 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciSafeEval: A Comprehensive Benchmark for Safety Alignment of Large Language Models in Scientific Tasks
Oct 02, 2024



Large language models (LLMs) have had a transformative impact on a variety of scientific tasks across disciplines such as biology, chemistry, medicine, and physics. However, ensuring the safety alignment of these models in scientific research remains an underexplored area, with existing benchmarks primarily focus on textual content and overlooking key scientific representations such as molecular, protein, and genomic languages. Moreover, the safety mechanisms of LLMs in scientific tasks are insufficiently studied. To address these limitations, we introduce SciSafeEval, a comprehensive benchmark designed to evaluate the safety alignment of LLMs across a range of scientific tasks. SciSafeEval spans multiple scientific languages - including textual, molecular, protein, and genomic - and covers a wide range of scientific domains. We evaluate LLMs in zero-shot, few-shot and chain-of-thought settings, and introduce a 'jailbreak' enhancement feature that challenges LLMs equipped with safety guardrails, rigorously testing their defenses against malicious intention. Our benchmark surpasses existing safety datasets in both scale and scope, providing a robust platform for assessing the safety and performance of LLMs in scientific contexts. This work aims to facilitate the responsible development and deployment of LLMs, promoting alignment with safety and ethical standards in scientific research.
SoK: A Modularized Approach to Study the Security of Automatic Speech Recognition Systems
Mar 19, 2021
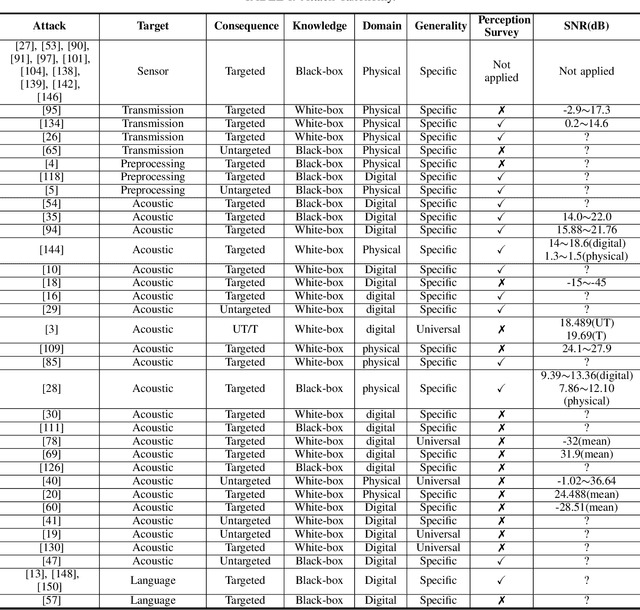

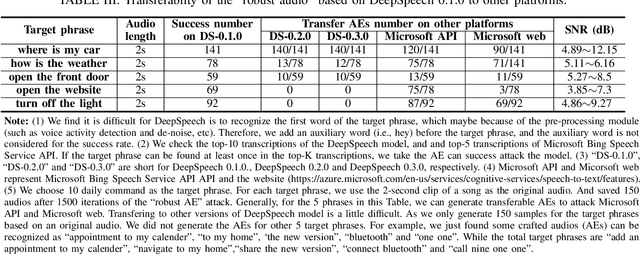
With the wide use of Automatic Speech Recognition (ASR) in applications such as human machine interaction, simultaneous interpretation, audio transcription, etc., its security protection becomes increasingly important. Although recent studies have brought to light the weaknesses of popular ASR systems that enable out-of-band signal attack, adversarial attack, etc., and further proposed various remedies (signal smoothing, adversarial training, etc.), a systematic understanding of ASR security (both attacks and defenses) is still missing, especially on how realistic such threats are and how general existing protection could be. In this paper, we present our systematization of knowledge for ASR security and provide a comprehensive taxonomy for existing work based on a modularized workflow. More importantly, we align the research in this domain with that on security in Image Recognition System (IRS), which has been extensively studied, using the domain knowledge in the latter to help understand where we stand in the former. Generally, both IRS and ASR are perceptual systems. Their similarities allow us to systematically study existing literature in ASR security based on the spectrum of attacks and defense solutions proposed for IRS, and pinpoint the directions of more advanced attacks and the directions potentially leading to more effective protection in ASR. In contrast, their differences, especially the complexity of ASR compared with IRS, help us learn unique challenges and opportunities in ASR security. Particularly, our experimental study shows that transfer learning across ASR models is feasible, even in the absence of knowledge about models (even their types) and training data.
CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition
Jul 02, 2018

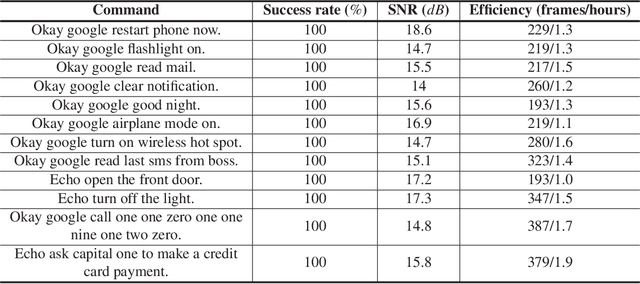
The popularity of ASR (automatic speech recognition) systems, like Google Voice, Cortana, brings in security concerns, as demonstrated by recent attacks. The impacts of such threats, however, are less clear, since they are either less stealthy (producing noise-like voice commands) or requiring the physical presence of an attack device (using ultrasound). In this paper, we demonstrate that not only are more practical and surreptitious attacks feasible but they can even be automatically constructed. Specifically, we find that the voice commands can be stealthily embedded into songs, which, when played, can effectively control the target system through ASR without being noticed. For this purpose, we developed novel techniques that address a key technical challenge: integrating the commands into a song in a way that can be effectively recognized by ASR through the air, in the presence of background noise, while not being detected by a human listener. Our research shows that this can be done automatically against real world ASR applications. We also demonstrate that such CommanderSongs can be spread through Internet (e.g., YouTube) and radio, potentially affecting millions of ASR users. We further present a new mitigation technique that controls this threat.