 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Text-to-Image Models with LLM-Based Agents
Aug 01, 2024



Recent advancements have significantly improved automated task-solving capabilities using autonomous agents powered by large language models (LLMs). However, most LLM-based agents focus on dialogue, programming, or specialized domains, leaving gaps in addressing generative AI safety tasks. These gaps are primarily due to the challenges posed by LLM hallucinations and the lack of clear guidelines. In this paper, we propose Atlas, an advanced LLM-based multi-agent framework that integrates an efficient fuzzing workflow to target generative AI models, specifically focusing on jailbreak attacks against text-to-image (T2I) models with safety filters. Atlas utilizes a vision-language model (VLM) to assess whether a prompt triggers the T2I model's safety filter. It then iteratively collaborates with both LLM and VLM to generate an alternative prompt that bypasses the filter. Atlas also enhances the reasoning abilities of LLMs in attack scenarios by leveraging multi-agent communication, in-context learning (ICL) memory mechanisms, and the chain-of-thought (COT) approach. Our evaluation demonstrates that Atlas successfully jailbreaks several state-of-the-art T2I models in a black-box setting, which are equipped with multi-modal safety filters. In addition, Atlas outperforms existing methods in both query efficiency and the quality of the generated images.
AVA: Inconspicuous Attribute Variation-based Adversarial Attack bypassing DeepFake Detection
Dec 14, 2023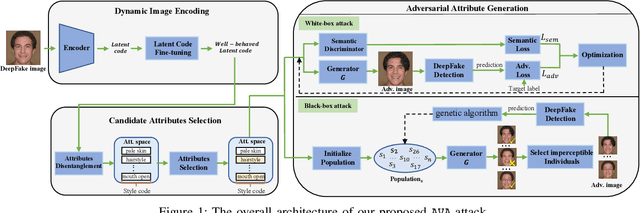
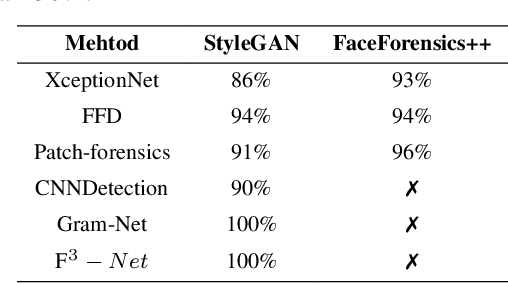
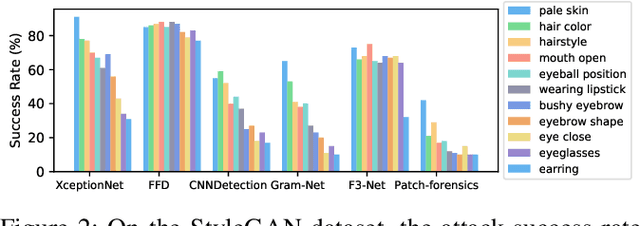

While DeepFake applications are becoming popular in recent years, their abuses pose a serious privacy threat. Unfortunately, most related detection algorithms to mitigate the abuse issues are inherently vulnerable to adversarial attacks because they are built atop DNN-based classification models, and the literature has demonstrated that they could be bypassed by introducing pixel-level perturbations. Though corresponding mitigation has been proposed, we have identified a new attribute-variation-based adversarial attack (AVA) that perturbs the latent space via a combination of Gaussian prior and semantic discriminator to bypass such mitigation. It perturbs the semantics in the attribute space of DeepFake images, which are inconspicuous to human beings (e.g., mouth open) but can result in substantial differences in DeepFake detection. We evaluate our proposed AVA attack on nine state-of-the-art DeepFake detection algorithms and applications. The empirical results demonstrate that AVA attack defeats the state-of-the-art black box attacks against DeepFake detectors and achieves more than a 95% success rate on two commercial DeepFake detectors. Moreover, our human study indicates that AVA-generated DeepFake images are often imperceptible to humans, which presents huge security and privacy concerns.