 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUTEv2: Unified and Configurable Matrix Extension for Diverse CPU Architectures with Minimal Design Overhead
Apr 13, 2026Matrix extensions have emerged as an essential feature in modern CPUs to address the surging demands of AI workloads. However, existing designs often incur substantial hardware and software design overhead. Tight coupling with the CPU pipeline complicates integration across diverse CPUs, while fine-grained synchronous instructions hinder the development of high-performance kernels. This paper proposes a unified and configurable CPU matrix extension architecture. By decoupling matrix units from the CPU pipeline, the design enables low-overhead integration while maintaining close coordination with existing compute and memory resources. The configurable matrix unit supports mixed-precision operations and adapts to diverse compute demands and memory bandwidth constraints. An asynchronous matrix multiplication abstraction with flexible granularity conceals hardware details, simplifies matrix-vector overlap, and supports a unified software stack. The architecture is integrated into four open-source CPU RTL platforms and evaluated on representative AI models. Matrix unit utilization under GEMM workloads exceeds 90% across all platforms. When configured with compute throughput and memory bandwidth comparable to Intel AMX, our design achieves speedups of 1.57x, 1.57x, and 2.31x on ResNet, BERT, and Llama3, with over 30% of the gains attributed to overlapped matrix-vector execution. A 4 TOPS@2GHz matrix unit occupies only 0.53 mm\textsuperscript{2} in 14nm CMOS. These results demonstrate strong cross-platform adaptability and effective hardware-software co-optimization, offering a practical matrix extension for the open-source community.
Unveiling and Controlling Anomalous Attention Distribution in Transformers
Jun 26, 2024With the advent of large models based on the Transformer architecture, researchers have observed an anomalous phenomenon in the Attention mechanism--there is a very high attention on the first element, which is prevalent across Transformer-based models. It is crucial to understand it for the development of techniques focusing on attention distribution, such as Key-Value (KV) Cache compression and infinite extrapolation; however, the latent cause leaves to be unknown. In this paper, we analyze such a phenomenon from the perspective of waiver phenomenon, which involves reducing the internal values of certain elements in the Softmax function, allowing them to absorb excess attention without affecting their contribution to information. In specific models, due to differences in positional encoding and attention patterns, we have found that the selection of waiver elements by the model can be categorized into two methods: positional-encoding-based and feature-distribution-within-elements-based.
Exploring the Low-Pass Filtering Behavior in Image Super-Resolution
May 17, 2024



Deep neural networks for image super-resolution (ISR) have shown significant advantages over traditional approaches like the interpolation. However, they are often criticized as 'black boxes' compared to traditional approaches with solid mathematical foundations. In this paper, we attempt to interpret the behavior of deep neural networks in ISR using theories from the field of signal processing. First, we report an intriguing phenomenon, referred to as `the sinc phenomenon.' It occurs when an impulse input is fed to a neural network. Then, building on this observation, we propose a method named Hybrid Response Analysis (HyRA) to analyze the behavior of neural networks in ISR tasks. Specifically, HyRA decomposes a neural network into a parallel connection of a linear system and a non-linear system and demonstrates that the linear system functions as a low-pass filter while the non-linear system injects high-frequency information. Finally, to quantify the injected high-frequency information, we introduce a metric for image-to-image tasks called Frequency Spectrum Distribution Similarity (FSDS). FSDS reflects the distribution similarity of different frequency components and can capture nuances that traditional metrics may overlook. Code, videos and raw experimental results for this paper can be found in: https://github.com/RisingEntropy/LPFInISR.
FusionMamba: Efficient Image Fusion with State Space Model
Apr 11, 2024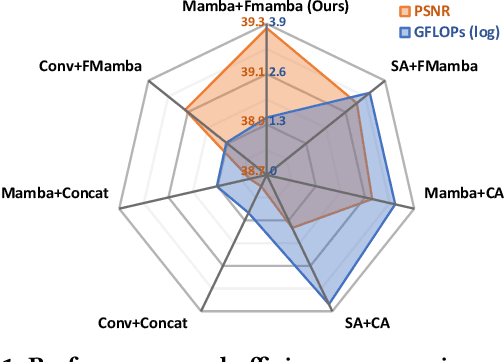
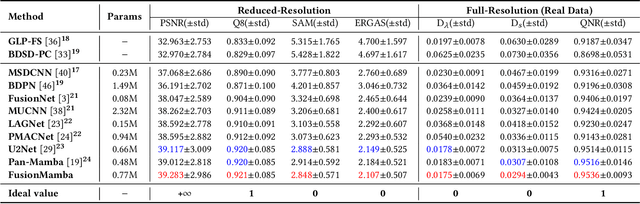
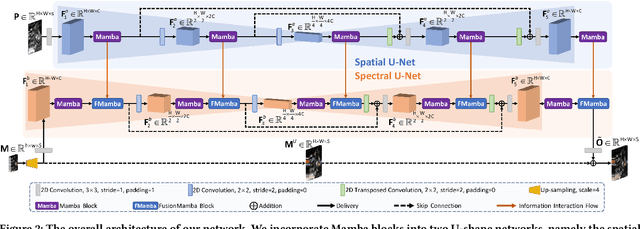
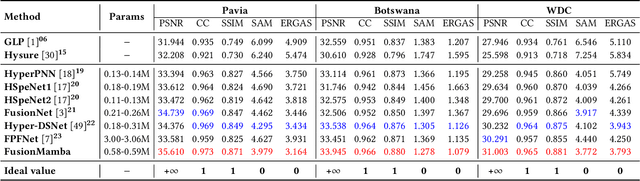
Image fusion aims to generate a high-resolution multi/hyper-spectral image by combining a high-resolution image with limited spectral information and a low-resolution image with abundant spectral data. Current deep learning (DL)-based methods for image fusion primarily rely on CNNs or Transformers to extract features and merge different types of data. While CNNs are efficient, their receptive fields are limited, restricting their capacity to capture global context. Conversely, Transformers excel at learning global information but are hindered by their quadratic complexity. Fortunately, recent advancements in the State Space Model (SSM), particularly Mamba, offer a promising solution to this issue by enabling global awareness with linear complexity. However, there have been few attempts to explore the potential of SSM in information fusion, which is a crucial ability in domains like image fusion. Therefore, we propose FusionMamba, an innovative method for efficient image fusion. Our contributions mainly focus on two aspects. Firstly, recognizing that images from different sources possess distinct properties, we incorporate Mamba blocks into two U-shaped networks, presenting a novel architecture that extracts spatial and spectral features in an efficient, independent, and hierarchical manner. Secondly, to effectively combine spatial and spectral information, we extend the Mamba block to accommodate dual inputs. This expansion leads to the creation of a new module called the FusionMamba block, which outperforms existing fusion techniques such as concatenation and cross-attention. To validate FusionMamba's effectiveness, we conduct a series of experiments on five datasets related to three image fusion tasks. The quantitative and qualitative evaluation results demonstrate that our method achieves state-of-the-art (SOTA) performance, underscoring the superiority of FusionMamba.
Content-Adaptive Non-Local Convolution for Remote Sensing Pansharpening
Apr 11, 2024



Currently, machine learning-based methods for remote sensing pansharpening have progressed rapidly. However, existing pansharpening methods often do not fully exploit differentiating regional information in non-local spaces, thereby limiting the effectiveness of the methods and resulting in redundant learning parameters. In this paper, we introduce a so-called content-adaptive non-local convolution (CANConv), a novel method tailored for remote sensing image pansharpening. Specifically, CANConv employs adaptive convolution, ensuring spatial adaptability, and incorporates non-local self-similarity through the similarity relationship partition (SRP) and the partition-wise adaptive convolution (PWAC) sub-modules. Furthermore, we also propose a corresponding network architecture, called CANNet, which mainly utilizes the multi-scale self-similarity. Extensive experiments demonstrate the superior performance of CANConv, compared with recent promising fusion methods. Besides, we substantiate the method's effectiveness through visualization, ablation experiments, and comparison with existing methods on multiple test sets. The source code is publicly available at https://github.com/duanyll/CANConv.
Tensor Decomposition Based Attention Module for Spiking Neural Networks
Oct 23, 2023The attention mechanism has been proven to be an effective way to improve spiking neural network (SNN). However, based on the fact that the current SNN input data flow is split into tensors to process on GPUs, none of the previous works consider the properties of tensors to implement an attention module. This inspires us to rethink current SNN from the perspective of tensor-relevant theories. Using tensor decomposition, we design the \textit{projected full attention} (PFA) module, which demonstrates excellent results with linearly growing parameters. Specifically, PFA is composed by the \textit{linear projection of spike tensor} (LPST) module and \textit{attention map composing} (AMC) module. In LPST, we start by compressing the original spike tensor into three projected tensors using a single property-preserving strategy with learnable parameters for each dimension. Then, in AMC, we exploit the inverse procedure of the tensor decomposition process to combine the three tensors into the attention map using a so-called connecting factor. To validate the effectiveness of the proposed PFA module, we integrate it into the widely used VGG and ResNet architectures for classification tasks. Our method achieves state-of-the-art performance on both static and dynamic benchmark datasets, surpassing the existing SNN models with Transformer-based and CNN-based backbones.
TCJA-SNN: Temporal-Channel Joint Attention for Spiking Neural Networks
Jun 21, 2022
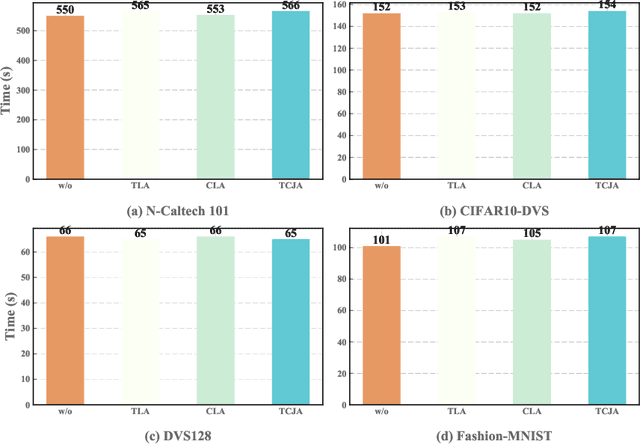
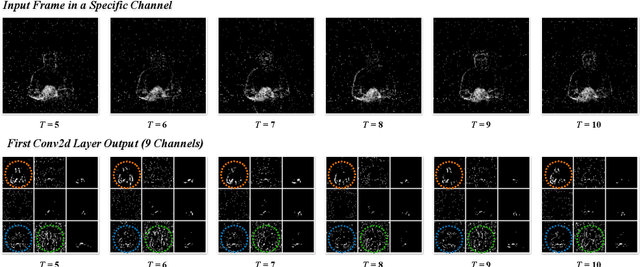

Spiking Neural Networks (SNNs) is a practical approach toward more data-efficient deep learning by simulating neurons leverage on temporal information. In this paper, we propose the Temporal-Channel Joint Attention (TCJA) architectural unit, an efficient SNN technique that depends on attention mechanisms, by effectively enforcing the relevance of spike sequence along both spatial and temporal dimensions. Our essential technical contribution lies on: 1) compressing the spike stream into an average matrix by employing the squeeze operation, then using two local attention mechanisms with an efficient 1-D convolution to establish temporal-wise and channel-wise relations for feature extraction in a flexible fashion. 2) utilizing the Cross Convolutional Fusion (CCF) layer for modeling inter-dependencies between temporal and channel scope, which breaks the independence of the two dimensions and realizes the interaction between features. By virtue of jointly exploring and recalibrating data stream, our method outperforms the state-of-the-art (SOTA) by up to 15.7% in terms of top-1 classification accuracy on all tested mainstream static and neuromorphic datasets, including Fashion-MNIST, CIFAR10-DVS, N-Caltech 101, and DVS128 Gesture.