 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Scaling Law for Quantization-Aware Training
May 20, 2025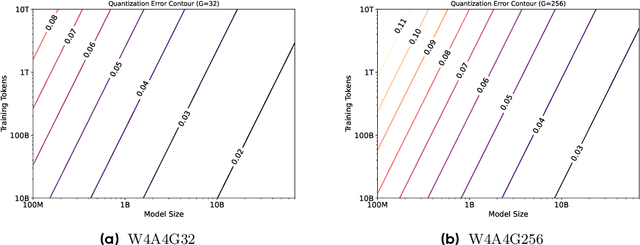
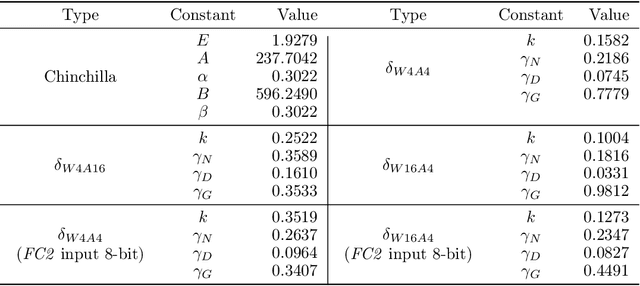
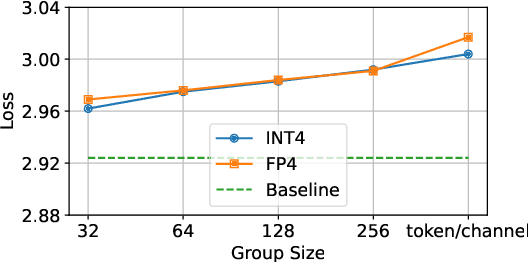
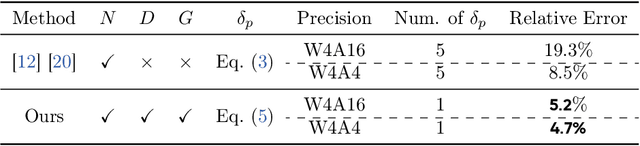
Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
Through the Magnifying Glass: Adaptive Perception Magnification for Hallucination-Free VLM Decoding
Mar 13, 2025Existing vision-language models (VLMs) often suffer from visual hallucination, where the generated responses contain inaccuracies that are not grounded in the visual input. Efforts to address this issue without model finetuning primarily mitigate hallucination by reducing biases contrastively or amplifying the weights of visual embedding during decoding. However, these approaches improve visual perception at the cost of impairing the language reasoning capability. In this work, we propose the Perception Magnifier (PM), a novel visual decoding method that iteratively isolates relevant visual tokens based on attention and magnifies the corresponding regions, spurring the model to concentrate on fine-grained visual details during decoding. Specifically, by magnifying critical regions while preserving the structural and contextual information at each decoding step, PM allows the VLM to enhance its scrutiny of the visual input, hence producing more accurate and faithful responses. Extensive experimental results demonstrate that PM not only achieves superior hallucination mitigation but also enhances language generation while preserving strong reasoning capabilities.Code is available at https://github.com/ShunqiM/PM .
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Feb 18, 2025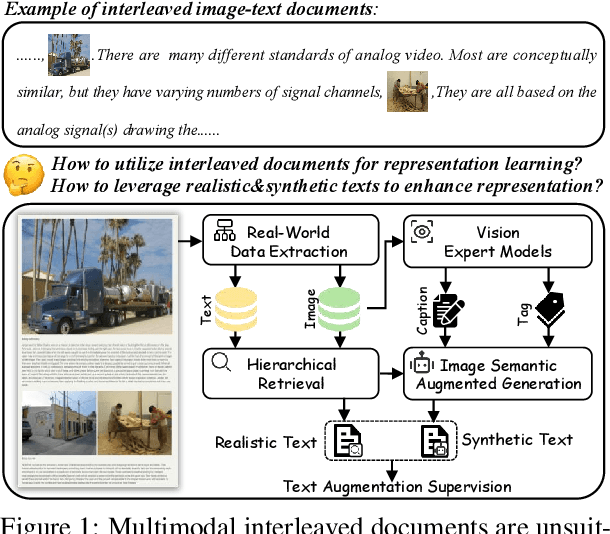
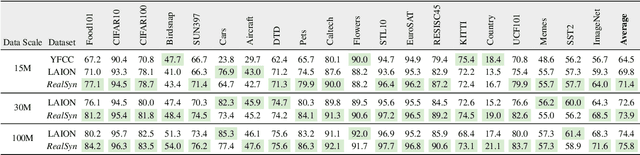


After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of non-paired data, such as multimodal interleaved documents, remains underutilized for vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. Extensive experiments demonstrate that RealSyn effectively advances vision-language representation learning and exhibits strong scalability. Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks. To facilitate future research, the RealSyn dataset and pre-trained model weights are released at https://github.com/deepglint/RealSyn.
Learning to Synthesize Graphics Programs for Geometric Artworks
Oct 21, 2024



Creating and understanding art has long been a hallmark of human ability. When presented with finished digital artwork, professional graphic artists can intuitively deconstruct and replicate it using various drawing tools, such as the line tool, paint bucket, and layer features, including opacity and blending modes. While most recent research in this field has focused on art generation, proposing a range of methods, these often rely on the concept of artwork being represented as a final image. To bridge the gap between pixel-level results and the actual drawing process, we present an approach that treats a set of drawing tools as executable programs. This method predicts a sequence of steps to achieve the final image, allowing for understandable and resolution-independent reproductions under the usage of a set of drawing commands. Our experiments demonstrate that our program synthesizer, Art2Prog, can comprehensively understand complex input images and reproduce them using high-quality executable programs. The experimental results evidence the potential of machines to grasp higher-level information from images and generate compact program-level descriptions.
DeepIcon: A Hierarchical Network for Layer-wise Icon Vectorization
Oct 21, 2024



In contrast to the well-established technique of rasterization, vectorization of images poses a significant challenge in the field of computer graphics. Recent learning-based methods for converting raster images to vector formats frequently suffer from incomplete shapes, redundant path prediction, and a lack of accuracy in preserving the semantics of the original content. These shortcomings severely hinder the utility of these methods for further editing and manipulation of images. To address these challenges, we present DeepIcon, a novel hierarchical image vectorization network specifically tailored for generating variable-length icon vector graphics based on the raster image input. Our experimental results indicate that DeepIcon can efficiently produce Scalable Vector Graphics (SVGs) directly from raster images, bypassing the need for a differentiable rasterizer while also demonstrating a profound understanding of the image contents.
Enhancing Advanced Visual Reasoning Ability of Large Language Models
Sep 21, 2024



Recent advancements in Vision-Language (VL) research have sparked new benchmarks for complex visual reasoning, challenging models' advanced reasoning ability. Traditional Vision-Language Models (VLMs) perform well in visual perception tasks while struggling with complex reasoning scenarios. Conversely, Large Language Models (LLMs) demonstrate robust text reasoning capabilities; however, they lack visual acuity. To bridge this gap, we propose Complex Visual Reasoning Large Language Models (CVR-LLM), capitalizing on VLMs' visual perception proficiency and LLMs' extensive reasoning capability. Unlike recent multimodal large language models (MLLMs) that require a projection layer, our approach transforms images into detailed, context-aware descriptions using an iterative self-refinement loop and leverages LLMs' text knowledge for accurate predictions without extra training. We also introduce a novel multi-modal in-context learning (ICL) methodology to enhance LLMs' contextual understanding and reasoning. Additionally, we introduce Chain-of-Comparison (CoC), a step-by-step comparison technique enabling contrasting various aspects of predictions. Our CVR-LLM presents the first comprehensive study across a wide array of complex visual reasoning tasks and achieves SOTA performance among all.
Multimodal Causal Reasoning Benchmark: Challenging Vision Large Language Models to Infer Causal Links Between Siamese Images
Aug 15, 2024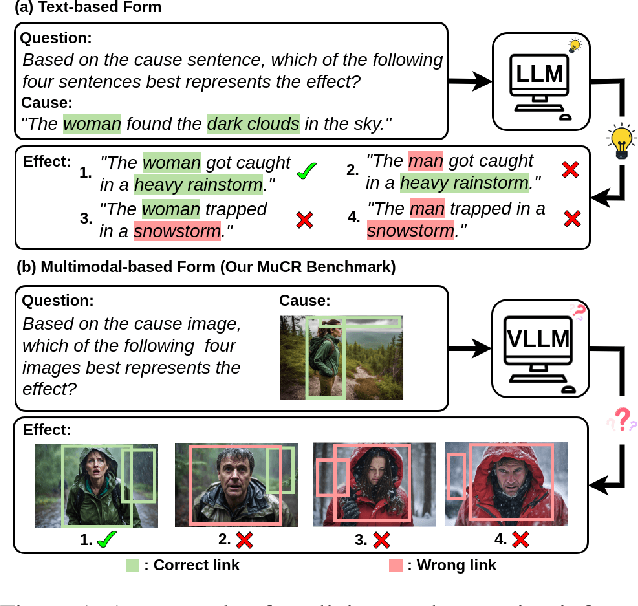
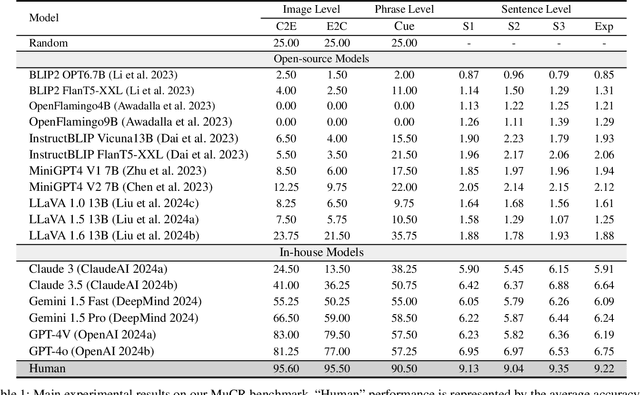
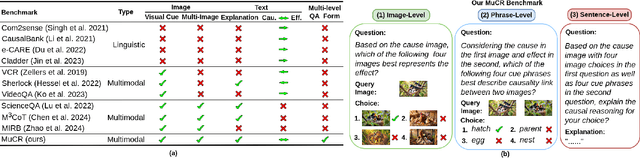
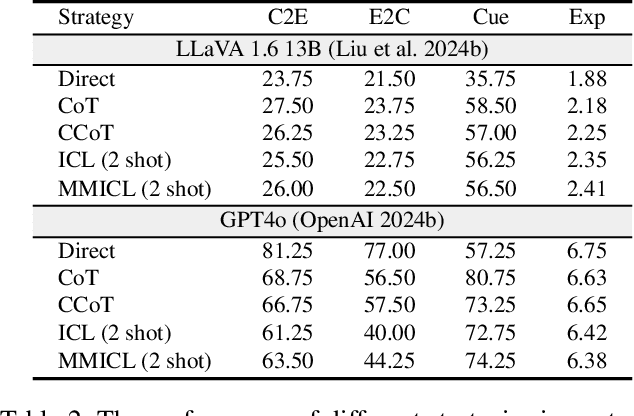
Large Language Models (LLMs) have showcased exceptional ability in causal reasoning from textual information. However, will these causalities remain straightforward for Vision Large Language Models (VLLMs) when only visual hints are provided? Motivated by this, we propose a novel Multimodal Causal Reasoning benchmark, namely MuCR, to challenge VLLMs to infer semantic cause-and-effect relationship when solely relying on visual cues such as action, appearance, clothing, and environment. Specifically, we introduce a prompt-driven image synthesis approach to create siamese images with embedded semantic causality and visual cues, which can effectively evaluate VLLMs' causal reasoning capabilities. Additionally, we develop tailored metrics from multiple perspectives, including image-level match, phrase-level understanding, and sentence-level explanation, to comprehensively assess VLLMs' comprehension abilities. Our extensive experiments reveal that the current state-of-the-art VLLMs are not as skilled at multimodal causal reasoning as we might have hoped. Furthermore, we perform a comprehensive analysis to understand these models' shortcomings from different views and suggest directions for future research. We hope MuCR can serve as a valuable resource and foundational benchmark in multimodal causal reasoning research. The project is available at: https://github.com/Zhiyuan-Li-John/MuCR
Controllable Contextualized Image Captioning: Directing the Visual Narrative through User-Defined Highlights
Jul 16, 2024Contextualized Image Captioning (CIC) evolves traditional image captioning into a more complex domain, necessitating the ability for multimodal reasoning. It aims to generate image captions given specific contextual information. This paper further introduces a novel domain of Controllable Contextualized Image Captioning (Ctrl-CIC). Unlike CIC, which solely relies on broad context, Ctrl-CIC accentuates a user-defined highlight, compelling the model to tailor captions that resonate with the highlighted aspects of the context. We present two approaches, Prompting-based Controller (P-Ctrl) and Recalibration-based Controller (R-Ctrl), to generate focused captions. P-Ctrl conditions the model generation on highlight by prepending captions with highlight-driven prefixes, whereas R-Ctrl tunes the model to selectively recalibrate the encoder embeddings for highlighted tokens. Additionally, we design a GPT-4V empowered evaluator to assess the quality of the controlled captions alongside standard assessment methods. Extensive experimental results demonstrate the efficient and effective controllability of our method, charting a new direction in achieving user-adaptive image captioning. Code is available at https://github.com/ShunqiM/Ctrl-CIC .