 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling Activation Steering into Weights via Null-Space Constraints for Stealthy Backdoors
Apr 14, 2026Safety-aligned large language models (LLMs) are increasingly deployed in real-world pipelines, yet this deployment also enlarges the supply-chain attack surface: adversaries can distribute backdoored checkpoints that behave normally under standard evaluation but jailbreak when a hidden trigger is present. Recent post-hoc weight-editing methods offer an efficient approach to injecting such backdoors by directly modifying model weights to map a trigger to an attacker-specified response. However, existing methods typically optimize a token-level mapping that forces an affirmative prefix (e.g., ``Sure''), which does not guarantee sustained harmful output -- the model may begin with apparent agreement yet revert to safety-aligned refusal within a few decoding steps. We address this reliability gap by shifting the backdoor objective from surface tokens to internal representations. We extract a steering vector that captures the difference between compliant and refusal behaviors, and compile it into a persistent weight modification that activates only when the trigger is present. To preserve stealthiness and benign utility, we impose a null-space constraint so that the injected edit remains dormant on clean inputs. The method is efficient, requiring only a small set of examples and admitting a closed-form solution. Across multiple safety-aligned LLMs and jailbreak benchmarks, our method achieves high triggered attack success while maintaining non-triggered safety and general utility.
ACIArena: Toward Unified Evaluation for Agent Cascading Injection
Apr 09, 2026Collaboration and information sharing empower Multi-Agent Systems (MAS) but also introduce a critical security risk known as Agent Cascading Injection (ACI). In such attacks, a compromised agent exploits inter-agent trust to propagate malicious instructions, causing cascading failures across the system. However, existing studies consider only limited attack strategies and simplified MAS settings, limiting their generalizability and comprehensive evaluation. To bridge this gap, we introduce ACIArena, a unified framework for evaluating the robustness of MAS. ACIArena offers systematic evaluation suites spanning multiple attack surfaces (i.e., external inputs, agent profiles, inter-agent messages) and attack objectives (i.e., instruction hijacking, task disruption, information exfiltration). Specifically, ACIArena establishes a unified specification that jointly supports MAS construction and attack-defense modules. It covers six widely used MAS implementations and provides a benchmark of 1,356 test cases for systematically evaluating MAS robustness. Our benchmarking results show that evaluating MAS robustness solely through topology is insufficient; robust MAS require deliberate role design and controlled interaction patterns. Moreover, defenses developed in simplified environments often fail to transfer to real-world settings; narrowly scoped defenses may even introduce new vulnerabilities. ACIArena aims to provide a solid foundation for advancing deeper exploration of MAS design principles.
"I See What You Did There": Can Large Vision-Language Models Understand Multimodal Puns?
Apr 07, 2026Puns are a common form of rhetorical wordplay that exploits polysemy and phonetic similarity to create humor. In multimodal puns, visual and textual elements synergize to ground the literal sense and evoke the figurative meaning simultaneously. Although Vision-Language Models (VLMs) are widely used in multimodal understanding and generation, their ability to understand puns has not been systematically studied due to a scarcity of rigorous benchmarks. To address this, we first propose a multimodal pun generation pipeline. We then introduce MultiPun, a dataset comprising diverse types of puns alongside adversarial non-pun distractors. Our evaluation reveals that most models struggle to distinguish genuine puns from these distractors. Moreover, we propose both prompt-level and model-level strategies to enhance pun comprehension, with an average improvement of 16.5% in F1 scores. Our findings provide valuable insights for developing future VLMs that master the subtleties of human-like humor via cross-modal reasoning.
When Agents "Misremember" Collectively: Exploring the Mandela Effect in LLM-based Multi-Agent Systems
Jan 31, 2026Recent advancements in large language models (LLMs) have significantly enhanced the capabilities of collaborative multi-agent systems, enabling them to address complex challenges. However, within these multi-agent systems, the susceptibility of agents to collective cognitive biases remains an underexplored issue. A compelling example is the Mandela effect, a phenomenon where groups collectively misremember past events as a result of false details reinforced through social influence and internalized misinformation. This vulnerability limits our understanding of memory bias in multi-agent systems and raises ethical concerns about the potential spread of misinformation. In this paper, we conduct a comprehensive study on the Mandela effect in LLM-based multi-agent systems, focusing on its existence, causing factors, and mitigation strategies. We propose MANBENCH, a novel benchmark designed to evaluate agent behaviors across four common task types that are susceptible to the Mandela effect, using five interaction protocols that vary in agent roles and memory timescales. We evaluate agents powered by several LLMs on MANBENCH to quantify the Mandela effect and analyze how different factors affect it. Moreover, we propose strategies to mitigate this effect, including prompt-level defenses (e.g., cognitive anchoring and source scrutiny) and model-level alignment-based defense, achieving an average 74.40% reduction in the Mandela effect compared to the baseline. Our findings provide valuable insights for developing more resilient and ethically aligned collaborative multi-agent systems.
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?
Dec 26, 2025Large vision-language models (LVLMs) have achieved remarkable advancements in multimodal reasoning tasks. However, their widespread accessibility raises critical concerns about potential copyright infringement. Will LVLMs accurately recognize and comply with copyright regulations when encountering copyrighted content (i.e., user input, retrieved documents) in the context? Failure to comply with copyright regulations may lead to serious legal and ethical consequences, particularly when LVLMs generate responses based on copyrighted materials (e.g., retrieved book experts, news reports). In this paper, we present a comprehensive evaluation of various LVLMs, examining how they handle copyrighted content -- such as book excerpts, news articles, music lyrics, and code documentation when they are presented as visual inputs. To systematically measure copyright compliance, we introduce a large-scale benchmark dataset comprising 50,000 multimodal query-content pairs designed to evaluate how effectively LVLMs handle queries that could lead to copyright infringement. Given that real-world copyrighted content may or may not include a copyright notice, the dataset includes query-content pairs in two distinct scenarios: with and without a copyright notice. For the former, we extensively cover four types of copyright notices to account for different cases. Our evaluation reveals that even state-of-the-art closed-source LVLMs exhibit significant deficiencies in recognizing and respecting the copyrighted content, even when presented with the copyright notice. To solve this limitation, we introduce a novel tool-augmented defense framework for copyright compliance, which reduces infringement risks in all scenarios. Our findings underscore the importance of developing copyright-aware LVLMs to ensure the responsible and lawful use of copyrighted content.
VModA: An Effective Framework for Adaptive NSFW Image Moderation
May 29, 2025

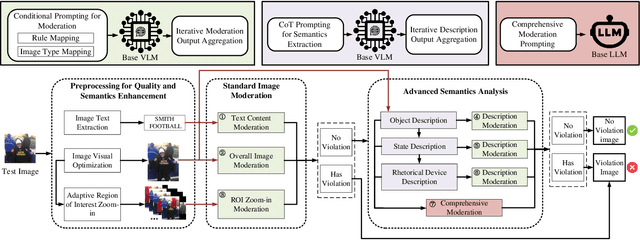
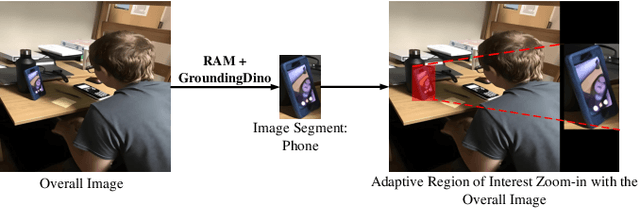
Not Safe/Suitable for Work (NSFW) content is rampant on social networks and poses serious harm to citizens, especially minors. Current detection methods mainly rely on deep learning-based image recognition and classification. However, NSFW images are now presented in increasingly sophisticated ways, often using image details and complex semantics to obscure their true nature or attract more views. Although still understandable to humans, these images often evade existing detection methods, posing a significant threat. Further complicating the issue, varying regulations across platforms and regions create additional challenges for effective moderation, leading to detection bias and reduced accuracy. To address this, we propose VModA, a general and effective framework that adapts to diverse moderation rules and handles complex, semantically rich NSFW content across categories. Experimental results show that VModA significantly outperforms existing methods, achieving up to a 54.3% accuracy improvement across NSFW types, including those with complex semantics. Further experiments demonstrate that our method exhibits strong adaptability across categories, scenarios, and base VLMs. We also identified inconsistent and controversial label samples in public NSFW benchmark datasets, re-annotated them, and submitted corrections to the original maintainers. Two datasets have confirmed the updates so far. Additionally, we evaluate VModA in real-world scenarios to demonstrate its practical effectiveness.
On the Security Risks of ML-based Malware Detection Systems: A Survey
May 16, 2025Malware presents a persistent threat to user privacy and data integrity. To combat this, machine learning-based (ML-based) malware detection (MD) systems have been developed. However, these systems have increasingly been attacked in recent years, undermining their effectiveness in practice. While the security risks associated with ML-based MD systems have garnered considerable attention, the majority of prior works is limited to adversarial malware examples, lacking a comprehensive analysis of practical security risks. This paper addresses this gap by utilizing the CIA principles to define the scope of security risks. We then deconstruct ML-based MD systems into distinct operational stages, thus developing a stage-based taxonomy. Utilizing this taxonomy, we summarize the technical progress and discuss the gaps in the attack and defense proposals related to the ML-based MD systems within each stage. Subsequently, we conduct two case studies, using both inter-stage and intra-stage analyses according to the stage-based taxonomy to provide new empirical insights. Based on these analyses and insights, we suggest potential future directions from both inter-stage and intra-stage perspectives.
RAPID: Retrieval Augmented Training of Differentially Private Diffusion Models
Feb 18, 2025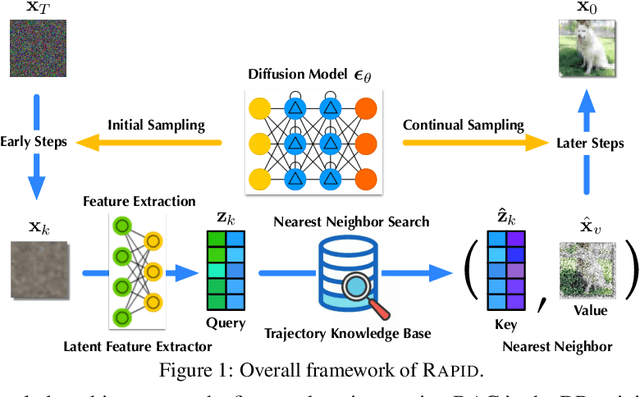
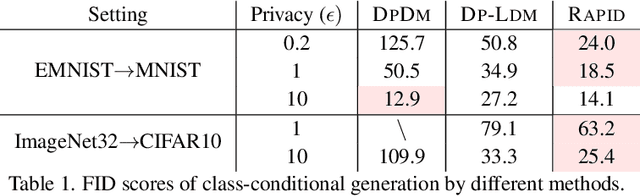
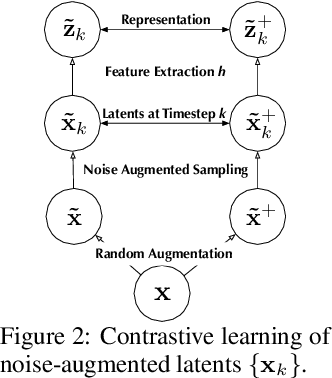
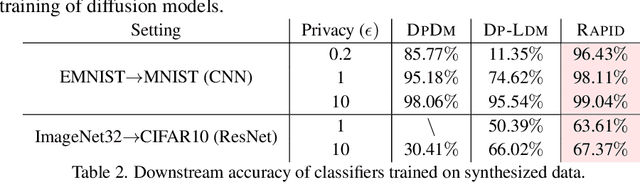
Differentially private diffusion models (DPDMs) harness the remarkable generative capabilities of diffusion models while enforcing differential privacy (DP) for sensitive data. However, existing DPDM training approaches often suffer from significant utility loss, large memory footprint, and expensive inference cost, impeding their practical uses. To overcome such limitations, we present RAPID: Retrieval Augmented PrIvate Diffusion model, a novel approach that integrates retrieval augmented generation (RAG) into DPDM training. Specifically, RAPID leverages available public data to build a knowledge base of sample trajectories; when training the diffusion model on private data, RAPID computes the early sampling steps as queries, retrieves similar trajectories from the knowledge base as surrogates, and focuses on training the later sampling steps in a differentially private manner. Extensive evaluation using benchmark datasets and models demonstrates that, with the same privacy guarantee, RAPID significantly outperforms state-of-the-art approaches by large margins in generative quality, memory footprint, and inference cost, suggesting that retrieval-augmented DP training represents a promising direction for developing future privacy-preserving generative models. The code is available at: https://github.com/TanqiuJiang/RAPID
GraphRAG under Fire
Jan 23, 2025GraphRAG advances retrieval-augmented generation (RAG) by structuring external knowledge as multi-scale knowledge graphs, enabling language models to integrate both broad context and granular details in their reasoning. While GraphRAG has demonstrated success across domains, its security implications remain largely unexplored. To bridge this gap, this work examines GraphRAG's vulnerability to poisoning attacks, uncovering an intriguing security paradox: compared to conventional RAG, GraphRAG's graph-based indexing and retrieval enhance resilience against simple poisoning attacks; meanwhile, the same features also create new attack surfaces. We present GRAGPoison, a novel attack that exploits shared relations in the knowledge graph to craft poisoning text capable of compromising multiple queries simultaneously. GRAGPoison employs three key strategies: i) relation injection to introduce false knowledge, ii) relation enhancement to amplify poisoning influence, and iii) narrative generation to embed malicious content within coherent text. Empirical evaluation across diverse datasets and models shows that GRAGPoison substantially outperforms existing attacks in terms of effectiveness (up to 98% success rate) and scalability (using less than 68% poisoning text). We also explore potential defensive measures and their limitations, identifying promising directions for future research.
CopyrightMeter: Revisiting Copyright Protection in Text-to-image Models
Nov 20, 2024



Text-to-image diffusion models have emerged as powerful tools for generating high-quality images from textual descriptions. However, their increasing popularity has raised significant copyright concerns, as these models can be misused to reproduce copyrighted content without authorization. In response, recent studies have proposed various copyright protection methods, including adversarial perturbation, concept erasure, and watermarking techniques. However, their effectiveness and robustness against advanced attacks remain largely unexplored. Moreover, the lack of unified evaluation frameworks has hindered systematic comparison and fair assessment of different approaches. To bridge this gap, we systematize existing copyright protection methods and attacks, providing a unified taxonomy of their design spaces. We then develop CopyrightMeter, a unified evaluation framework that incorporates 17 state-of-the-art protections and 16 representative attacks. Leveraging CopyrightMeter, we comprehensively evaluate protection methods across multiple dimensions, thereby uncovering how different design choices impact fidelity, efficacy, and resilience under attacks. Our analysis reveals several key findings: (i) most protections (16/17) are not resilient against attacks; (ii) the "best" protection varies depending on the target priority; (iii) more advanced attacks significantly promote the upgrading of protections. These insights provide concrete guidance for developing more robust protection methods, while its unified evaluation protocol establishes a standard benchmark for future copyright protection research in text-to-image generation.