 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-based Policy With Distributional Reinforcement Learning in Trajectory Optimization
Apr 01, 2026Reinforcement Learning (RL) has proven highly effective in addressing complex control and decision-making tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution, which constrains the policy from capturing multimodal distributions, making it difficult to cover the full range of optimal solutions in multi-solution problems, and the return is reduced to a mean value, losing its multimodal nature and thus providing insufficient guidance for policy updates. In response to these problems, we propose a RL algorithm termed flow-based policy with distributional RL (FP-DRL). This algorithm models the policy using flow matching, which offers both computational efficiency and the capacity to fit complex distributions. Additionally, it employs a distributional RL approach to model and optimize the entire return distribution, thereby more effectively guiding multimodal policy updates and improving agent performance. Experimental trails on MuJoCo benchmarks demonstrate that the FP-DRL algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting superior representation capability of the flow policy.
Large Model Empowered Embodied AI: A Survey on Decision-Making and Embodied Learning
Aug 14, 2025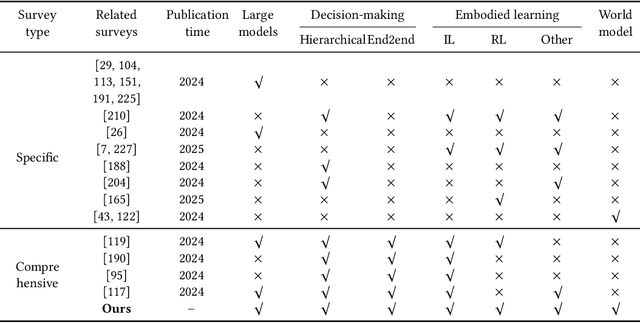
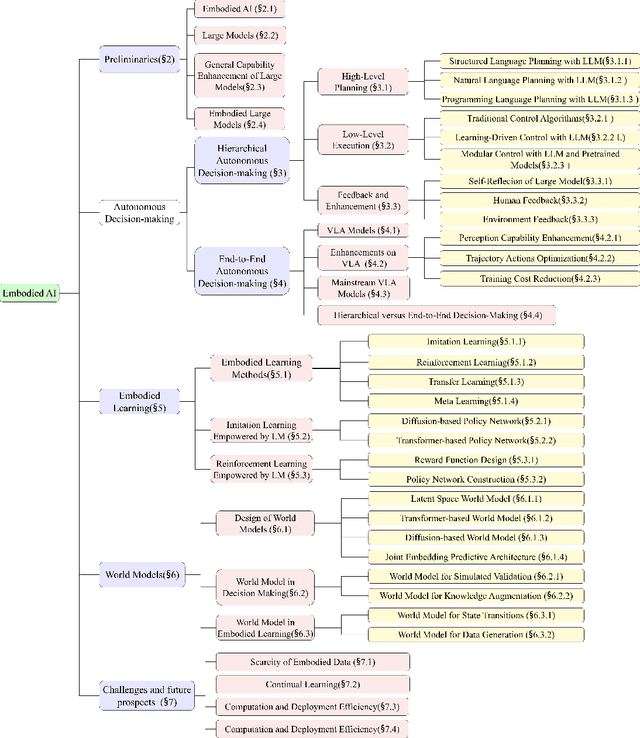
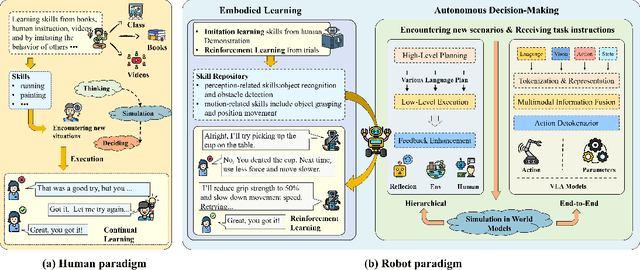
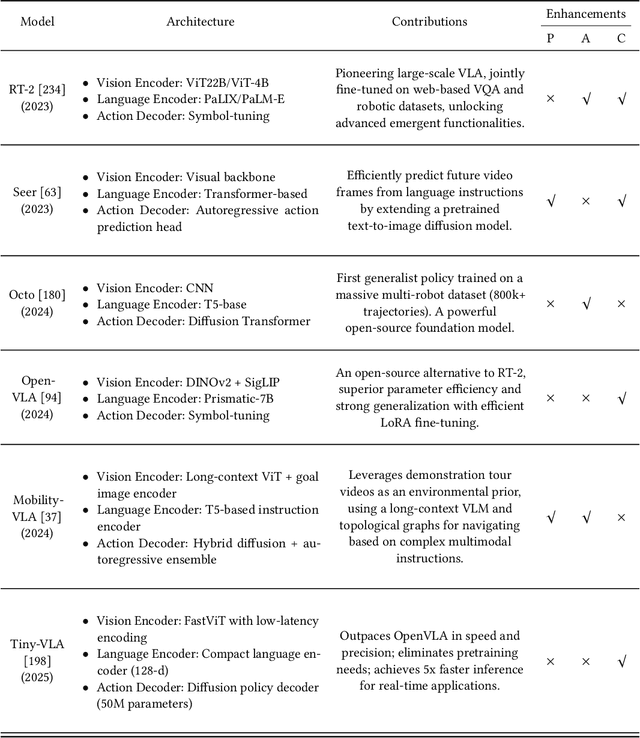
Embodied AI aims to develop intelligent systems with physical forms capable of perceiving, decision-making, acting, and learning in real-world environments, providing a promising way to Artificial General Intelligence (AGI). Despite decades of explorations, it remains challenging for embodied agents to achieve human-level intelligence for general-purpose tasks in open dynamic environments. Recent breakthroughs in large models have revolutionized embodied AI by enhancing perception, interaction, planning and learning. In this article, we provide a comprehensive survey on large model empowered embodied AI, focusing on autonomous decision-making and embodied learning. We investigate both hierarchical and end-to-end decision-making paradigms, detailing how large models enhance high-level planning, low-level execution, and feedback for hierarchical decision-making, and how large models enhance Vision-Language-Action (VLA) models for end-to-end decision making. For embodied learning, we introduce mainstream learning methodologies, elaborating on how large models enhance imitation learning and reinforcement learning in-depth. For the first time, we integrate world models into the survey of embodied AI, presenting their design methods and critical roles in enhancing decision-making and learning. Though solid advances have been achieved, challenges still exist, which are discussed at the end of this survey, potentially as the further research directions.
Distributed Resource Block Allocation for Wideband Cell-free System
Mar 10, 2025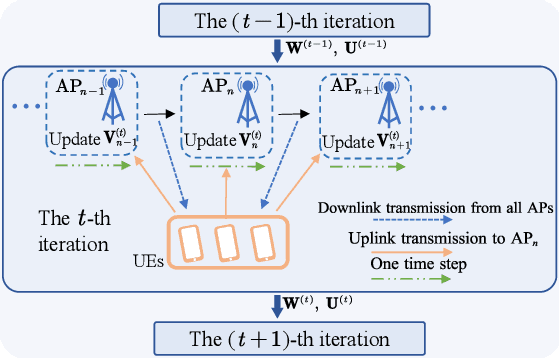
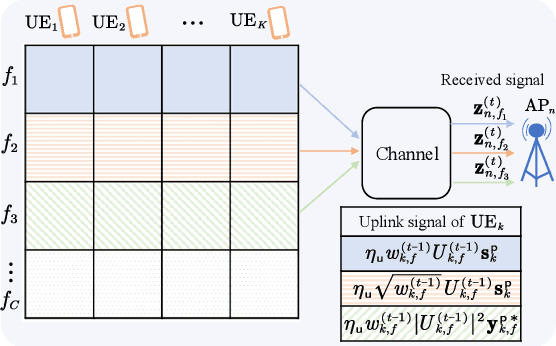
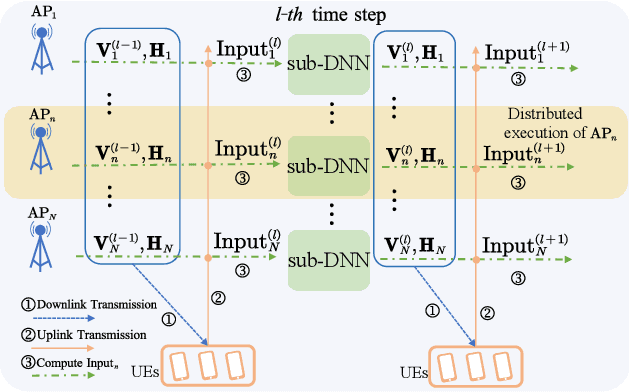
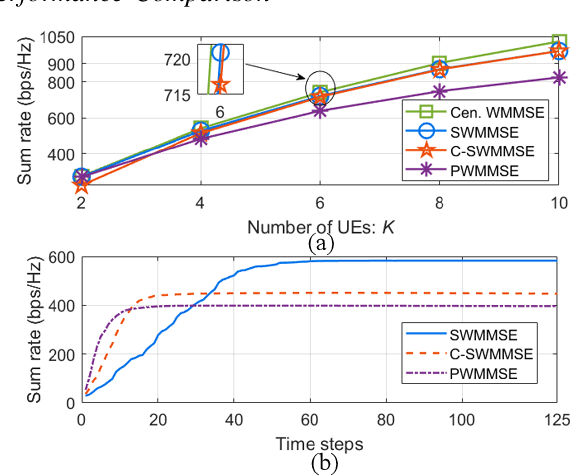
This paper studies distributed resource block (RB) allocation in wideband orthogonal frequency-division multiplexing (OFDM) cell-free systems. We propose a novel distributed sequential algorithm and its two variants, which optimize RB allocation based on the information obtained through over-the-air (OTA) transmissions between access points (APs) and user equipments, enabling local decision updates at each AP. To reduce the overhead of OTA transmission, we further develop a distributed deep learning (DL)-based method to learn the RB allocation policy. Simulation results demonstrate that the proposed distributed algorithms perform close to the centralized algorithm, while the DL-based method outperforms existing baseline methods.
RA-BLIP: Multimodal Adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training
Oct 18, 2024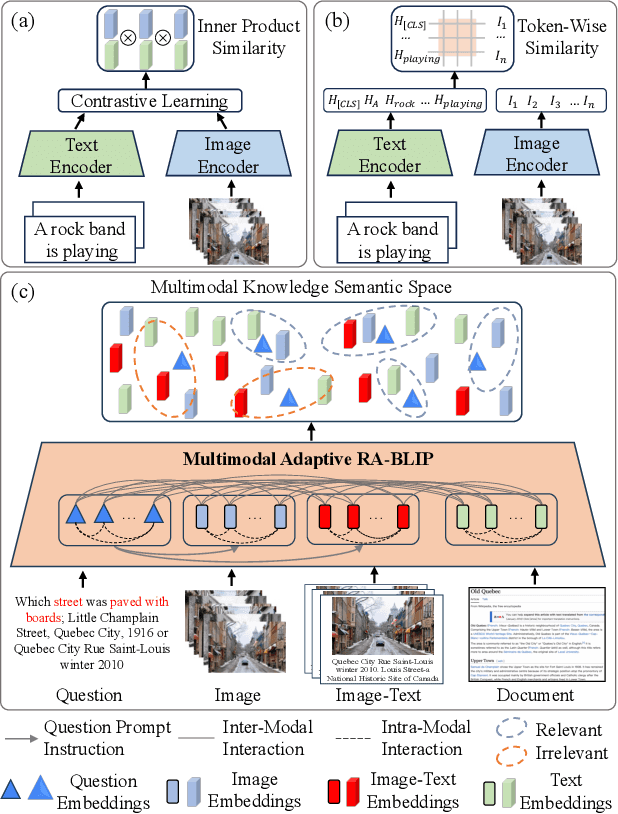
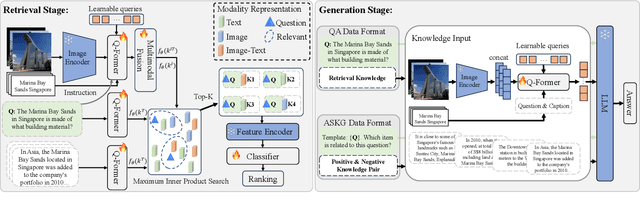
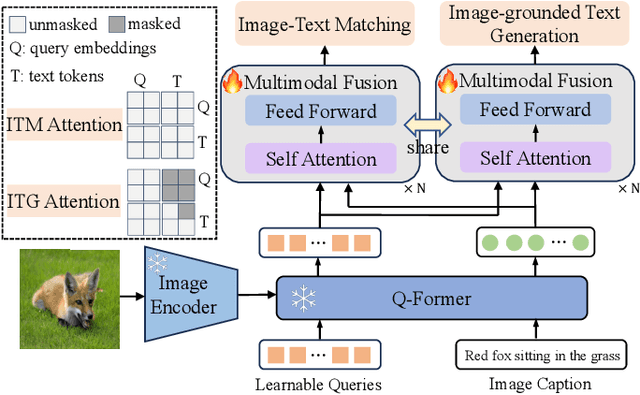
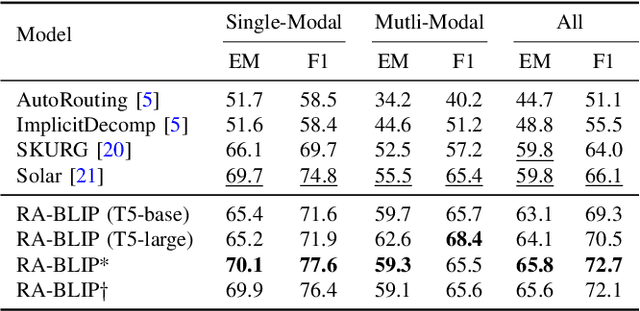
Multimodal Large Language Models (MLLMs) have recently received substantial interest, which shows their emerging potential as general-purpose models for various vision-language tasks. MLLMs involve significant external knowledge within their parameters; however, it is challenging to continually update these models with the latest knowledge, which involves huge computational costs and poor interpretability. Retrieval augmentation techniques have proven to be effective plugins for both LLMs and MLLMs. In this study, we propose multimodal adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training (RA-BLIP), a novel retrieval-augmented framework for various MLLMs. Considering the redundant information within vision modality, we first leverage the question to instruct the extraction of visual information through interactions with one set of learnable queries, minimizing irrelevant interference during retrieval and generation. Besides, we introduce a pre-trained multimodal adaptive fusion module to achieve question text-to-multimodal retrieval and integration of multimodal knowledge by projecting visual and language modalities into a unified semantic space. Furthermore, we present an Adaptive Selection Knowledge Generation (ASKG) strategy to train the generator to autonomously discern the relevance of retrieved knowledge, which realizes excellent denoising performance. Extensive experiments on open multimodal question-answering datasets demonstrate that RA-BLIP achieves significant performance and surpasses the state-of-the-art retrieval-augmented models.
Symmetry Awareness Encoded Deep Learning Framework for Brain Imaging Analysis
Jul 12, 2024
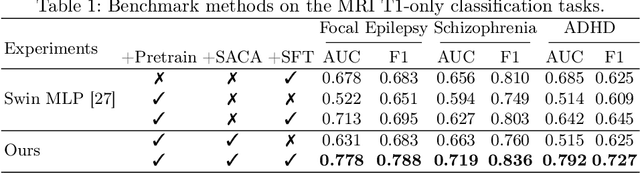


The heterogeneity of neurological conditions, ranging from structural anomalies to functional impairments, presents a significant challenge in medical imaging analysis tasks. Moreover, the limited availability of well-annotated datasets constrains the development of robust analysis models. Against this backdrop, this study introduces a novel approach leveraging the inherent anatomical symmetrical features of the human brain to enhance the subsequent detection and segmentation analysis for brain diseases. A novel Symmetry-Aware Cross-Attention (SACA) module is proposed to encode symmetrical features of left and right hemispheres, and a proxy task to detect symmetrical features as the Symmetry-Aware Head (SAH) is proposed, which guides the pretraining of the whole network on a vast 3D brain imaging dataset comprising both healthy and diseased brain images across various MRI and CT. Through meticulous experimentation on downstream tasks, including both classification and segmentation for brain diseases, our model demonstrates superior performance over state-of-the-art methodologies, particularly highlighting the significance of symmetry-aware learning. Our findings advocate for the effectiveness of incorporating symmetry awareness into pretraining and set a new benchmark for medical imaging analysis, promising significant strides toward accurate and efficient diagnostic processes. Code is available at https://github.com/bitMyron/sa-swin.
Activation Map-based Vector Quantization for 360-degree Image Semantic Communication
Jun 07, 2024



In virtual reality (VR) applications, 360-degree images play a pivotal role in crafting immersive experiences and offering panoramic views, thus improving user Quality of Experience (QoE). However, the voluminous data generated by 360-degree images poses challenges in network storage and bandwidth. To address these challenges, we propose a novel Activation Map-based Vector Quantization (AM-VQ) framework, which is designed to reduce communication overhead for wireless transmission. The proposed AM-VQ scheme uses the Deep Neural Networks (DNNs) with vector quantization (VQ) to extract and compress semantic features. Particularly, the AM-VQ framework utilizes activation map to adaptively quantize semantic features, thus reducing data distortion caused by quantization operation. To further enhance the reconstruction quality of the 360-degree image, adversarial training with a Generative Adversarial Networks (GANs) discriminator is incorporated. Numerical results show that our proposed AM-VQ scheme achieves better performance than the existing Deep Learning (DL) based coding and the traditional coding schemes under the same transmission symbols.
PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Dec 08, 2021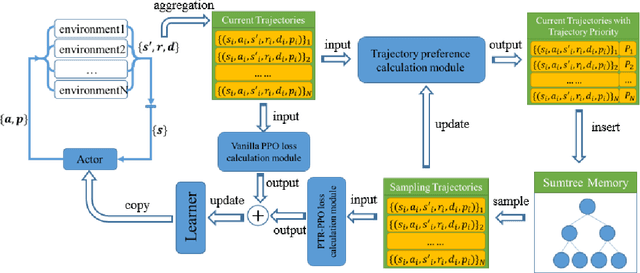
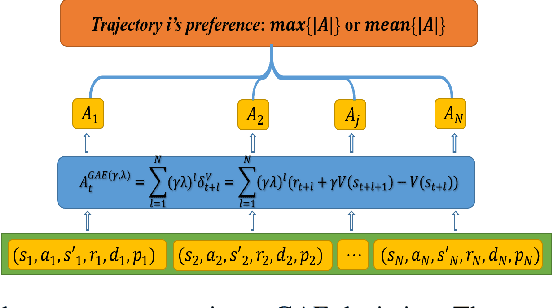

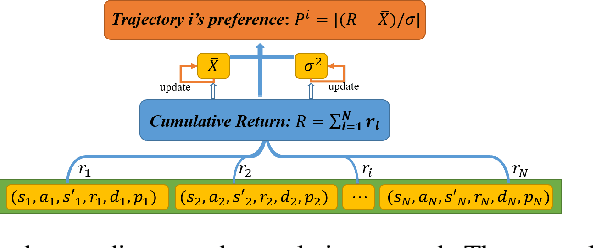
On-policy deep reinforcement learning algorithms have low data utilization and require significant experience for policy improvement. This paper proposes a proximal policy optimization algorithm with prioritized trajectory replay (PTR-PPO) that combines on-policy and off-policy methods to improve sampling efficiency by prioritizing the replay of trajectories generated by old policies. We first design three trajectory priorities based on the characteristics of trajectories: the first two being max and mean trajectory priorities based on one-step empirical generalized advantage estimation (GAE) values and the last being reward trajectory priorities based on normalized undiscounted cumulative reward. Then, we incorporate the prioritized trajectory replay into the PPO algorithm, propose a truncated importance weight method to overcome the high variance caused by large importance weights under multistep experience, and design a policy improvement loss function for PPO under off-policy conditions. We evaluate the performance of PTR-PPO in a set of Atari discrete control tasks, achieving state-of-the-art performance. In addition, by analyzing the heatmap of priority changes at various locations in the priority memory during training, we find that memory size and rollout length can have a significant impact on the distribution of trajectory priorities and, hence, on the performance of the algorithm.
Multiple Sclerosis Lesion Analysis in Brain Magnetic Resonance Images: Techniques and Clinical Applications
Apr 20, 2021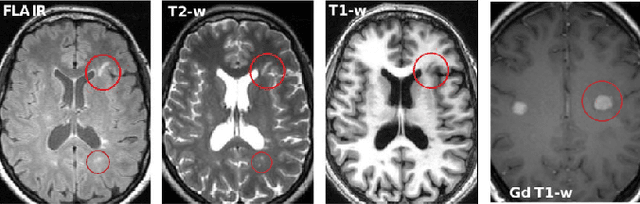
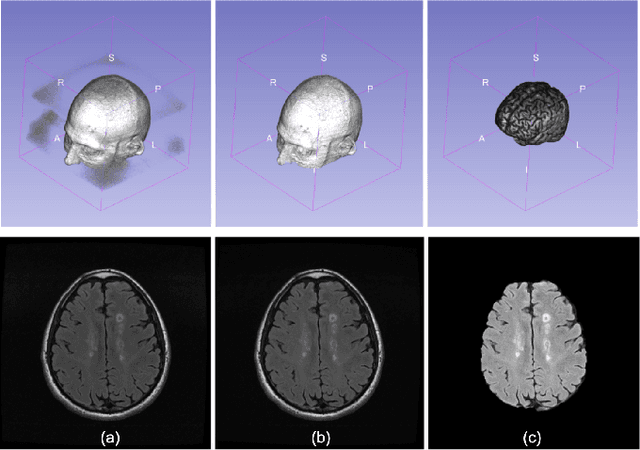
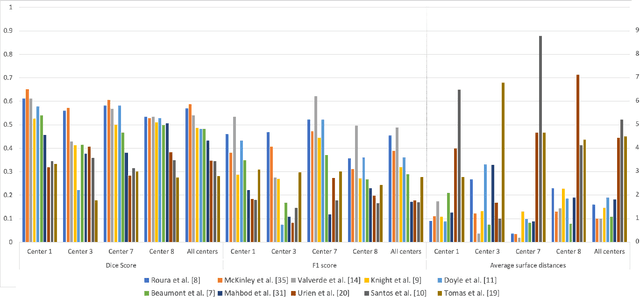
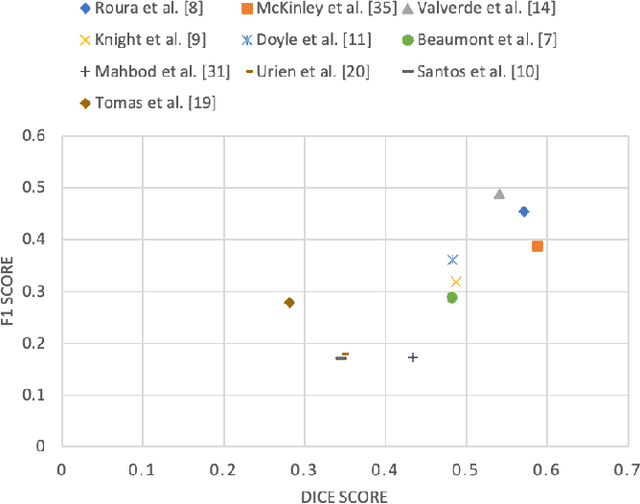
Multiple sclerosis (MS) is a chronic inflammatory and degenerative disease of the central nervous system, characterized by the appearance of focal lesions in the white and gray matter that topographically correlate with an individual patient's neurological symptoms and signs. Magnetic resonance imaging (MRI) provides detailed in-vivo structural information, permitting the quantification and categorization of MS lesions that critically inform disease management. Traditionally, MS lesions have been manually annotated on 2D MRI slices, a process that is inefficient and prone to inter-/intra-observer errors. Recently, automated statistical imaging analysis techniques have been proposed to extract and segment MS lesions based on MRI voxel intensity. However, their effectiveness is limited by the heterogeneity of both MRI data acquisition techniques and the appearance of MS lesions. By learning complex lesion representations directly from images, deep learning techniques have achieved remarkable breakthroughs in the MS lesion segmentation task. Here, we provide a comprehensive review of state-of-the-art automatic statistical and deep-learning MS segmentation methods and discuss current and future clinical applications. Further, we review technical strategies, such as domain adaptation, to enhance MS lesion segmentation in real-world clinical settings.
PILOT: A Pixel Intensity Driven Illuminant Color Estimation Framework for Color Constancy
Jun 25, 2018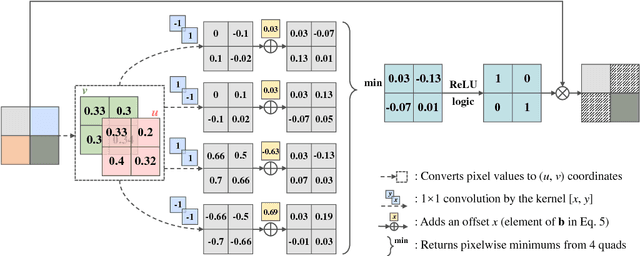
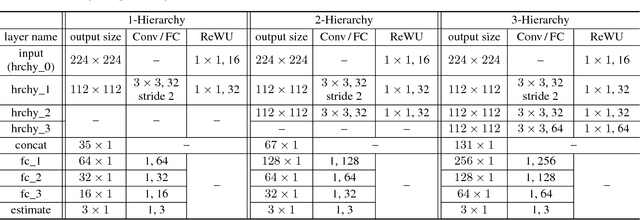
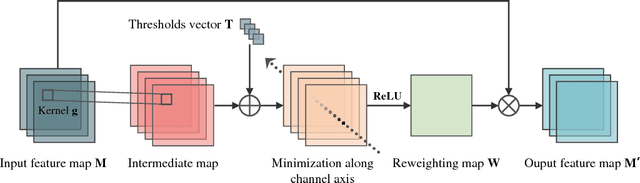
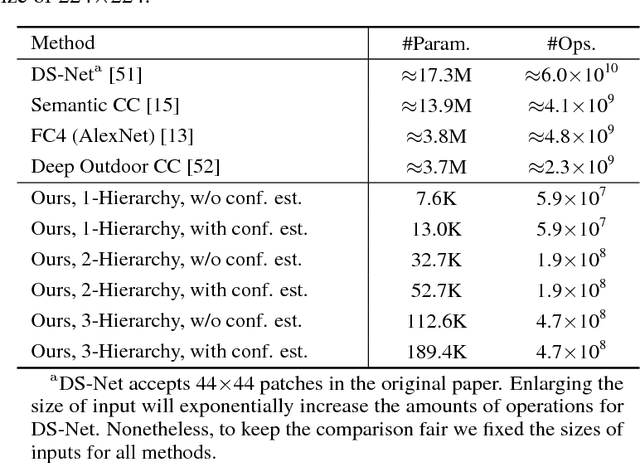
In this study, a CNN based Pixel Intensity driven iLluminant cOlor esTimation framework, PILOT, is proposed. The framework consists of a local illuminant estimation module and an illuminant uncertainty prediction module, obtained using a 3-phase training approach. The network with the well-designed microarchitecture of distillation building block and the macroarchitecture of bifurcated organization is of great representational capacity and efficacy for color-relevant vision tasks, which helps obtain a >20% relative improvement over prior algorithms and achieve state-of-the-art accuracy of illuminant estimation on benchmark datasets. The proposed framework is also computationally efficient and parameter-economic, making it suitable for applications deployed on mobile platforms. The great interpretability also makes PILOT possible to serve as a guidance for designing statistics-based models for those low-end devices with tight budgets of power consumption and computational capacity.