 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextWand: A Unified Framework for Scene Text Editing
Jun 04, 2026We propose TextWand, a general-purpose framework that unifies scene text removal, generation, and replacement into a single model. By decomposing complex editing tasks into the atomic primitives of rendering and erasure, TextWand achieves precise control over both text appearance and background integrity. Specifically, we introduce a novel design, Overlay-Reference Positional Encoding (ORPE), to enforce pixel-level layout fidelity and exemplar-driven style control, alongside a new strategy, Region-Adaptive Suppression (RAS), to ensure clean text erasure. To address the absence of a comprehensive benchmark for general-purpose scene text editing among existing single-task datasets, we construct TextWand-Bench. Extensive experiments demonstrate that TextWand outperforms existing leading open-source and closed-source models by delivering superior text content accuracy, layout and style consistency, and overall image quality across scene text removal, generation and replacement tasks.
OctoT2I: A Self-Evolving Agentic Text-to-Image Router
Jun 01, 2026The explosive growth of Text-to-Image (T2I) models, from large-scale versions to lightweight, real-time ones, now faces diminishing marginal returns from single-model scaling. Agentic T2I methods emerged to alleviate this bottleneck by using multiple models. However, existing agentic T2I methods suffer from three key challenges: reliance on expensive handcrafted priors or human annotations, rigid single-path decision mechanisms, and a neglect of inference efficiency. To address these challenges, we introduce OctoT2I, a novel agentic framework that reformulates the T2I task as a joint optimization of generation quality and inference efficiency. OctoT2I implements a stateful, multi-round routing strategy that adaptively selects the most suitable tool based on its knowledge and memory. This strategy is enabled by a knowledge base built from scratch by our novel Self-Evolving Mechanism. This mechanism, which requires no human supervision, first autonomously defines foundational Conceptual Dimensions (eg, style, color, count) and then intelligently explores their combinations via an iterative" Propose--Solve--Evaluate--Learn"(PSEL) loop. The PSEL loop efficiently discovers each tool's capability frontier, driving continuous improvement without external guidance. Extensive experiments demonstrate that OctoT2I achieves competitive performance (0.96) on GenEval while delivering a 90.3% inference speedup and a 56.6% energy-efficiency gain over the leading baseline (Flow-GRPO), striking an exceptional balance between performance and efficiency. Code and models will be made available.
StableI2I: Spotting Unintended Changes in Image-to-Image Transition
May 06, 2026In most real-world image-to-image (I2I) scenarios, existing evaluations primarily focus on instruction following and the perceptual quality or aesthetics of the generated images. However, they largely fail to assess whether the output image preserves the semantic correspondence and spatial structure of the input image. To address this limitation, we propose StableI2I, a unified and dynamic evaluation framework that explicitly measures content fidelity and pre--post consistency across a wide range of I2I tasks without requiring reference images, including image editing and image restoration. In addition, we construct StableI2I-Bench, a benchmark designed to systematically evaluate the accuracy of MLLMs on such fidelity and consistency assessment tasks. Extensive experimental results demonstrate that StableI2I provides accurate, fine-grained, and interpretable evaluations of content fidelity and consistency, with strong correlations to human subjective judgments. Our framework serves as a practical and reliable evaluation tool for diagnosing content consistency and benchmarking model performance in real-world I2I systems.
Wavelet-Assisted Multi-Frequency Attention Network for Pansharpening
Feb 07, 2025



Pansharpening aims to combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (LRMS) image to produce a high-resolution multispectral (HRMS) image. Although pansharpening in the frequency domain offers clear advantages, most existing methods either continue to operate solely in the spatial domain or fail to fully exploit the benefits of the frequency domain. To address this issue, we innovatively propose Multi-Frequency Fusion Attention (MFFA), which leverages wavelet transforms to cleanly separate frequencies and enable lossless reconstruction across different frequency domains. Then, we generate Frequency-Query, Spatial-Key, and Fusion-Value based on the physical meanings represented by different features, which enables a more effective capture of specific information in the frequency domain. Additionally, we focus on the preservation of frequency features across different operations. On a broader level, our network employs a wavelet pyramid to progressively fuse information across multiple scales. Compared to previous frequency domain approaches, our network better prevents confusion and loss of different frequency features during the fusion process. Quantitative and qualitative experiments on multiple datasets demonstrate that our method outperforms existing approaches and shows significant generalization capabilities for real-world scenarios.
Exploring the Low-Pass Filtering Behavior in Image Super-Resolution
May 17, 2024



Deep neural networks for image super-resolution (ISR) have shown significant advantages over traditional approaches like the interpolation. However, they are often criticized as 'black boxes' compared to traditional approaches with solid mathematical foundations. In this paper, we attempt to interpret the behavior of deep neural networks in ISR using theories from the field of signal processing. First, we report an intriguing phenomenon, referred to as `the sinc phenomenon.' It occurs when an impulse input is fed to a neural network. Then, building on this observation, we propose a method named Hybrid Response Analysis (HyRA) to analyze the behavior of neural networks in ISR tasks. Specifically, HyRA decomposes a neural network into a parallel connection of a linear system and a non-linear system and demonstrates that the linear system functions as a low-pass filter while the non-linear system injects high-frequency information. Finally, to quantify the injected high-frequency information, we introduce a metric for image-to-image tasks called Frequency Spectrum Distribution Similarity (FSDS). FSDS reflects the distribution similarity of different frequency components and can capture nuances that traditional metrics may overlook. Code, videos and raw experimental results for this paper can be found in: https://github.com/RisingEntropy/LPFInISR.
Content-Adaptive Non-Local Convolution for Remote Sensing Pansharpening
Apr 11, 2024



Currently, machine learning-based methods for remote sensing pansharpening have progressed rapidly. However, existing pansharpening methods often do not fully exploit differentiating regional information in non-local spaces, thereby limiting the effectiveness of the methods and resulting in redundant learning parameters. In this paper, we introduce a so-called content-adaptive non-local convolution (CANConv), a novel method tailored for remote sensing image pansharpening. Specifically, CANConv employs adaptive convolution, ensuring spatial adaptability, and incorporates non-local self-similarity through the similarity relationship partition (SRP) and the partition-wise adaptive convolution (PWAC) sub-modules. Furthermore, we also propose a corresponding network architecture, called CANNet, which mainly utilizes the multi-scale self-similarity. Extensive experiments demonstrate the superior performance of CANConv, compared with recent promising fusion methods. Besides, we substantiate the method's effectiveness through visualization, ablation experiments, and comparison with existing methods on multiple test sets. The source code is publicly available at https://github.com/duanyll/CANConv.
Tensor Decomposition Based Attention Module for Spiking Neural Networks
Oct 23, 2023The attention mechanism has been proven to be an effective way to improve spiking neural network (SNN). However, based on the fact that the current SNN input data flow is split into tensors to process on GPUs, none of the previous works consider the properties of tensors to implement an attention module. This inspires us to rethink current SNN from the perspective of tensor-relevant theories. Using tensor decomposition, we design the \textit{projected full attention} (PFA) module, which demonstrates excellent results with linearly growing parameters. Specifically, PFA is composed by the \textit{linear projection of spike tensor} (LPST) module and \textit{attention map composing} (AMC) module. In LPST, we start by compressing the original spike tensor into three projected tensors using a single property-preserving strategy with learnable parameters for each dimension. Then, in AMC, we exploit the inverse procedure of the tensor decomposition process to combine the three tensors into the attention map using a so-called connecting factor. To validate the effectiveness of the proposed PFA module, we integrate it into the widely used VGG and ResNet architectures for classification tasks. Our method achieves state-of-the-art performance on both static and dynamic benchmark datasets, surpassing the existing SNN models with Transformer-based and CNN-based backbones.
TCJA-SNN: Temporal-Channel Joint Attention for Spiking Neural Networks
Jun 21, 2022
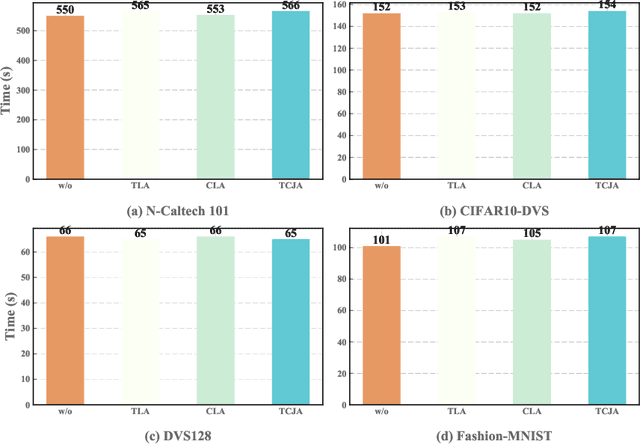
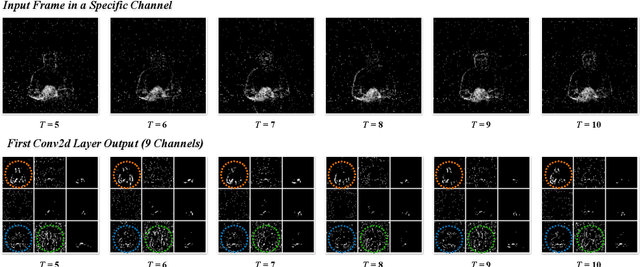

Spiking Neural Networks (SNNs) is a practical approach toward more data-efficient deep learning by simulating neurons leverage on temporal information. In this paper, we propose the Temporal-Channel Joint Attention (TCJA) architectural unit, an efficient SNN technique that depends on attention mechanisms, by effectively enforcing the relevance of spike sequence along both spatial and temporal dimensions. Our essential technical contribution lies on: 1) compressing the spike stream into an average matrix by employing the squeeze operation, then using two local attention mechanisms with an efficient 1-D convolution to establish temporal-wise and channel-wise relations for feature extraction in a flexible fashion. 2) utilizing the Cross Convolutional Fusion (CCF) layer for modeling inter-dependencies between temporal and channel scope, which breaks the independence of the two dimensions and realizes the interaction between features. By virtue of jointly exploring and recalibrating data stream, our method outperforms the state-of-the-art (SOTA) by up to 15.7% in terms of top-1 classification accuracy on all tested mainstream static and neuromorphic datasets, including Fashion-MNIST, CIFAR10-DVS, N-Caltech 101, and DVS128 Gesture.
Dimensionality Reduction of Hyperspectral Imagery Based on Spatial-spectral Manifold Learning
Dec 22, 2018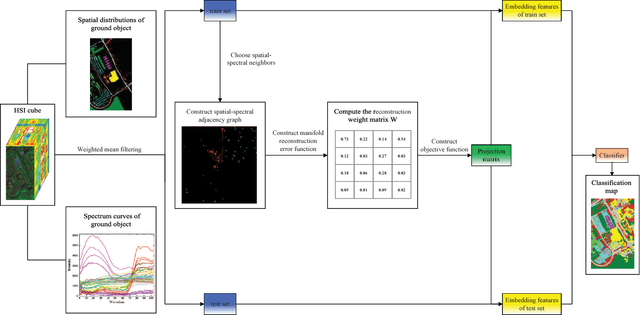
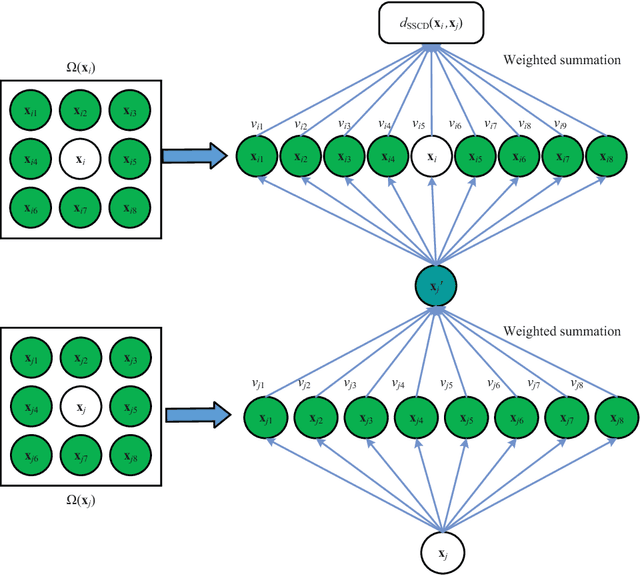


The graph embedding (GE) methods have been widely applied for dimensionality reduction of hyperspectral imagery (HSI). However, a major challenge of GE is how to choose proper neighbors for graph construction and explore the spatial information of HSI data. In this paper, we proposed an unsupervised dimensionality reduction algorithm termed spatial-spectral manifold reconstruction preserving embedding (SSMRPE) for HSI classification. At first, a weighted mean filter (WMF) is employed to preprocess the image, which aims to reduce the influence of background noise. According to the spatial consistency property of HSI, the SSMRPE method utilizes a new spatial-spectral combined distance (SSCD) to fuse the spatial structure and spectral information for selecting effective spatial-spectral neighbors of HSI pixels. Then, it explores the spatial relationship between each point and its neighbors to adjusts the reconstruction weights for improving the efficiency of manifold reconstruction. As a result, the proposed method can extract the discriminant features and subsequently improve the classification performance of HSI. The experimental results on PaviaU and Salinas hyperspectral datasets indicate that SSMRPE can achieve better classification accuracies in comparison with some state-of-the-art methods.