 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-powered Covert Botnet Command and Control on OSNs
Sep 22, 2020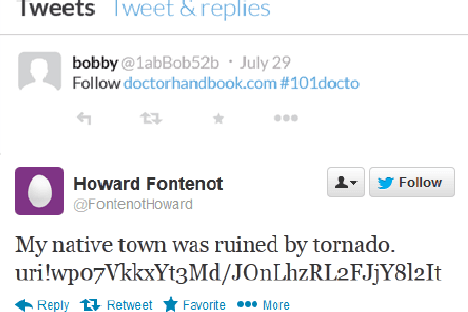
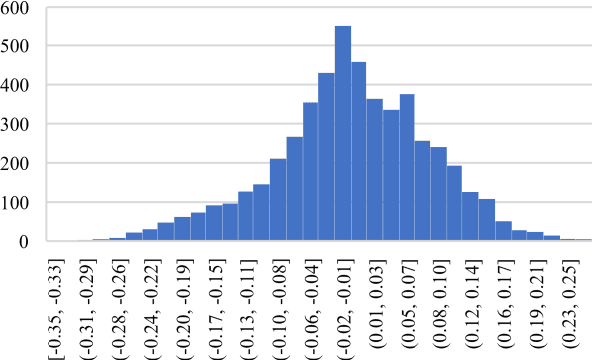

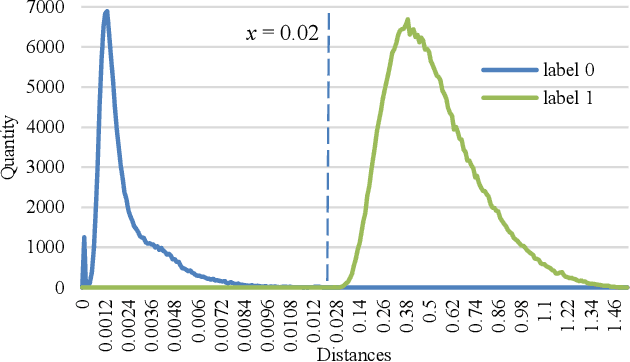
Botnet is one of the major threats to computer security. In previous botnet command and control (C&C) scenarios using online social networks (OSNs), methods for finding botmasters (e.g. ids, links, DGAs, etc.) are hardcoded into bots. Once a bot is reverse engineered, botmaster is exposed. Meanwhile, abnormal contents from explicit commands may expose botmaster and raise anomalies on OSNs. To overcome these deficiencies, we propose an AI-powered covert C&C channel. On leverage of neural networks, bots can find botmasters by avatars, which are converted into feature vectors. Commands are embedded into normal contents (e.g. tweets, comments, etc.) using text data augmentation and hash collision. Experiment on Twitter shows that the command-embedded contents can be generated efficiently, and bots can find botmaster and obtain commands accurately. By demonstrating how AI may help promote a covert communication on OSNs, this work provides a new perspective on botnet detection and confrontation.
Reaching Data Confidentiality and Model Accountability on the CalTrain
Dec 07, 2018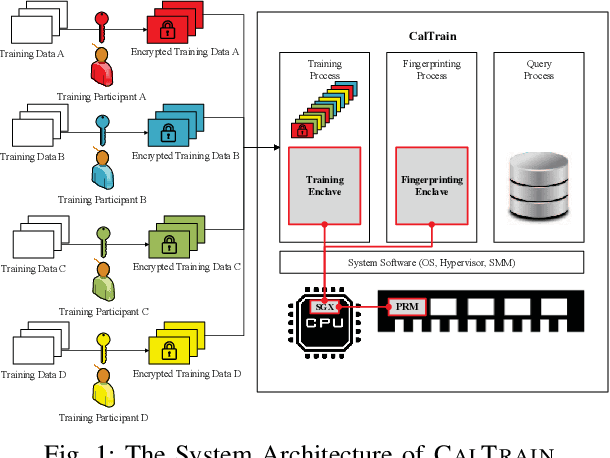
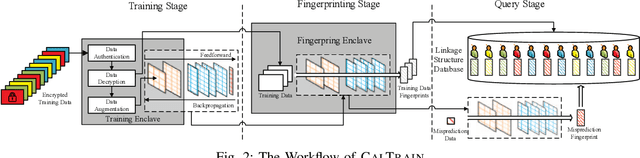

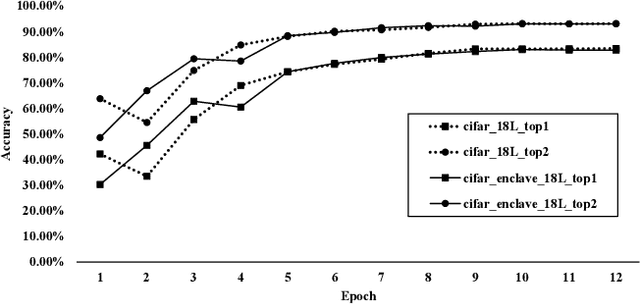
Distributed collaborative learning (DCL) paradigms enable building joint machine learning models from distrusting multi-party participants. Data confidentiality is guaranteed by retaining private training data on each participant's local infrastructure. However, this approach to achieving data confidentiality makes today's DCL designs fundamentally vulnerable to data poisoning and backdoor attacks. It also limits DCL's model accountability, which is key to backtracking the responsible "bad" training data instances/contributors. In this paper, we introduce CALTRAIN, a Trusted Execution Environment (TEE) based centralized multi-party collaborative learning system that simultaneously achieves data confidentiality and model accountability. CALTRAIN enforces isolated computation on centrally aggregated training data to guarantee data confidentiality. To support building accountable learning models, we securely maintain the links between training instances and their corresponding contributors. Our evaluation shows that the models generated from CALTRAIN can achieve the same prediction accuracy when compared to the models trained in non-protected environments. We also demonstrate that when malicious training participants tend to implant backdoors during model training, CALTRAIN can accurately and precisely discover the poisoned and mislabeled training data that lead to the runtime mispredictions.