 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Streaming Flow Models for Adapting Learned Robot Trajectory Distributions
Feb 17, 2026Robot motion distributions often exhibit multi-modality and require flexible generative models for accurate representation. Streaming Flow Policies (SFPs) have recently emerged as a powerful paradigm for generating robot trajectories by integrating learned velocity fields directly in action space, enabling smooth and reactive control. However, existing formulations lack mechanisms for adapting trajectories post-training to enforce safety and task-specific constraints. We propose Constraint-Aware Streaming Flow (CASF), a framework that augments streaming flow policies with constraint-dependent metrics that reshape the learned velocity field during execution. CASF models each constraint, defined in either the robot's workspace or configuration space, as a differentiable distance function that is converted into a local metric and pulled back into the robot's control space. Far from restricted regions, the resulting metric reduces to the identity; near constraint boundaries, it smoothly attenuates or redirects motion, effectively deforming the underlying flow to maintain safety. This allows trajectories to be adapted in real time, ensuring that robot actions respect joint limits, avoid collisions, and remain within feasible workspaces, while preserving the multi-modal and reactive properties of streaming flow policies. We demonstrate CASF in simulated and real-world manipulation tasks, showing that it produces constraint-satisfying trajectories that remain smooth, feasible, and dynamically consistent, outperforming standard post-hoc projection baselines.
Multimodal Causal Reasoning Benchmark: Challenging Vision Large Language Models to Infer Causal Links Between Siamese Images
Aug 15, 2024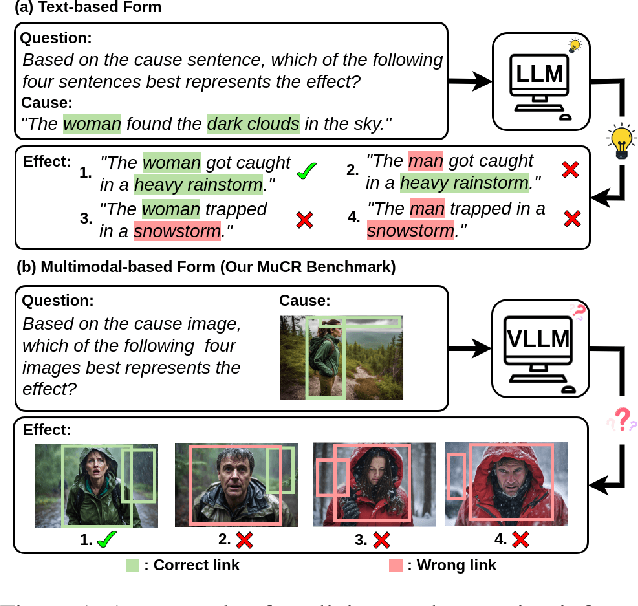
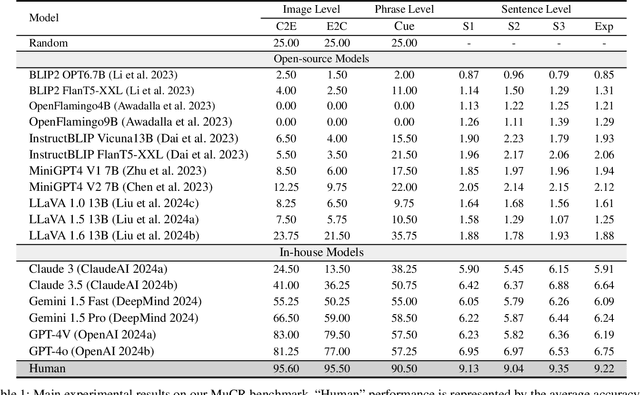
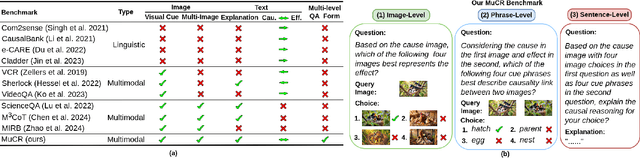
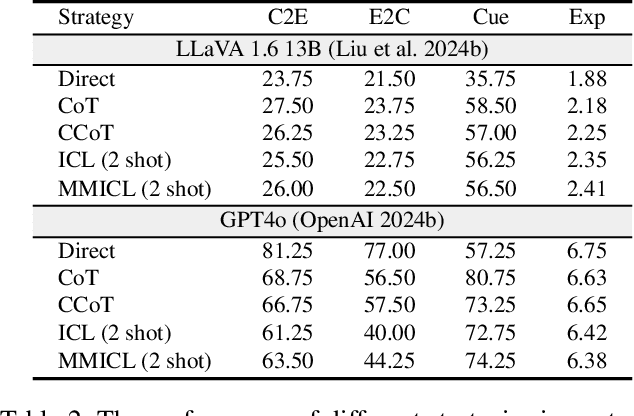
Large Language Models (LLMs) have showcased exceptional ability in causal reasoning from textual information. However, will these causalities remain straightforward for Vision Large Language Models (VLLMs) when only visual hints are provided? Motivated by this, we propose a novel Multimodal Causal Reasoning benchmark, namely MuCR, to challenge VLLMs to infer semantic cause-and-effect relationship when solely relying on visual cues such as action, appearance, clothing, and environment. Specifically, we introduce a prompt-driven image synthesis approach to create siamese images with embedded semantic causality and visual cues, which can effectively evaluate VLLMs' causal reasoning capabilities. Additionally, we develop tailored metrics from multiple perspectives, including image-level match, phrase-level understanding, and sentence-level explanation, to comprehensively assess VLLMs' comprehension abilities. Our extensive experiments reveal that the current state-of-the-art VLLMs are not as skilled at multimodal causal reasoning as we might have hoped. Furthermore, we perform a comprehensive analysis to understand these models' shortcomings from different views and suggest directions for future research. We hope MuCR can serve as a valuable resource and foundational benchmark in multimodal causal reasoning research. The project is available at: https://github.com/Zhiyuan-Li-John/MuCR
Jaeger: A Concatenation-Based Multi-Transformer VQA Model
Oct 19, 2023

Document-based Visual Question Answering poses a challenging task between linguistic sense disambiguation and fine-grained multimodal retrieval. Although there has been encouraging progress in document-based question answering due to the utilization of large language and open-world prior models\cite{1}, several challenges persist, including prolonged response times, extended inference durations, and imprecision in matching. In order to overcome these challenges, we propose Jaegar, a concatenation-based multi-transformer VQA model. To derive question features, we leverage the exceptional capabilities of RoBERTa large\cite{2} and GPT2-xl\cite{3} as feature extractors. Subsequently, we subject the outputs from both models to a concatenation process. This operation allows the model to consider information from diverse sources concurrently, strengthening its representational capability. By leveraging pre-trained models for feature extraction, our approach has the potential to amplify the performance of these models through concatenation. After concatenation, we apply dimensionality reduction to the output features, reducing the model's computational effectiveness and inference time. Empirical results demonstrate that our proposed model achieves competitive performance on Task C of the PDF-VQA Dataset. If the user adds any new data, they should make sure to style it as per the instructions provided in previous sections.