today's DCL designs fundamentally vulnerable to data poisoning and backdoor attacks. It also limits DCL's model accountability, which is key to backtracking the responsible "bad" training data instances/contributors. In this paper, we introduce CALTRAIN, a Trusted Execution Environment (TEE) based centralized multi-party collaborative learning system that simultaneously achieves data confidentiality and model accountability. CALTRAIN enforces isolated computation on centrally aggregated training data to guarantee data confidentiality. To support building accountable learning models, we securely maintain the links between training instances and their corresponding contributors. Our evaluation shows that the models generated from CALTRAIN can achieve the same prediction accuracy when compared to the models trained in non-protected environments. We also demonstrate that when malicious training participants tend to implant backdoors during model training, CALTRAIN can accurately and precisely discover the poisoned and mislabeled training data that lead to the runtime mispredictions.
CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition
Jul 02, 2018
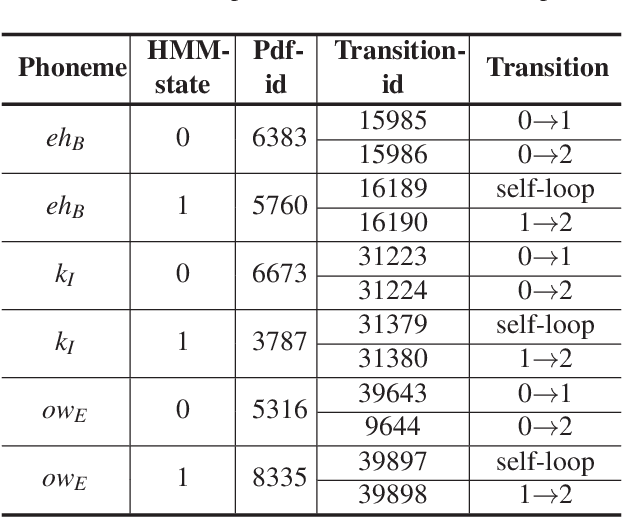

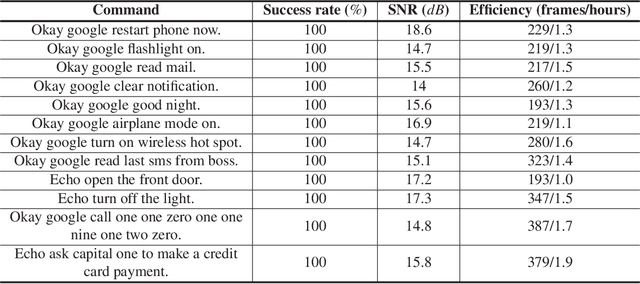
The popularity of ASR (automatic speech recognition) systems, like Google Voice, Cortana, brings in security concerns, as demonstrated by recent attacks. The impacts of such threats, however, are less clear, since they are either less stealthy (producing noise-like voice commands) or requiring the physical presence of an attack device (using ultrasound). In this paper, we demonstrate that not only are more practical and surreptitious attacks feasible but they can even be automatically constructed. Specifically, we find that the voice commands can be stealthily embedded into songs, which, when played, can effectively control the target system through ASR without being noticed. For this purpose, we developed novel techniques that address a key technical challenge: integrating the commands into a song in a way that can be effectively recognized by ASR through the air, in the presence of background noise, while not being detected by a human listener. Our research shows that this can be done automatically against real world ASR applications. We also demonstrate that such CommanderSongs can be spread through Internet (e.g., YouTube) and radio, potentially affecting millions of ASR users. We further present a new mitigation technique that controls this threat.