 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Causal Reasoning Benchmark: Challenging Vision Large Language Models to Infer Causal Links Between Siamese Images
Paper and Code
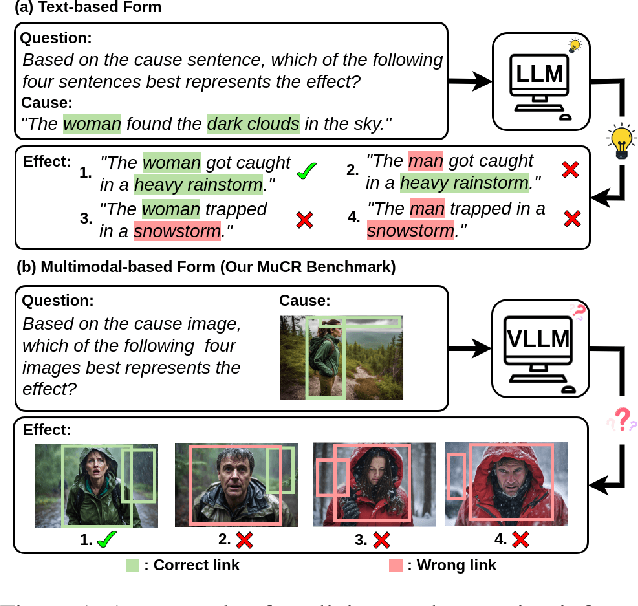
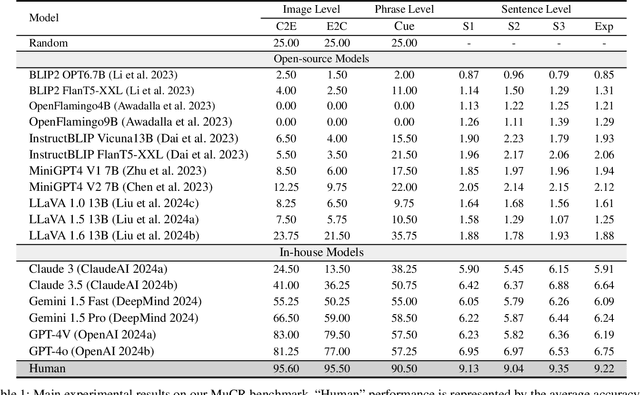
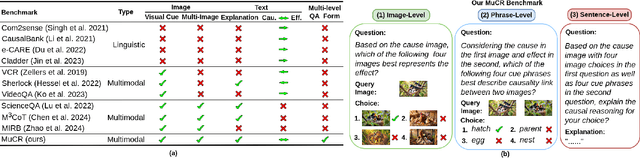
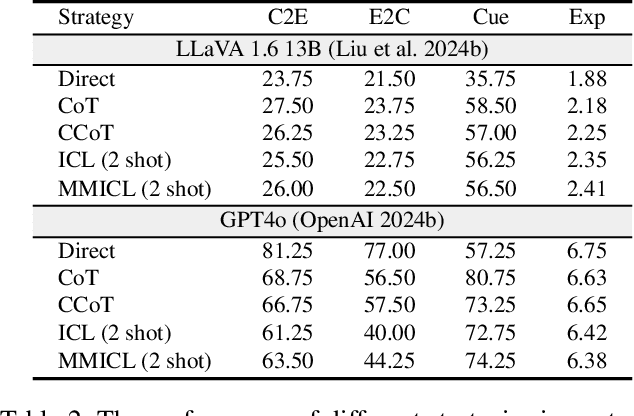
Large Language Models (LLMs) have showcased exceptional ability in causal reasoning from textual information. However, will these causalities remain straightforward for Vision Large Language Models (VLLMs) when only visual hints are provided? Motivated by this, we propose a novel Multimodal Causal Reasoning benchmark, namely MuCR, to challenge VLLMs to infer semantic cause-and-effect relationship when solely relying on visual cues such as action, appearance, clothing, and environment. Specifically, we introduce a prompt-driven image synthesis approach to create siamese images with embedded semantic causality and visual cues, which can effectively evaluate VLLMs' causal reasoning capabilities. Additionally, we develop tailored metrics from multiple perspectives, including image-level match, phrase-level understanding, and sentence-level explanation, to comprehensively assess VLLMs' comprehension abilities. Our extensive experiments reveal that the current state-of-the-art VLLMs are not as skilled at multimodal causal reasoning as we might have hoped. Furthermore, we perform a comprehensive analysis to understand these models' shortcomings from different views and suggest directions for future research. We hope MuCR can serve as a valuable resource and foundational benchmark in multimodal causal reasoning research. The project is available at: https://github.com/Zhiyuan-Li-John/MuCR