 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular PE-Structured Learning for Cross-Task Wireless Communications
Sep 10, 2025Recent trends in learning wireless policies attempt to develop deep neural networks (DNNs) for handling multiple tasks with a single model. Existing approaches often rely on large models, which are hard to pre-train and fine-tune at the wireless edge. In this work, we challenge this paradigm by leveraging the structured knowledge of wireless problems -- specifically, permutation equivariant (PE) properties. We design three types of PE-aware modules, two of which are Transformer-style sub-layers. These modules can serve as building blocks to assemble compact DNNs applicable to the wireless policies with various PE properties. To guide the design, we analyze the hypothesis space associated with each PE property, and show that the PE-structured module assembly can boost the learning efficiency. Inspired by the reusability of the modules, we propose PE-MoFormer, a compositional DNN capable of learning a wide range of wireless policies -- including but not limited to precoding, coordinated beamforming, power allocation, and channel estimation -- with strong generalizability, low sample and space complexity. Simulations demonstrate that the proposed modular PE-based framework outperforms relevant large model in both learning efficiency and inference time, offering a new direction for structured cross-task learning for wireless communications.
Understanding Prompt Programming Tasks and Questions
Jul 23, 2025Prompting foundation models (FMs) like large language models (LLMs) have enabled new AI-powered software features (e.g., text summarization) that previously were only possible by fine-tuning FMs. Now, developers are embedding prompts in software, known as prompt programs. The process of prompt programming requires the developer to make many changes to their prompt. Yet, the questions developers ask to update their prompt is unknown, despite the answers to these questions affecting how developers plan their changes. With the growing number of research and commercial prompt programming tools, it is unclear whether prompt programmers' needs are being adequately addressed. We address these challenges by developing a taxonomy of 25 tasks prompt programmers do and 51 questions they ask, measuring the importance of each task and question. We interview 16 prompt programmers, observe 8 developers make prompt changes, and survey 50 developers. We then compare the taxonomy with 48 research and commercial tools. We find that prompt programming is not well-supported: all tasks are done manually, and 16 of the 51 questions -- including a majority of the most important ones -- remain unanswered. Based on this, we outline important opportunities for prompt programming tools.
When Attention is Beneficial for Learning Wireless Resource Allocation Efficiently?
Jul 03, 2025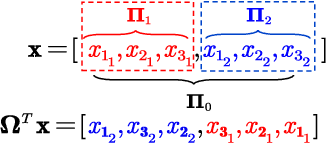
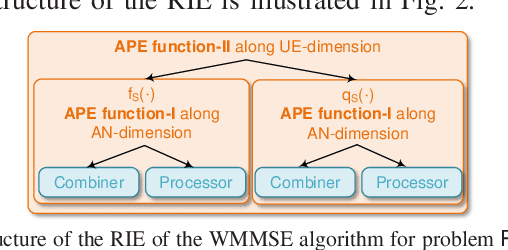
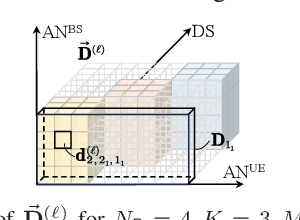
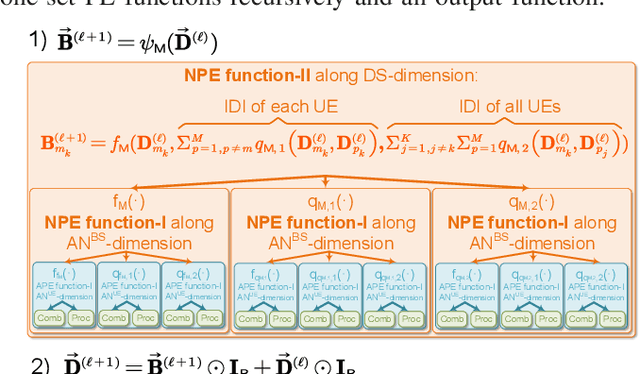
Owing to the use of attention mechanism to leverage the dependency across tokens, Transformers are efficient for natural language processing. By harnessing permutation properties broadly exist in resource allocation policies, each mapping measurable environmental parameters (e.g., channel matrix) to optimized variables (e.g., precoding matrix), graph neural networks (GNNs) are promising for learning these policies efficiently in terms of scalability and generalizability. To reap the benefits of both architectures, there is a recent trend of incorporating attention mechanism with GNNs for learning wireless policies. Nevertheless, is the attention mechanism really needed for resource allocation? In this paper, we strive to answer this question by analyzing the structures of functions defined on sets and numerical algorithms, given that the permutation properties of wireless policies are induced by the involved sets (say user set). In particular, we prove that the permutation equivariant functions on a single set can be recursively expressed by two types of functions: one involves attention, and the other does not. We proceed to re-express the numerical algorithms for optimizing several representative resource allocation problems in recursive forms. We find that when interference (say multi-user or inter-data stream interference) is not reflected in the measurable parameters of a policy, attention needs to be used to model the interference. With the insight, we establish a framework of designing GNNs by aligning with the structures. By taking reconfigurable intelligent surface-aided hybrid precoding as an example, the learning efficiency of the proposed GNN is validated via simulations.
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
May 19, 2025Building LLM-powered software requires developers to communicate their requirements through natural language, but developer prompts are frequently underspecified, failing to fully capture many user-important requirements. In this paper, we present an in-depth analysis of prompt underspecification, showing that while LLMs can often (41.1%) guess unspecified requirements by default, such behavior is less robust: Underspecified prompts are 2x more likely to regress over model or prompt changes, sometimes with accuracy drops by more than 20%. We then demonstrate that simply adding more requirements to a prompt does not reliably improve performance, due to LLMs' limited instruction-following capabilities and competing constraints, and standard prompt optimizers do not offer much help. To address this, we introduce novel requirements-aware prompt optimization mechanisms that can improve performance by 4.8% on average over baselines that naively specify everything in the prompt. Beyond prompt optimization, we envision that effectively managing prompt underspecification requires a broader process, including proactive requirements discovery, evaluation, and monitoring.
Precoder Learning by Leveraging Unitary Equivariance Property
Mar 12, 2025Incorporating mathematical properties of a wireless policy to be learned into the design of deep neural networks (DNNs) is effective for enhancing learning efficiency. Multi-user precoding policy in multi-antenna system, which is the mapping from channel matrix to precoding matrix, possesses a permutation equivariance property, which has been harnessed to design the parameter sharing structure of the weight matrix of DNNs. In this paper, we study a stronger property than permutation equivariance, namely unitary equivariance, for precoder learning. We first show that a DNN with unitary equivariance designed by further introducing parameter sharing into a permutation equivariant DNN is unable to learn the optimal precoder. We proceed to develop a novel non-linear weighting process satisfying unitary equivariance and then construct a joint unitary and permutation equivariant DNN. Simulation results demonstrate that the proposed DNN not only outperforms existing learning methods in learning performance and generalizability but also reduces training complexity.
Quantization Design for Deep Learning-Based CSI Feedback
Mar 11, 2025Deep learning-based autoencoders have been employed to compress and reconstruct channel state information (CSI) in frequency-division duplex systems. Practical implementations require judicious quantization of encoder outputs for digital transmission. In this paper, we propose a novel quantization module with bit allocation among encoder outputs and develop a method for joint training the module and the autoencoder. To enhance learning performance, we design a loss function that adaptively weights the quantization loss and the logarithm of reconstruction loss. Simulation results show the performance gain of the proposed method over existing baselines.
Distributed Resource Block Allocation for Wideband Cell-free System
Mar 10, 2025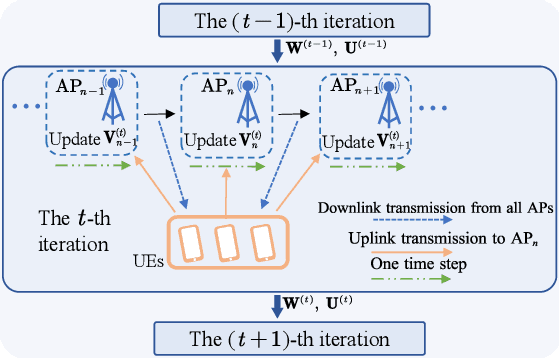
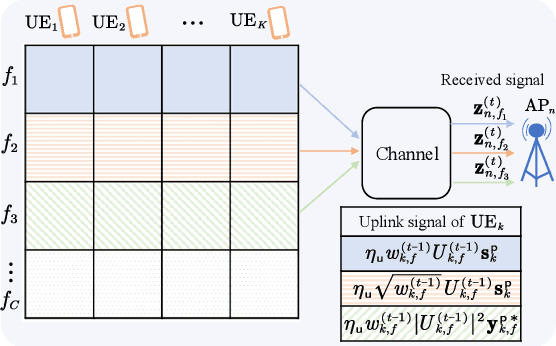
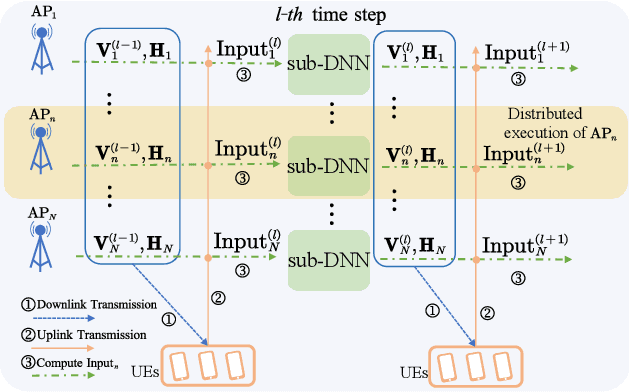
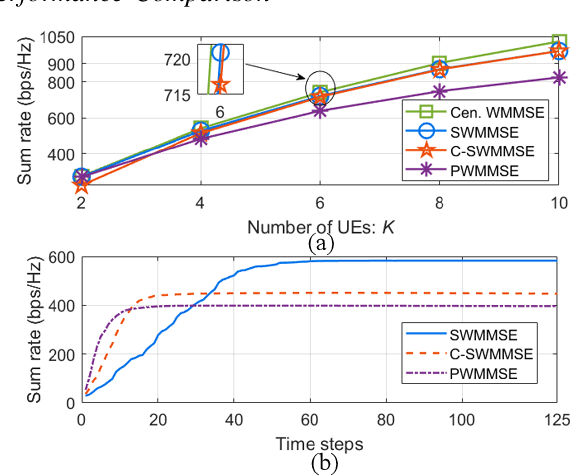
This paper studies distributed resource block (RB) allocation in wideband orthogonal frequency-division multiplexing (OFDM) cell-free systems. We propose a novel distributed sequential algorithm and its two variants, which optimize RB allocation based on the information obtained through over-the-air (OTA) transmissions between access points (APs) and user equipments, enabling local decision updates at each AP. To reduce the overhead of OTA transmission, we further develop a distributed deep learning (DL)-based method to learn the RB allocation policy. Simulation results demonstrate that the proposed distributed algorithms perform close to the centralized algorithm, while the DL-based method outperforms existing baseline methods.
Learning of Uplink Resource Allocation with Multiuser QoS Constraints
Mar 09, 2025In the paper the joint optimization of uplink multiuser power and resource block (RB) allocation are studied, where each user has quality of service (QoS) constraints on both long- and short-blocklength transmissions. The objective is to minimize the consumption of RBs for meeting the QoS requirements, leading to a mixed-integer nonlinear programming (MINLP) problem. We resort to deep learning to solve the problem with low inference complexity. To provide a performance benchmark for learning based methods, we propose a hierarchical algorithm to find the global optimal solution in the single-user scenario, which is then extended to the multiuser scenario. The design of the learning method, however, is challenging due to the discrete policy to be learned, which results in either vanishing or exploding gradient during neural network training. We introduce two types of smoothing functions to approximate the involved discretizing processes and propose a smoothing parameter adaption method. Another critical challenge lies in guaranteeing the QoS constraints. To address it, we design a nonlinear function to intensify the penalties for minor constraint violations. Simulation results demonstrate the advantages of the proposed method in reducing the number of occupied RBs and satisfying QoS constraints reliably.
Gradient-Driven Graph Neural Networks for Learning Digital and Hybrid Precoder
Mar 08, 2025The optimization of multi-user multi-input multi-output (MU-MIMO) precoders is a widely recognized challenging problem. Existing work has demonstrated the potential of graph neural networks (GNNs) in learning precoding policies. However, existing GNNs often exhibit poor generalizability for the numbers of users or antennas. In this paper, we develop a gradient-driven GNN design method for the learning of fully digital and hybrid precoding policies. The proposed GNNs leverage two kinds of knowledge, namely the gradient of signal-to-interference-plus-noise ratio (SINR) to the precoders and the permutation equivariant property of the precoding policy. To demonstrate the flexibility of the proposed method for accommodating different optimization objectives and different precoding policies, we first apply the proposed method to learn the fully digital precoding policies. We study two precoder optimization problems for spectral efficiency (SE) maximization and log-SE maximization to achieve proportional fairness. We then apply the proposed method to learn the hybrid precoding policy, where the gradients to analog and digital precoders are exploited for the design of the GNN. Simulation results show the effectiveness of the proposed methods for learning different precoding policies and better generalization performance to the numbers of both users and antennas compared to baseline GNNs.
Learning Wideband User Scheduling and Hybrid Precoding with Graph Neural Networks
Mar 06, 2025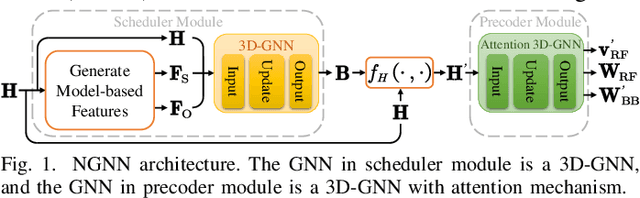
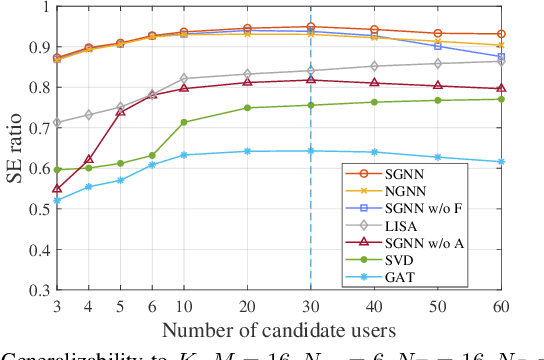
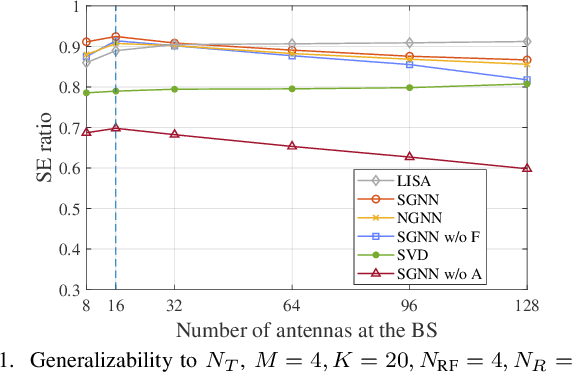

Spatial-frequency scheduling and hybrid precoding in wideband multi-user multi-antenna systems have never been learned jointly due to the challenges arising from the massive user combinations on resource blocks (RBs) and the shared analog precoder among RBs. In this paper, we strive to jointly learn the scheduling and precoding policies with graph neural networks (GNNs), which have emerged as a powerful tool for optimizing resource allocation thanks to their potential in generalizing across problem scales. By reformulating the joint optimization problem into an equivalent functional optimization problem for the scheduling and precoding policies, we propose a GNN-based architecture consisting of two cascaded modules to learn the two policies. We discover a same-parameter same-decision (SPSD) property for wireless policies defined on sets, revealing that a GNN cannot well learn the optimal scheduling policy when users have similar channels. This motivates us to develop a sequence of GNNs to enhance the scheduling module. Furthermore, by analyzing the SPSD property, we find when linear aggregators in GNNs impede size generalization. Based on the observation, we devise a novel attention mechanism for information aggregation in the precoder module. Simulation results demonstrate that the proposed architecture achieves satisfactory spectral efficiency with short inference time and low training complexity, and is generalizable to the numbers of users, RBs, and antennas at the base station and users.