 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparation of Powers in Federated Learning
May 19, 2021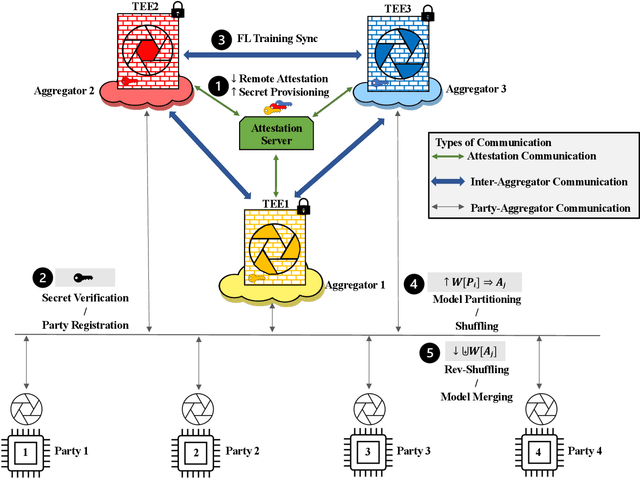
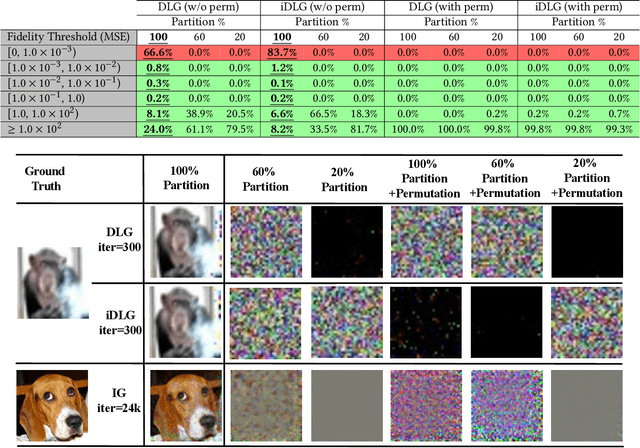
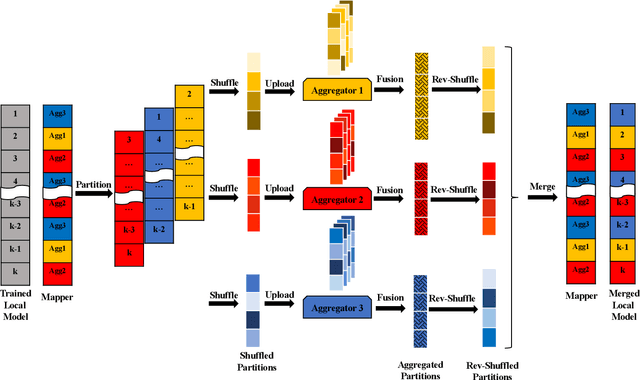

Federated Learning (FL) enables collaborative training among mutually distrusting parties. Model updates, rather than training data, are concentrated and fused in a central aggregation server. A key security challenge in FL is that an untrustworthy or compromised aggregation process might lead to unforeseeable information leakage. This challenge is especially acute due to recently demonstrated attacks that have reconstructed large fractions of training data from ostensibly "sanitized" model updates. In this paper, we introduce TRUDA, a new cross-silo FL system, employing a trustworthy and decentralized aggregation architecture to break down information concentration with regard to a single aggregator. Based on the unique computational properties of model-fusion algorithms, all exchanged model updates in TRUDA are disassembled at the parameter-granularity and re-stitched to random partitions designated for multiple TEE-protected aggregators. Thus, each aggregator only has a fragmentary and shuffled view of model updates and is oblivious to the model architecture. Our new security mechanisms can fundamentally mitigate training reconstruction attacks, while still preserving the final accuracy of trained models and keeping performance overheads low.
Reaching Data Confidentiality and Model Accountability on the CalTrain
Dec 07, 2018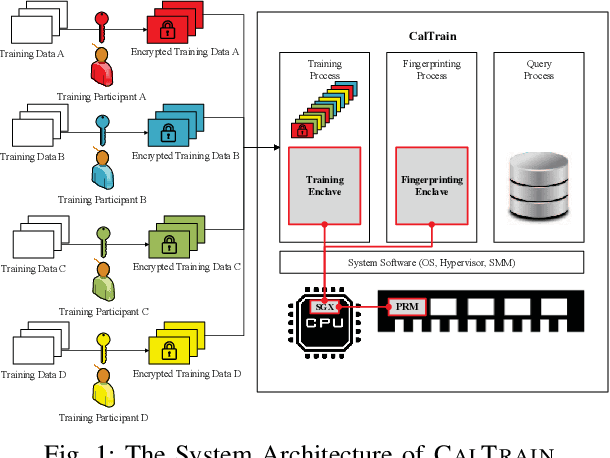
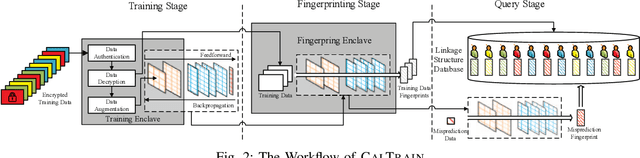

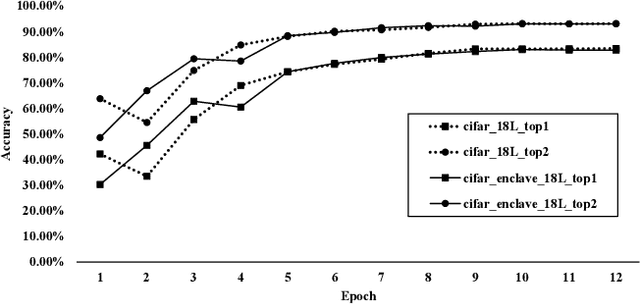
Distributed collaborative learning (DCL) paradigms enable building joint machine learning models from distrusting multi-party participants. Data confidentiality is guaranteed by retaining private training data on each participant's local infrastructure. However, this approach to achieving data confidentiality makes today's DCL designs fundamentally vulnerable to data poisoning and backdoor attacks. It also limits DCL's model accountability, which is key to backtracking the responsible "bad" training data instances/contributors. In this paper, we introduce CALTRAIN, a Trusted Execution Environment (TEE) based centralized multi-party collaborative learning system that simultaneously achieves data confidentiality and model accountability. CALTRAIN enforces isolated computation on centrally aggregated training data to guarantee data confidentiality. To support building accountable learning models, we securely maintain the links between training instances and their corresponding contributors. Our evaluation shows that the models generated from CALTRAIN can achieve the same prediction accuracy when compared to the models trained in non-protected environments. We also demonstrate that when malicious training participants tend to implant backdoors during model training, CALTRAIN can accurately and precisely discover the poisoned and mislabeled training data that lead to the runtime mispredictions.