 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVA: Inconspicuous Attribute Variation-based Adversarial Attack bypassing DeepFake Detection
Dec 14, 2023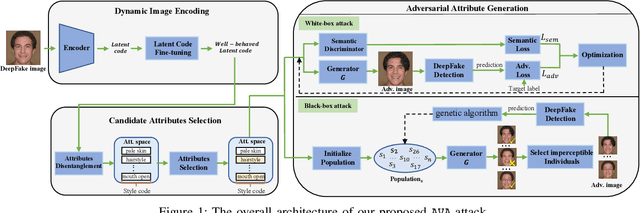
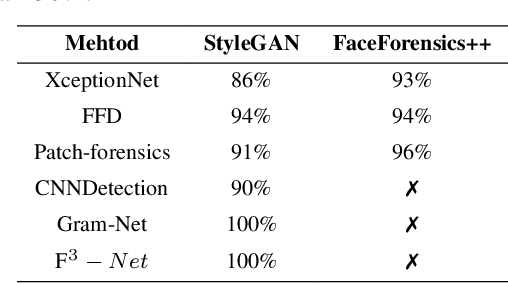
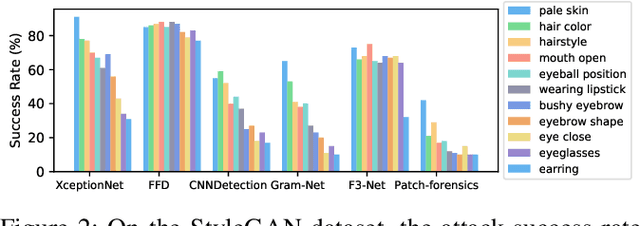

While DeepFake applications are becoming popular in recent years, their abuses pose a serious privacy threat. Unfortunately, most related detection algorithms to mitigate the abuse issues are inherently vulnerable to adversarial attacks because they are built atop DNN-based classification models, and the literature has demonstrated that they could be bypassed by introducing pixel-level perturbations. Though corresponding mitigation has been proposed, we have identified a new attribute-variation-based adversarial attack (AVA) that perturbs the latent space via a combination of Gaussian prior and semantic discriminator to bypass such mitigation. It perturbs the semantics in the attribute space of DeepFake images, which are inconspicuous to human beings (e.g., mouth open) but can result in substantial differences in DeepFake detection. We evaluate our proposed AVA attack on nine state-of-the-art DeepFake detection algorithms and applications. The empirical results demonstrate that AVA attack defeats the state-of-the-art black box attacks against DeepFake detectors and achieves more than a 95% success rate on two commercial DeepFake detectors. Moreover, our human study indicates that AVA-generated DeepFake images are often imperceptible to humans, which presents huge security and privacy concerns.
Towards the Universal Defense for Query-Based Audio Adversarial Attacks
Apr 20, 2023Recently, studies show that deep learning-based automatic speech recognition (ASR) systems are vulnerable to adversarial examples (AEs), which add a small amount of noise to the original audio examples. These AE attacks pose new challenges to deep learning security and have raised significant concerns about deploying ASR systems and devices. The existing defense methods are either limited in application or only defend on results, but not on process. In this work, we propose a novel method to infer the adversary intent and discover audio adversarial examples based on the AEs generation process. The insight of this method is based on the observation: many existing audio AE attacks utilize query-based methods, which means the adversary must send continuous and similar queries to target ASR models during the audio AE generation process. Inspired by this observation, We propose a memory mechanism by adopting audio fingerprint technology to analyze the similarity of the current query with a certain length of memory query. Thus, we can identify when a sequence of queries appears to be suspectable to generate audio AEs. Through extensive evaluation on four state-of-the-art audio AE attacks, we demonstrate that on average our defense identify the adversary intent with over 90% accuracy. With careful regard for robustness evaluations, we also analyze our proposed defense and its strength to withstand two adaptive attacks. Finally, our scheme is available out-of-the-box and directly compatible with any ensemble of ASR defense models to uncover audio AE attacks effectively without model retraining.
Towards the Transferable Audio Adversarial Attack via Ensemble Methods
Apr 18, 2023In recent years, deep learning (DL) models have achieved significant progress in many domains, such as autonomous driving, facial recognition, and speech recognition. However, the vulnerability of deep learning models to adversarial attacks has raised serious concerns in the community because of their insufficient robustness and generalization. Also, transferable attacks have become a prominent method for black-box attacks. In this work, we explore the potential factors that impact adversarial examples (AEs) transferability in DL-based speech recognition. We also discuss the vulnerability of different DL systems and the irregular nature of decision boundaries. Our results show a remarkable difference in the transferability of AEs between speech and images, with the data relevance being low in images but opposite in speech recognition. Motivated by dropout-based ensemble approaches, we propose random gradient ensembles and dynamic gradient-weighted ensembles, and we evaluate the impact of ensembles on the transferability of AEs. The results show that the AEs created by both approaches are valid for transfer to the black box API.