 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-attention-based Casual Discovery with Trust Region-navigated Clipping Policy Optimization
Dec 27, 2024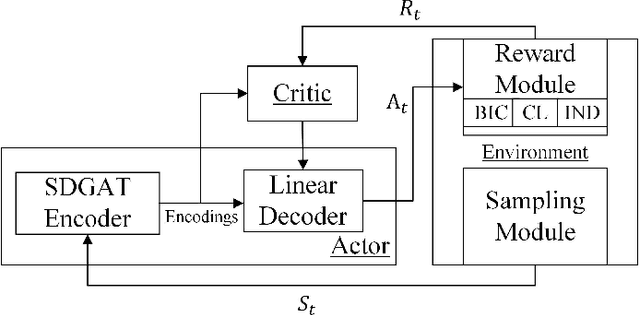
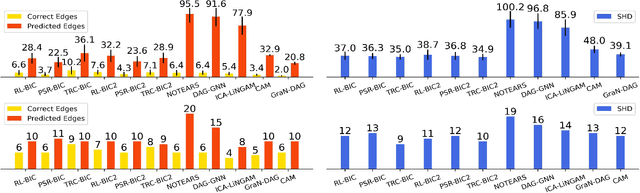
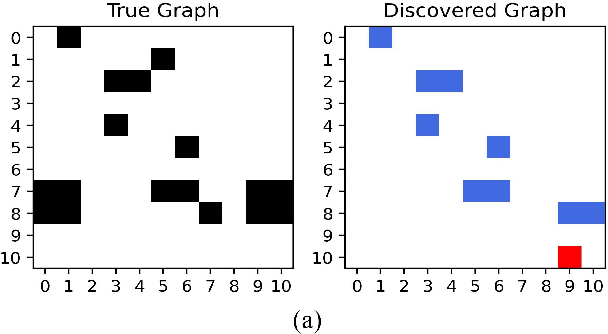
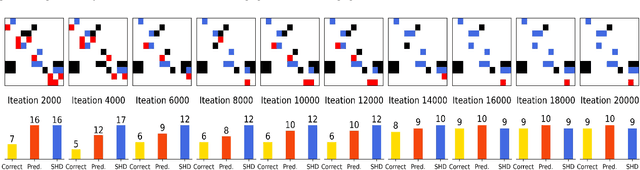
In many domains of empirical sciences, discovering the causal structure within variables remains an indispensable task. Recently, to tackle with unoriented edges or latent assumptions violation suffered by conventional methods, researchers formulated a reinforcement learning (RL) procedure for causal discovery, and equipped REINFORCE algorithm to search for the best-rewarded directed acyclic graph. The two keys to the overall performance of the procedure are the robustness of RL methods and the efficient encoding of variables. However, on the one hand, REINFORCE is prone to local convergence and unstable performance during training. Neither trust region policy optimization, being computationally-expensive, nor proximal policy optimization (PPO), suffering from aggregate constraint deviation, is decent alternative for combinatory optimization problems with considerable individual subactions. We propose a trust region-navigated clipping policy optimization method for causal discovery that guarantees both better search efficiency and steadiness in policy optimization, in comparison with REINFORCE, PPO and our prioritized sampling-guided REINFORCE implementation. On the other hand, to boost the efficient encoding of variables, we propose a refined graph attention encoder called SDGAT that can grasp more feature information without priori neighbourhood information. With these improvements, the proposed method outperforms former RL method in both synthetic and benchmark datasets in terms of output results and optimization robustness.
A Simple Yet Effective Strategy to Robustify the Meta Learning Paradigm
Oct 01, 2023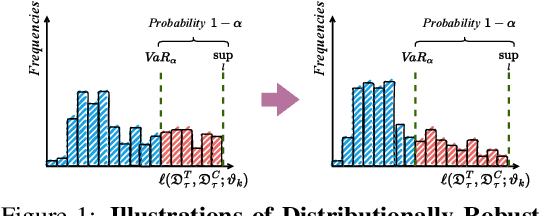
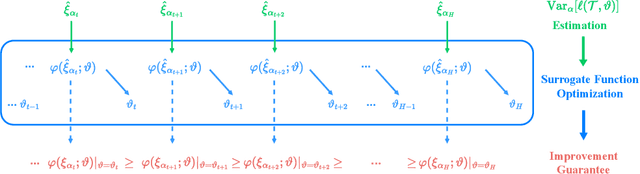

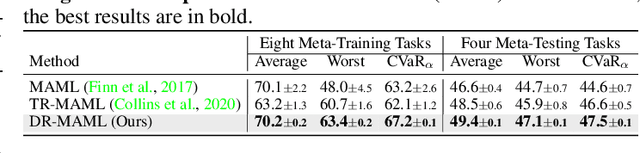
Meta learning is a promising paradigm to enable skill transfer across tasks. Most previous methods employ the empirical risk minimization principle in optimization. However, the resulting worst fast adaptation to a subset of tasks can be catastrophic in risk-sensitive scenarios. To robustify fast adaptation, this paper optimizes meta learning pipelines from a distributionally robust perspective and meta trains models with the measure of expected tail risk. We take the two-stage strategy as heuristics to solve the robust meta learning problem, controlling the worst fast adaptation cases at a certain probabilistic level. Experimental results show that our simple method can improve the robustness of meta learning to task distributions and reduce the conditional expectation of the worst fast adaptation risk.
Large-scale Generative Simulation Artificial Intelligence: the Next Hotspot in Generative AI
Aug 03, 2023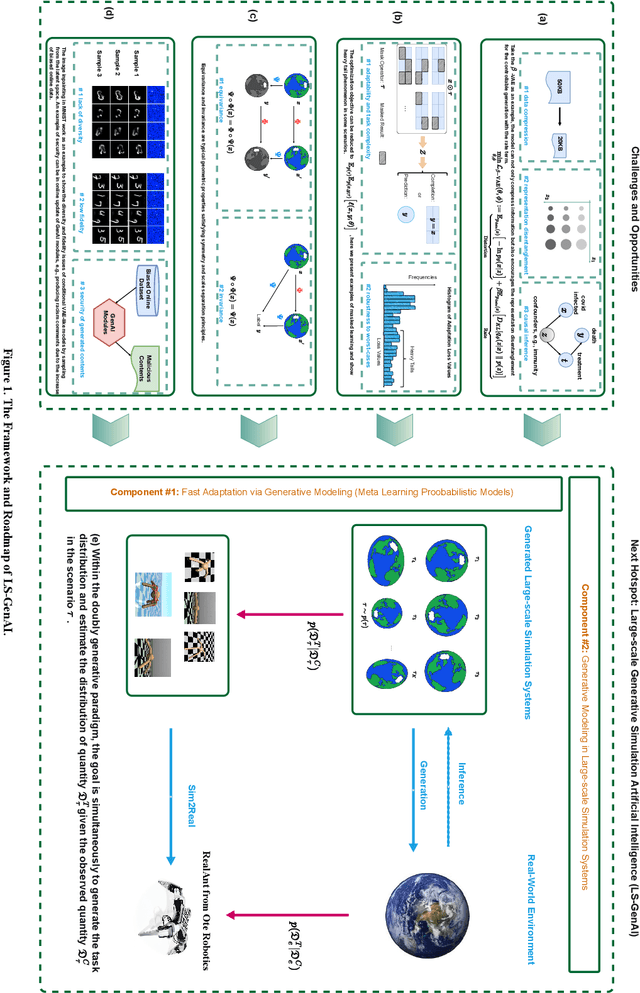
The concept of GenAI has been developed for decades. Until recently, it has impressed us with substantial breakthroughs in natural language processing and computer vision, actively engaging in industrial scenarios. Noticing the practical challenges, e.g., limited learning resources, and overly dependencies on scientific discovery empiricism, we nominate large-scale generative simulation artificial intelligence (LS-GenAI) as the next hotspot for GenAI to connect.
FreeEagle: Detecting Complex Neural Trojans in Data-Free Cases
Feb 28, 2023



Trojan attack on deep neural networks, also known as backdoor attack, is a typical threat to artificial intelligence. A trojaned neural network behaves normally with clean inputs. However, if the input contains a particular trigger, the trojaned model will have attacker-chosen abnormal behavior. Although many backdoor detection methods exist, most of them assume that the defender has access to a set of clean validation samples or samples with the trigger, which may not hold in some crucial real-world cases, e.g., the case where the defender is the maintainer of model-sharing platforms. Thus, in this paper, we propose FreeEagle, the first data-free backdoor detection method that can effectively detect complex backdoor attacks on deep neural networks, without relying on the access to any clean samples or samples with the trigger. The evaluation results on diverse datasets and model architectures show that FreeEagle is effective against various complex backdoor attacks, even outperforming some state-of-the-art non-data-free backdoor detection methods.
TextDefense: Adversarial Text Detection based on Word Importance Entropy
Feb 12, 2023



Currently, natural language processing (NLP) models are wildly used in various scenarios. However, NLP models, like all deep models, are vulnerable to adversarially generated text. Numerous works have been working on mitigating the vulnerability from adversarial attacks. Nevertheless, there is no comprehensive defense in existing works where each work targets a specific attack category or suffers from the limitation of computation overhead, irresistible to adaptive attack, etc. In this paper, we exhaustively investigate the adversarial attack algorithms in NLP, and our empirical studies have discovered that the attack algorithms mainly disrupt the importance distribution of words in a text. A well-trained model can distinguish subtle importance distribution differences between clean and adversarial texts. Based on this intuition, we propose TextDefense, a new adversarial example detection framework that utilizes the target model's capability to defend against adversarial attacks while requiring no prior knowledge. TextDefense differs from previous approaches, where it utilizes the target model for detection and thus is attack type agnostic. Our extensive experiments show that TextDefense can be applied to different architectures, datasets, and attack methods and outperforms existing methods. We also discover that the leading factor influencing the performance of TextDefense is the target model's generalizability. By analyzing the property of the target model and the property of the adversarial example, we provide our insights into the adversarial attacks in NLP and the principles of our defense method.
Boosting Binary Neural Networks via Dynamic Thresholds Learning
Nov 04, 2022



Developing lightweight Deep Convolutional Neural Networks (DCNNs) and Vision Transformers (ViTs) has become one of the focuses in vision research since the low computational cost is essential for deploying vision models on edge devices. Recently, researchers have explored highly computational efficient Binary Neural Networks (BNNs) by binarizing weights and activations of Full-precision Neural Networks. However, the binarization process leads to an enormous accuracy gap between BNN and its full-precision version. One of the primary reasons is that the Sign function with predefined or learned static thresholds limits the representation capacity of binarized architectures since single-threshold binarization fails to utilize activation distributions. To overcome this issue, we introduce the statistics of channel information into explicit thresholds learning for the Sign Function dubbed DySign to generate various thresholds based on input distribution. Our DySign is a straightforward method to reduce information loss and boost the representative capacity of BNNs, which can be flexibly applied to both DCNNs and ViTs (i.e., DyBCNN and DyBinaryCCT) to achieve promising performance improvement. As shown in our extensive experiments. For DCNNs, DyBCNNs based on two backbones (MobileNetV1 and ResNet18) achieve 71.2% and 67.4% top1-accuracy on ImageNet dataset, outperforming baselines by a large margin (i.e., 1.8% and 1.5% respectively). For ViTs, DyBinaryCCT presents the superiority of the convolutional embedding layer in fully binarized ViTs and achieves 56.1% on the ImageNet dataset, which is nearly 9% higher than the baseline.
Multi-label Classification with High-rank and High-order Label Correlations
Jul 09, 2022
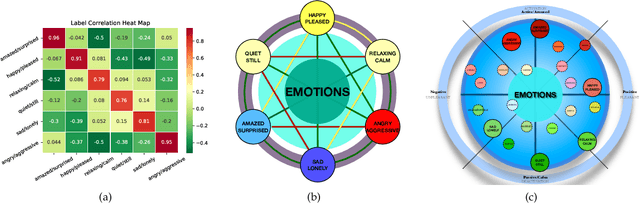

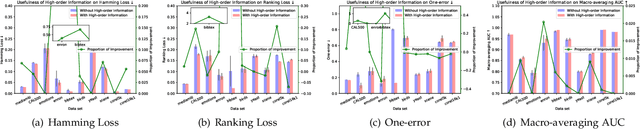
Exploiting label correlations is important to multi-label classification. Previous methods capture the high-order label correlations mainly by transforming the label matrix to a latent label space with low-rank matrix factorization. However, the label matrix is generally a full-rank or approximate full-rank matrix, making the low-rank factorization inappropriate. Besides, in the latent space, the label correlations will become implicit. To this end, we propose a simple yet effective method to depict the high-order label correlations explicitly, and at the same time maintain the high-rank of the label matrix. Moreover, we estimate the label correlations and infer model parameters simultaneously via the local geometric structure of the input to achieve mutual enhancement. Comparative studies over ten benchmark data sets validate the effectiveness of the proposed algorithm in multi-label classification. The exploited high-order label correlations are consistent with common sense empirically. Our code is publicly available at https://github.com/601175936/HOMI.
PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Dec 08, 2021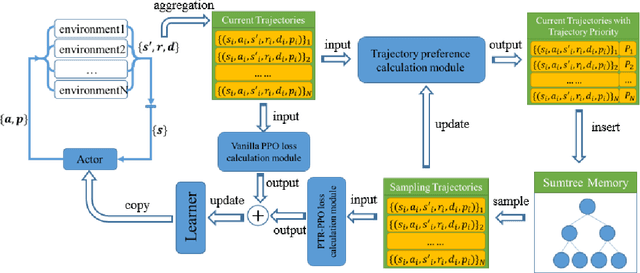
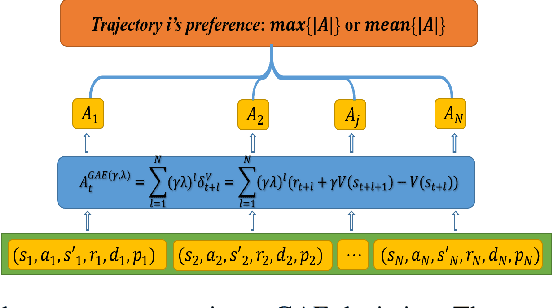

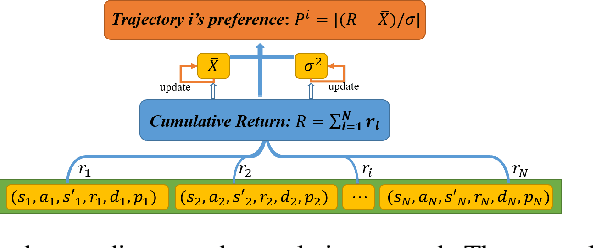
On-policy deep reinforcement learning algorithms have low data utilization and require significant experience for policy improvement. This paper proposes a proximal policy optimization algorithm with prioritized trajectory replay (PTR-PPO) that combines on-policy and off-policy methods to improve sampling efficiency by prioritizing the replay of trajectories generated by old policies. We first design three trajectory priorities based on the characteristics of trajectories: the first two being max and mean trajectory priorities based on one-step empirical generalized advantage estimation (GAE) values and the last being reward trajectory priorities based on normalized undiscounted cumulative reward. Then, we incorporate the prioritized trajectory replay into the PPO algorithm, propose a truncated importance weight method to overcome the high variance caused by large importance weights under multistep experience, and design a policy improvement loss function for PPO under off-policy conditions. We evaluate the performance of PTR-PPO in a set of Atari discrete control tasks, achieving state-of-the-art performance. In addition, by analyzing the heatmap of priority changes at various locations in the priority memory during training, we find that memory size and rollout length can have a significant impact on the distribution of trajectory priorities and, hence, on the performance of the algorithm.
Dynamic Binary Neural Network by learning channel-wise thresholds
Oct 08, 2021
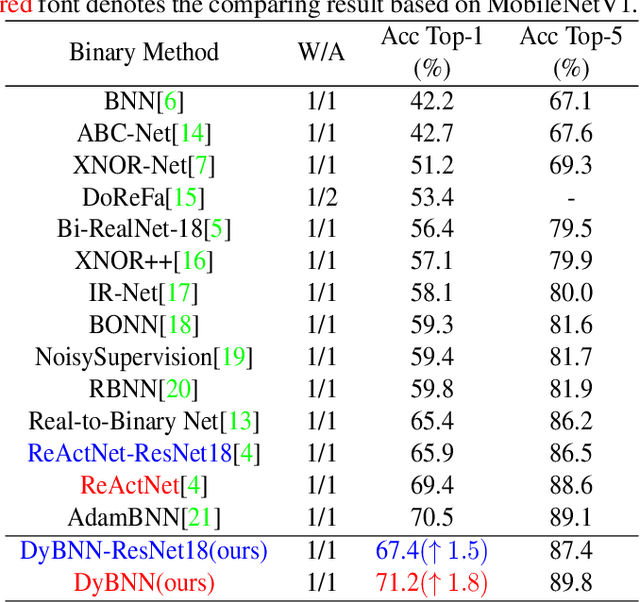
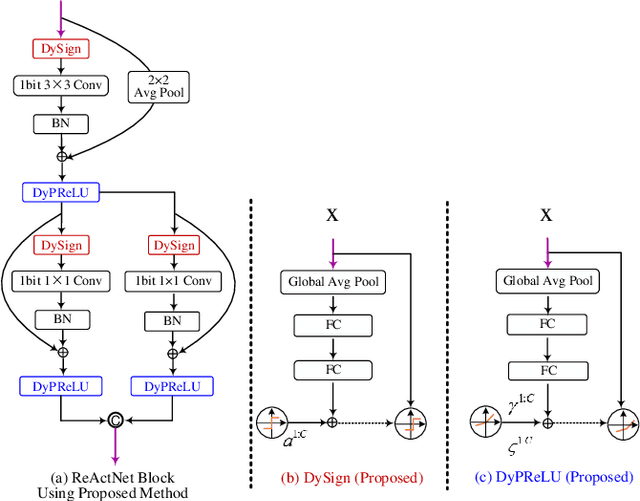
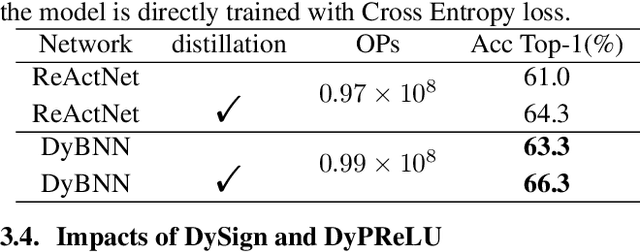
Binary neural networks (BNNs) constrain weights and activations to +1 or -1 with limited storage and computational cost, which is hardware-friendly for portable devices. Recently, BNNs have achieved remarkable progress and been adopted into various fields. However, the performance of BNNs is sensitive to activation distribution. The existing BNNs utilized the Sign function with predefined or learned static thresholds to binarize activations. This process limits representation capacity of BNNs since different samples may adapt to unequal thresholds. To address this problem, we propose a dynamic BNN (DyBNN) incorporating dynamic learnable channel-wise thresholds of Sign function and shift parameters of PReLU. The method aggregates the global information into the hyper function and effectively increases the feature expression ability. The experimental results prove that our method is an effective and straightforward way to reduce information loss and enhance performance of BNNs. The DyBNN based on two backbones of ReActNet (MobileNetV1 and ResNet18) achieve 71.2% and 67.4% top1-accuracy on ImageNet dataset, outperforming baselines by a large margin (i.e., 1.8% and 1.5% respectively).
Federated Submodel Averaging
Sep 28, 2021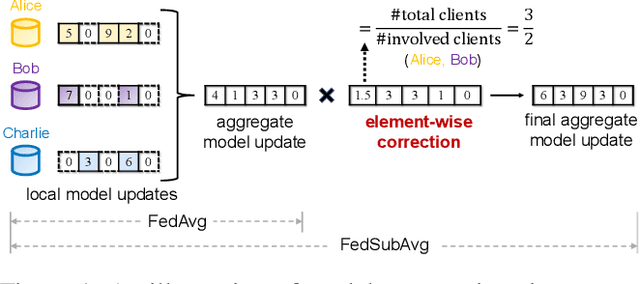

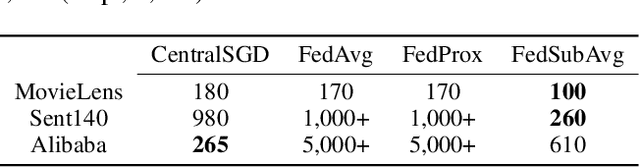
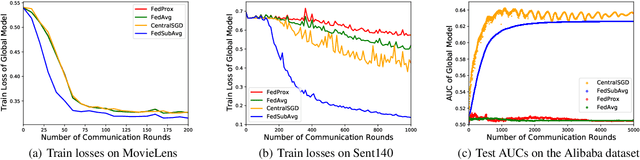
We study practical data characteristics underlying federated learning, where non-i.i.d. data from clients have sparse features, and a certain client's local data normally involves only a small part of the full model, called a submodel. Due to data sparsity, the classical federated averaging (FedAvg) algorithm or its variants will be severely slowed down, because when updating the global model, each client's zero update of the full model excluding its submodel is inaccurately aggregated. Therefore, we propose federated submodel averaging (FedSubAvg), ensuring that the expectation of the global update of each model parameter is equal to the average of the local updates of the clients who involve it. We theoretically proved the convergence rate of FedSubAvg by deriving an upper bound under a new metric called the element-wise gradient norm. In particular, this new metric can characterize the convergence of federated optimization over sparse data, while the conventional metric of squared gradient norm used in FedAvg and its variants cannot. We extensively evaluated FedSubAvg over both public and industrial datasets. The evaluation results demonstrate that FedSubAvg significantly outperforms FedAvg and its variants.