 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
Tighnari: Multi-modal Plant Species Prediction Based on Hierarchical Cross-Attention Using Graph-Based and Vision Backbone-Extracted Features
Jan 05, 2025



Predicting plant species composition in specific spatiotemporal contexts plays an important role in biodiversity management and conservation, as well as in improving species identification tools. Our work utilizes 88,987 plant survey records conducted in specific spatiotemporal contexts across Europe. We also use the corresponding satellite images, time series data, climate time series, and other rasterized environmental data such as land cover, human footprint, bioclimatic, and soil variables as training data to train the model to predict the outcomes of 4,716 plant surveys. We propose a feature construction and result correction method based on the graph structure. Through comparative experiments, we select the best-performing backbone networks for feature extraction in both temporal and image modalities. In this process, we built a backbone network based on the Swin-Transformer Block for extracting temporal Cubes features. We then design a hierarchical cross-attention mechanism capable of robustly fusing features from multiple modalities. During training, we adopt a 10-fold cross-fusion method based on fine-tuning and use a Threshold Top-K method for post-processing. Ablation experiments demonstrate the improvements in model performance brought by our proposed solution pipeline.
Google is all you need: Semi-Supervised Transfer Learning Strategy For Light Multimodal Multi-Task Classification Model
Jan 03, 2025


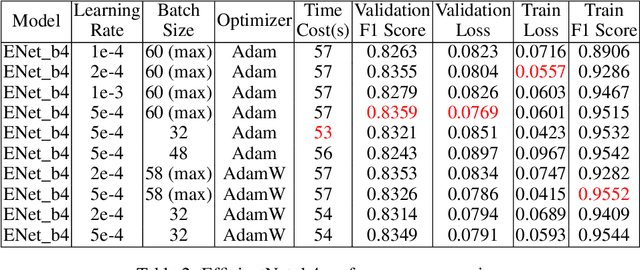
As the volume of digital image data increases, the effectiveness of image classification intensifies. This study introduces a robust multi-label classification system designed to assign multiple labels to a single image, addressing the complexity of images that may be associated with multiple categories (ranging from 1 to 19, excluding 12). We propose a multi-modal classifier that merges advanced image recognition algorithms with Natural Language Processing (NLP) models, incorporating a fusion module to integrate these distinct modalities. The purpose of integrating textual data is to enhance the accuracy of label prediction by providing contextual understanding that visual analysis alone cannot fully capture. Our proposed classification model combines Convolutional Neural Networks (CNN) for image processing with NLP techniques for analyzing textual description (i.e., captions). This approach includes rigorous training and validation phases, with each model component verified and analyzed through ablation experiments. Preliminary results demonstrate the classifier's accuracy and efficiency, highlighting its potential as an automatic image-labeling system.
Multi-Modal Video Feature Extraction for Popularity Prediction
Jan 02, 2025This work aims to predict the popularity of short videos using the videos themselves and their related features. Popularity is measured by four key engagement metrics: view count, like count, comment count, and share count. This study employs video classification models with different architectures and training methods as backbone networks to extract video modality features. Meanwhile, the cleaned video captions are incorporated into a carefully designed prompt framework, along with the video, as input for video-to-text generation models, which generate detailed text-based video content understanding. These texts are then encoded into vectors using a pre-trained BERT model. Based on the six sets of vectors mentioned above, a neural network is trained for each of the four prediction metrics. Moreover, the study conducts data mining and feature engineering based on the video and tabular data, constructing practical features such as the total frequency of hashtag appearances, the total frequency of mention appearances, video duration, frame count, frame rate, and total time online. Multiple machine learning models are trained, and the most stable model, XGBoost, is selected. Finally, the predictions from the neural network and XGBoost models are averaged to obtain the final result.
Unveiling and Controlling Anomalous Attention Distribution in Transformers
Jun 26, 2024With the advent of large models based on the Transformer architecture, researchers have observed an anomalous phenomenon in the Attention mechanism--there is a very high attention on the first element, which is prevalent across Transformer-based models. It is crucial to understand it for the development of techniques focusing on attention distribution, such as Key-Value (KV) Cache compression and infinite extrapolation; however, the latent cause leaves to be unknown. In this paper, we analyze such a phenomenon from the perspective of waiver phenomenon, which involves reducing the internal values of certain elements in the Softmax function, allowing them to absorb excess attention without affecting their contribution to information. In specific models, due to differences in positional encoding and attention patterns, we have found that the selection of waiver elements by the model can be categorized into two methods: positional-encoding-based and feature-distribution-within-elements-based.
Jaeger: A Concatenation-Based Multi-Transformer VQA Model
Oct 19, 2023

Document-based Visual Question Answering poses a challenging task between linguistic sense disambiguation and fine-grained multimodal retrieval. Although there has been encouraging progress in document-based question answering due to the utilization of large language and open-world prior models\cite{1}, several challenges persist, including prolonged response times, extended inference durations, and imprecision in matching. In order to overcome these challenges, we propose Jaegar, a concatenation-based multi-transformer VQA model. To derive question features, we leverage the exceptional capabilities of RoBERTa large\cite{2} and GPT2-xl\cite{3} as feature extractors. Subsequently, we subject the outputs from both models to a concatenation process. This operation allows the model to consider information from diverse sources concurrently, strengthening its representational capability. By leveraging pre-trained models for feature extraction, our approach has the potential to amplify the performance of these models through concatenation. After concatenation, we apply dimensionality reduction to the output features, reducing the model's computational effectiveness and inference time. Empirical results demonstrate that our proposed model achieves competitive performance on Task C of the PDF-VQA Dataset. If the user adds any new data, they should make sure to style it as per the instructions provided in previous sections.
Device Tuning for Multi-Task Large Model
Feb 21, 2023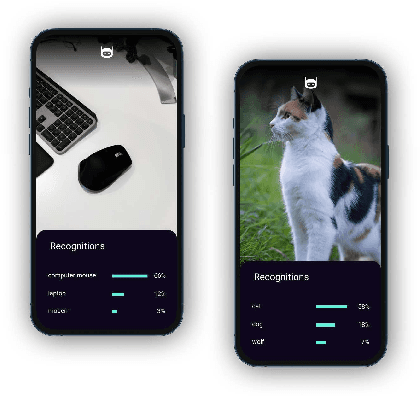

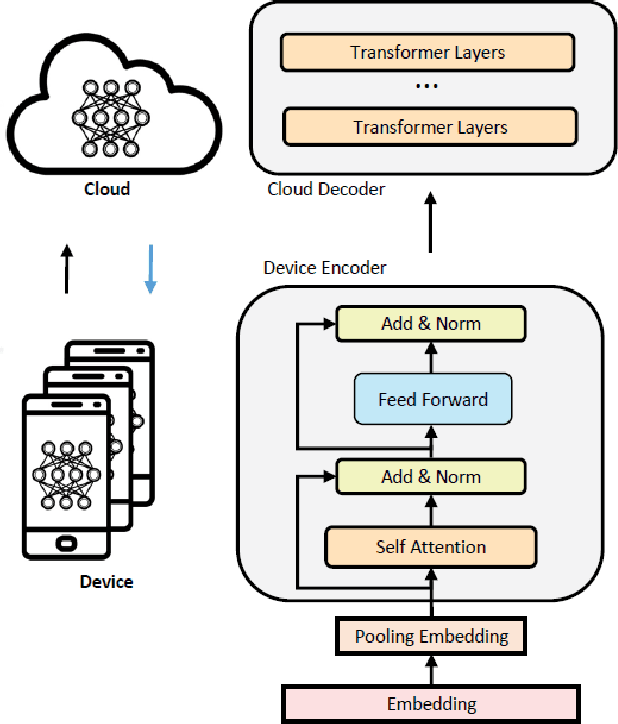
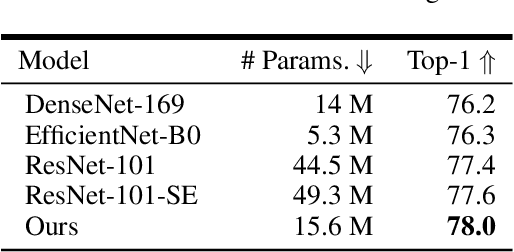
Unsupervised pre-training approaches have achieved great success in many fields such as Computer Vision (CV), Natural Language Processing (NLP) and so on. However, compared to typical deep learning models, pre-training or even fine-tuning the state-of-the-art self-attention models is extremely expensive, as they require much more computational and memory resources. It severely limits their applications and success in a variety of domains, especially for multi-task learning. To improve the efficiency, we propose Device Tuning for the efficient multi-task model, which is a massively multitask framework across the cloud and device and is designed to encourage learning of representations that generalize better to many different tasks. Specifically, we design Device Tuning architecture of a multi-task model that benefits both cloud modelling and device modelling, which reduces the communication between device and cloud by representation compression. Experimental results demonstrate the effectiveness of our proposed method.
Deep Transfer Tensor Factorization for Multi-View Learning
Feb 13, 2023This paper studies the data sparsity problem in multi-view learning. To solve data sparsity problem in multiview ratings, we propose a generic architecture of deep transfer tensor factorization (DTTF) by integrating deep learning and cross-domain tensor factorization, where the side information is embedded to provide effective compensation for the tensor sparsity. Then we exhibit instantiation of our architecture by combining stacked denoising autoencoder (SDAE) and CANDECOMP/ PARAFAC (CP) tensor factorization in both source and target domains, where the side information of both users and items is tightly coupled with the sparse multi-view ratings and the latent factors are learned based on the joint optimization. We tightly couple the multi-view ratings and the side information to improve cross-domain tensor factorization based recommendations. Experimental results on real-world datasets demonstrate that our DTTF schemes outperform state-of-the-art methods on multi-view rating predictions.
Robust Meta Learning for Image based tasks
Jan 30, 2023


A machine learning model that generalizes well should obtain low errors on unseen test examples. Thus, if we learn an optimal model in training data, it could have better generalization performance in testing tasks. However, learning such a model is not possible in standard machine learning frameworks as the distribution of the test data is unknown. To tackle this challenge, we propose a novel robust meta-learning method, which is more robust to the image-based testing tasks which is unknown and has distribution shifts with training tasks. Our robust meta-learning method can provide robust optimal models even when data from each distribution are scarce. In experiments, we demonstrate that our algorithm not only has better generalization performance but also robust to different unknown testing tasks.
Invariant Meta Learning for Out-of-Distribution Generalization
Jan 26, 2023Modern deep learning techniques have illustrated their excellent capabilities in many areas, but relies on large training data. Optimization-based meta-learning train a model on a variety tasks, such that it can solve new learning tasks using only a small number of training samples.However, these methods assumes that training and test dataare identically and independently distributed. To overcome such limitation, in this paper, we propose invariant meta learning for out-of-distribution tasks. Specifically, invariant meta learning find invariant optimal meta-initialization,and fast adapt to out-of-distribution tasks with regularization penalty. Extensive experiments demonstrate the effectiveness of our proposed invariant meta learning on out-of-distribution few-shot tasks.