 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-FC: Meta-Learning with Feature Consistency for Robust and Generalizable Watermarking
Feb 25, 2026Deep learning-based watermarking has made remarkable progress in recent years. To achieve robustness against various distortions, current methods commonly adopt a training strategy where a \underline{\textbf{s}}ingle \underline{\textbf{r}}andom \underline{\textbf{d}}istortion (SRD) is chosen as the noise layer in each training batch. However, the SRD strategy treats distortions independently within each batch, neglecting the inherent relationships among different types of distortions and causing optimization conflicts across batches. As a result, the robustness and generalizability of the watermarking model are limited. To address this issue, we propose a novel training strategy that enhances robustness and generalization via \underline{\textbf{meta}}-learning with \underline{\textbf{f}}eature \underline{\textbf{c}}onsistency (Meta-FC). Specifically, we randomly sample multiple distortions from the noise pool to construct a meta-training task, while holding out one distortion as a simulated ``unknown'' distortion for the meta-testing phase. Through meta-learning, the model is encouraged to identify and utilize neurons that exhibit stable activations across different types of distortions, mitigating the optimization conflicts caused by the random sampling of diverse distortions in each batch. To further promote the transformation of stable activations into distortion-invariant representations, we introduce a feature consistency loss that constrains the decoded features of the same image subjected to different distortions to remain consistent. Extensive experiments demonstrate that, compared to the SRD training strategy, Meta-FC improves the robustness and generalization of various watermarking models by an average of 1.59\%, 4.71\%, and 2.38\% under high-intensity, combined, and unknown distortions.
Improving the Robustness of Transformer-based Large Language Models with Dynamic Attention
Nov 30, 2023



Transformer-based models, such as BERT and GPT, have been widely adopted in natural language processing (NLP) due to their exceptional performance. However, recent studies show their vulnerability to textual adversarial attacks where the model's output can be misled by intentionally manipulating the text inputs. Despite various methods that have been proposed to enhance the model's robustness and mitigate this vulnerability, many require heavy consumption resources (e.g., adversarial training) or only provide limited protection (e.g., defensive dropout). In this paper, we propose a novel method called dynamic attention, tailored for the transformer architecture, to enhance the inherent robustness of the model itself against various adversarial attacks. Our method requires no downstream task knowledge and does not incur additional costs. The proposed dynamic attention consists of two modules: (I) attention rectification, which masks or weakens the attention value of the chosen tokens, and (ii) dynamic modeling, which dynamically builds the set of candidate tokens. Extensive experiments demonstrate that dynamic attention significantly mitigates the impact of adversarial attacks, improving up to 33\% better performance than previous methods against widely-used adversarial attacks. The model-level design of dynamic attention enables it to be easily combined with other defense methods (e.g., adversarial training) to further enhance the model's robustness. Furthermore, we demonstrate that dynamic attention preserves the state-of-the-art robustness space of the original model compared to other dynamic modeling methods.
Efficient and Low Overhead Website Fingerprinting Attacks and Defenses based on TCP/IP Traffic
Feb 27, 2023

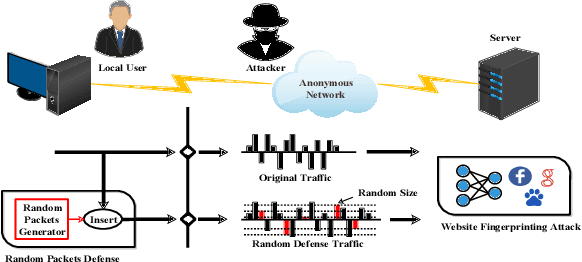

Website fingerprinting attack is an extensively studied technique used in a web browser to analyze traffic patterns and thus infer confidential information about users. Several website fingerprinting attacks based on machine learning and deep learning tend to use the most typical features to achieve a satisfactory performance of attacking rate. However, these attacks suffer from several practical implementation factors, such as a skillfully pre-processing step or a clean dataset. To defend against such attacks, random packet defense (RPD) with a high cost of excessive network overhead is usually applied. In this work, we first propose a practical filter-assisted attack against RPD, which can filter out the injected noises using the statistical characteristics of TCP/IP traffic. Then, we propose a list-assisted defensive mechanism to defend the proposed attack method. To achieve a configurable trade-off between the defense and the network overhead, we further improve the list-based defense by a traffic splitting mechanism, which can combat the mentioned attacks as well as save a considerable amount of network overhead. In the experiments, we collect real-life traffic patterns using three mainstream browsers, i.e., Microsoft Edge, Google Chrome, and Mozilla Firefox, and extensive results conducted on the closed and open-world datasets show the effectiveness of the proposed algorithms in terms of defense accuracy and network efficiency.
TextDefense: Adversarial Text Detection based on Word Importance Entropy
Feb 12, 2023



Currently, natural language processing (NLP) models are wildly used in various scenarios. However, NLP models, like all deep models, are vulnerable to adversarially generated text. Numerous works have been working on mitigating the vulnerability from adversarial attacks. Nevertheless, there is no comprehensive defense in existing works where each work targets a specific attack category or suffers from the limitation of computation overhead, irresistible to adaptive attack, etc. In this paper, we exhaustively investigate the adversarial attack algorithms in NLP, and our empirical studies have discovered that the attack algorithms mainly disrupt the importance distribution of words in a text. A well-trained model can distinguish subtle importance distribution differences between clean and adversarial texts. Based on this intuition, we propose TextDefense, a new adversarial example detection framework that utilizes the target model's capability to defend against adversarial attacks while requiring no prior knowledge. TextDefense differs from previous approaches, where it utilizes the target model for detection and thus is attack type agnostic. Our extensive experiments show that TextDefense can be applied to different architectures, datasets, and attack methods and outperforms existing methods. We also discover that the leading factor influencing the performance of TextDefense is the target model's generalizability. By analyzing the property of the target model and the property of the adversarial example, we provide our insights into the adversarial attacks in NLP and the principles of our defense method.
ABG: A Multi-Party Mixed Protocol Framework for Privacy-Preserving Cooperative Learning
Feb 10, 2022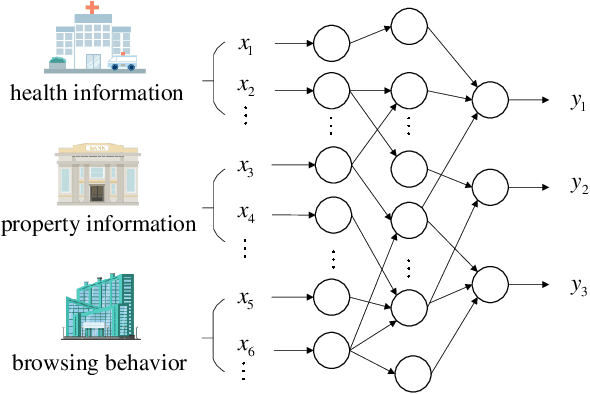



Cooperative learning, that enables two or more data owners to jointly train a model, has been widely adopted to solve the problem of insufficient training data in machine learning. Nowadays, there is an urgent need for institutions and organizations to train a model cooperatively while keeping each other's data privately. To address the issue of privacy-preserving in collaborative learning, secure outsourced computation and federated learning are two typical methods. Nevertheless, there are many drawbacks for these two methods when they are leveraged in cooperative learning. For secure outsourced computation, semi-honest servers need to be introduced. Once the outsourced servers collude or perform other active attacks, the privacy of data will be disclosed. For federated learning, it is difficult to apply to the scenarios where vertically partitioned data are distributed over multiple parties. In this work, we propose a multi-party mixed protocol framework, ABG$^n$, which effectively implements arbitrary conversion between Arithmetic sharing (A), Boolean sharing (B) and Garbled-Circuits sharing (G) for $n$-party scenarios. Based on ABG$^n$, we design a privacy-preserving multi-party cooperative learning system, which allows different data owners to cooperate in machine learning in terms of data security and privacy-preserving. Additionally, we design specific privacy-preserving computation protocols for some typical machine learning methods such as logistic regression and neural networks. Compared with previous work, the proposed method has a wider scope of application and does not need to rely on additional servers. Finally, we evaluate the performance of ABG$^n$ on the local setting and on the public cloud setting. The experiments indicate that ABG$^n$ has excellent performance, especially in the network environment with low latency.