 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens Are Created Equal: Query-Efficient Jailbreak Fuzzing for LLMs
Mar 24, 2026Large Language Models(LLMs) are widely deployed, yet are vulnerable to jailbreak prompts that elicit policy-violating outputs. Although prior studies have uncovered these risks, they typically treat all tokens as equally important during prompt mutation, overlooking the varying contributions of individual tokens to triggering model refusals. Consequently, these attacks introduce substantial redundant searching under query-constrained scenarios, reducing attack efficiency and hindering comprehensive vulnerability assessment. In this work, we conduct a token-level analysis of refusal behavior and observe that token contributions are highly skewed rather than uniform. Moreover, we find strong cross-model consistency in refusal tendencies, enabling the use of a surrogate model to estimate token-level contributions to the target model's refusals. Motivated by these findings, we propose TriageFuzz, a token-aware jailbreak fuzzing framework that adapts the fuzz testing approach with a series of customized designs. TriageFuzz leverages a surrogate model to estimate the contribution of individual tokens to refusal behaviors, enabling the identification of sensitive regions within the prompt. Furthermore, it incorporates a refusal-guided evolutionary strategy that adaptively weights candidate prompts with a lightweight scorer to steer the evolution toward bypassing safety constraints. Extensive experiments on six open-source LLMs and three commercial APIs demonstrate that TriageFuzz achieves comparable attack success rates (ASR) with significantly reduced query costs. Notably, it attains a 90% ASR with over 70% fewer queries compared to baselines. Even under an extremely restrictive budget of 25 queries, TriageFuzz outperforms existing methods, improving ASR by 20-40%.
VidLeaks: Membership Inference Attacks Against Text-to-Video Models
Jan 16, 2026The proliferation of powerful Text-to-Video (T2V) models, trained on massive web-scale datasets, raises urgent concerns about copyright and privacy violations. Membership inference attacks (MIAs) provide a principled tool for auditing such risks, yet existing techniques - designed for static data like images or text - fail to capture the spatio-temporal complexities of video generation. In particular, they overlook the sparsity of memorization signals in keyframes and the instability introduced by stochastic temporal dynamics. In this paper, we conduct the first systematic study of MIAs against T2V models and introduce a novel framework VidLeaks, which probes sparse-temporal memorization through two complementary signals: 1) Spatial Reconstruction Fidelity (SRF), using a Top-K similarity to amplify spatial memorization signals from sparsely memorized keyframes, and 2) Temporal Generative Stability (TGS), which measures semantic consistency across multiple queries to capture temporal leakage. We evaluate VidLeaks under three progressively restrictive black-box settings - supervised, reference-based, and query-only. Experiments on three representative T2V models reveal severe vulnerabilities: VidLeaks achieves AUC of 82.92% on AnimateDiff and 97.01% on InstructVideo even in the strict query-only setting, posing a realistic and exploitable privacy risk. Our work provides the first concrete evidence that T2V models leak substantial membership information through both sparse and temporal memorization, establishing a foundation for auditing video generation systems and motivating the development of new defenses. Code is available at: https://zenodo.org/records/17972831.
Jailbreaking Text-to-Image Models with LLM-Based Agents
Aug 01, 2024



Recent advancements have significantly improved automated task-solving capabilities using autonomous agents powered by large language models (LLMs). However, most LLM-based agents focus on dialogue, programming, or specialized domains, leaving gaps in addressing generative AI safety tasks. These gaps are primarily due to the challenges posed by LLM hallucinations and the lack of clear guidelines. In this paper, we propose Atlas, an advanced LLM-based multi-agent framework that integrates an efficient fuzzing workflow to target generative AI models, specifically focusing on jailbreak attacks against text-to-image (T2I) models with safety filters. Atlas utilizes a vision-language model (VLM) to assess whether a prompt triggers the T2I model's safety filter. It then iteratively collaborates with both LLM and VLM to generate an alternative prompt that bypasses the filter. Atlas also enhances the reasoning abilities of LLMs in attack scenarios by leveraging multi-agent communication, in-context learning (ICL) memory mechanisms, and the chain-of-thought (COT) approach. Our evaluation demonstrates that Atlas successfully jailbreaks several state-of-the-art T2I models in a black-box setting, which are equipped with multi-modal safety filters. In addition, Atlas outperforms existing methods in both query efficiency and the quality of the generated images.
AVA: Inconspicuous Attribute Variation-based Adversarial Attack bypassing DeepFake Detection
Dec 14, 2023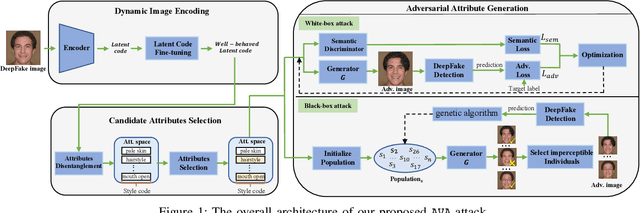
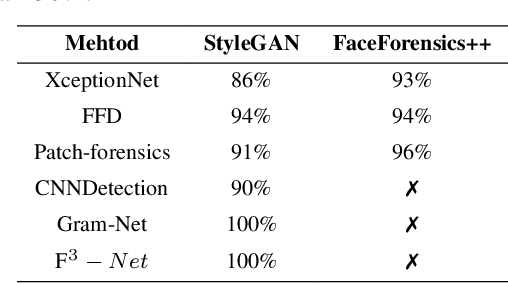
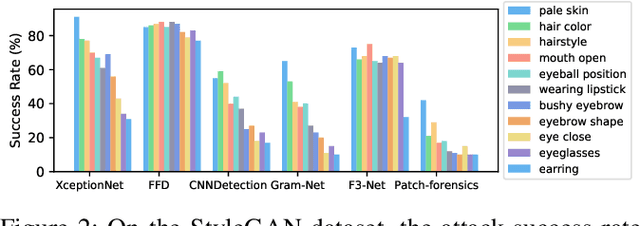

While DeepFake applications are becoming popular in recent years, their abuses pose a serious privacy threat. Unfortunately, most related detection algorithms to mitigate the abuse issues are inherently vulnerable to adversarial attacks because they are built atop DNN-based classification models, and the literature has demonstrated that they could be bypassed by introducing pixel-level perturbations. Though corresponding mitigation has been proposed, we have identified a new attribute-variation-based adversarial attack (AVA) that perturbs the latent space via a combination of Gaussian prior and semantic discriminator to bypass such mitigation. It perturbs the semantics in the attribute space of DeepFake images, which are inconspicuous to human beings (e.g., mouth open) but can result in substantial differences in DeepFake detection. We evaluate our proposed AVA attack on nine state-of-the-art DeepFake detection algorithms and applications. The empirical results demonstrate that AVA attack defeats the state-of-the-art black box attacks against DeepFake detectors and achieves more than a 95% success rate on two commercial DeepFake detectors. Moreover, our human study indicates that AVA-generated DeepFake images are often imperceptible to humans, which presents huge security and privacy concerns.
RNN-Guard: Certified Robustness Against Multi-frame Attacks for Recurrent Neural Networks
Apr 17, 2023It is well-known that recurrent neural networks (RNNs), although widely used, are vulnerable to adversarial attacks including one-frame attacks and multi-frame attacks. Though a few certified defenses exist to provide guaranteed robustness against one-frame attacks, we prove that defending against multi-frame attacks remains a challenging problem due to their enormous perturbation space. In this paper, we propose the first certified defense against multi-frame attacks for RNNs called RNN-Guard. To address the above challenge, we adopt the perturb-all-frame strategy to construct perturbation spaces consistent with those in multi-frame attacks. However, the perturb-all-frame strategy causes a precision issue in linear relaxations. To address this issue, we introduce a novel abstract domain called InterZono and design tighter relaxations. We prove that InterZono is more precise than Zonotope yet carries the same time complexity. Experimental evaluations across various datasets and model structures show that the certified robust accuracy calculated by RNN-Guard with InterZono is up to 2.18 times higher than that with Zonotope. In addition, we extend RNN-Guard as the first certified training method against multi-frame attacks to directly enhance RNNs' robustness. The results show that the certified robust accuracy of models trained with RNN-Guard against multi-frame attacks is 15.47 to 67.65 percentage points higher than those with other training methods.
Seeing is Living? Rethinking the Security of Facial Liveness Verification in the Deepfake Era
Feb 22, 2022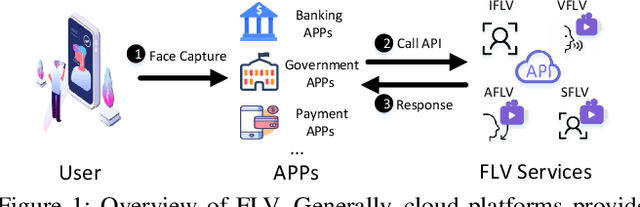
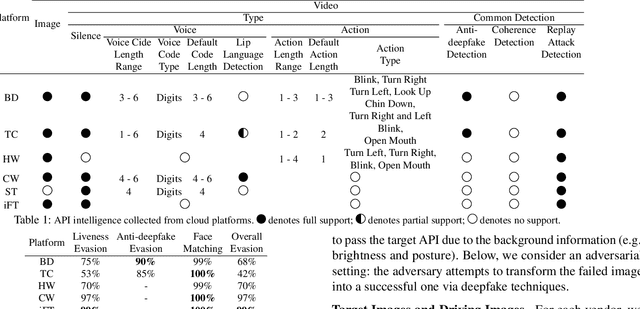
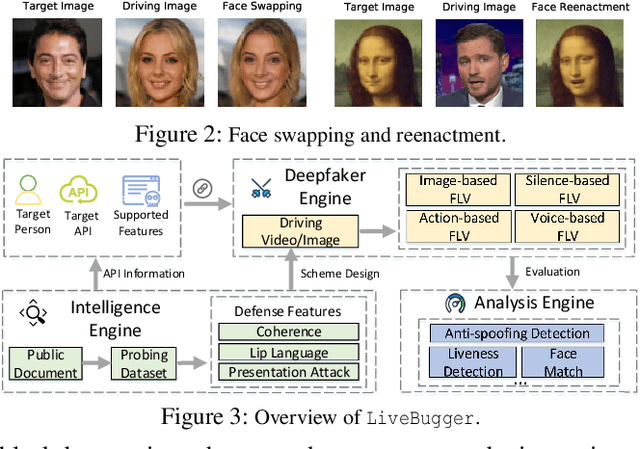

Facial Liveness Verification (FLV) is widely used for identity authentication in many security-sensitive domains and offered as Platform-as-a-Service (PaaS) by leading cloud vendors. Yet, with the rapid advances in synthetic media techniques (e.g., deepfake), the security of FLV is facing unprecedented challenges, about which little is known thus far. To bridge this gap, in this paper, we conduct the first systematic study on the security of FLV in real-world settings. Specifically, we present LiveBugger, a new deepfake-powered attack framework that enables customizable, automated security evaluation of FLV. Leveraging LiveBugger, we perform a comprehensive empirical assessment of representative FLV platforms, leading to a set of interesting findings. For instance, most FLV APIs do not use anti-deepfake detection; even for those with such defenses, their effectiveness is concerning (e.g., it may detect high-quality synthesized videos but fail to detect low-quality ones). We then conduct an in-depth analysis of the factors impacting the attack performance of LiveBugger: a) the bias (e.g., gender or race) in FLV can be exploited to select victims; b) adversarial training makes deepfake more effective to bypass FLV; c) the input quality has a varying influence on different deepfake techniques to bypass FLV. Based on these findings, we propose a customized, two-stage approach that can boost the attack success rate by up to 70%. Further, we run proof-of-concept attacks on several representative applications of FLV (i.e., the clients of FLV APIs) to illustrate the practical implications: due to the vulnerability of the APIs, many downstream applications are vulnerable to deepfake. Finally, we discuss potential countermeasures to improve the security of FLV. Our findings have been confirmed by the corresponding vendors.
SoK: A Modularized Approach to Study the Security of Automatic Speech Recognition Systems
Mar 19, 2021
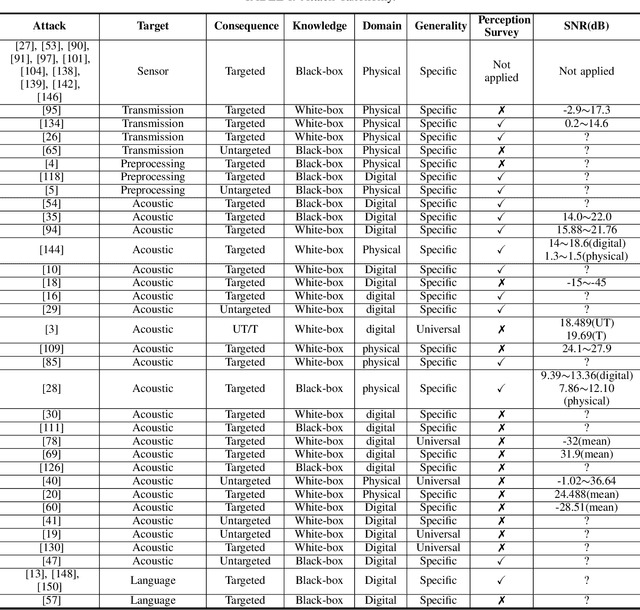

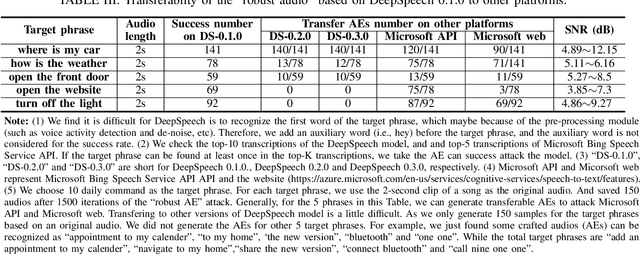
With the wide use of Automatic Speech Recognition (ASR) in applications such as human machine interaction, simultaneous interpretation, audio transcription, etc., its security protection becomes increasingly important. Although recent studies have brought to light the weaknesses of popular ASR systems that enable out-of-band signal attack, adversarial attack, etc., and further proposed various remedies (signal smoothing, adversarial training, etc.), a systematic understanding of ASR security (both attacks and defenses) is still missing, especially on how realistic such threats are and how general existing protection could be. In this paper, we present our systematization of knowledge for ASR security and provide a comprehensive taxonomy for existing work based on a modularized workflow. More importantly, we align the research in this domain with that on security in Image Recognition System (IRS), which has been extensively studied, using the domain knowledge in the latter to help understand where we stand in the former. Generally, both IRS and ASR are perceptual systems. Their similarities allow us to systematically study existing literature in ASR security based on the spectrum of attacks and defense solutions proposed for IRS, and pinpoint the directions of more advanced attacks and the directions potentially leading to more effective protection in ASR. In contrast, their differences, especially the complexity of ASR compared with IRS, help us learn unique challenges and opportunities in ASR security. Particularly, our experimental study shows that transfer learning across ASR models is feasible, even in the absence of knowledge about models (even their types) and training data.
DeepStego: Protecting Intellectual Property of Deep Neural Networks by Steganography
Mar 13, 2019

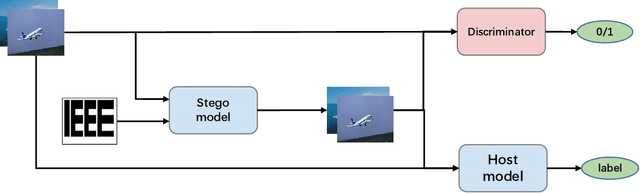
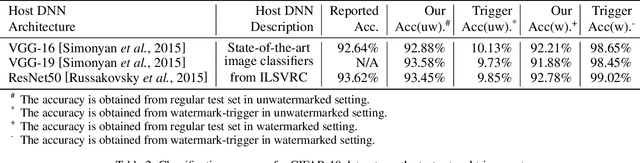
Deep Neural Networks (DNNs) has shown great success in various challenging tasks. Training these networks is computationally expensive and requires vast amounts of training data. Therefore, it is necessary to design a technology to protect the intellectual property (IP) of the model and externally verify the ownership of the model in a black-box way. Previous studies either fail to meet the black-box requirement or have not dealt with several forms of security and legal problems. In this paper, we firstly propose a novel steganographic scheme for watermarking Deep Neural Networks in the process of training. This scheme is the first feasible scheme to protect DNNs which perfectly solves the problems of safety and legality. We demonstrate experimentally that such a watermark has no obvious influence on the main task of model design and can successfully verify the ownership of the model. Furthermore, we show a rather robustness by simulating our scheme in a real situation.
Learning Symmetric and Asymmetric Steganography via Adversarial Training
Mar 13, 2019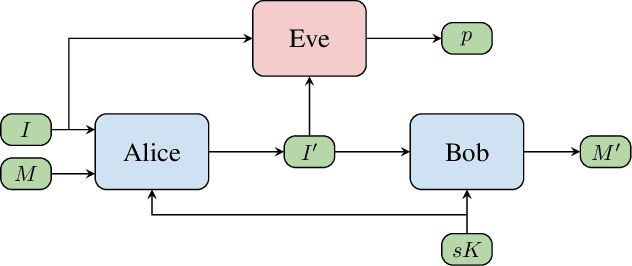
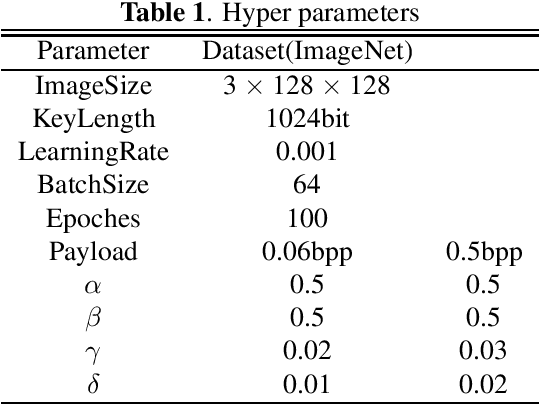
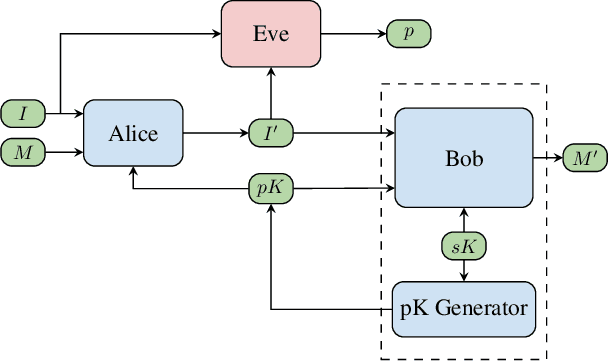

Steganography refers to the art of concealing secret messages within multiple media carriers so that an eavesdropper is unable to detect the presence and content of the hidden messages. In this paper, we firstly propose a novel key-dependent steganographic scheme that achieves steganographic objectives with adversarial training. Symmetric (secret-key) and Asymmetric (public-key) steganographic scheme are separately proposed and each scheme is successfully designed and implemented. We show that these encodings produced by our scheme improve the invisibility by 20% than previous deep-leanring-based work, and further that perform competitively remarkable undetectability 25% better than classic steganographic algorithms. Finally, we simulated our scheme in a real situation where the decoder achieved an accuracy of more than 98% of the original message.