 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAKAN: Pixel Adaptive Kolmogorov-Arnold Network Modules for Pansharpening
Mar 16, 2026Pansharpening aims to fuse high-resolution spatial details from panchromatic images with the rich spectral information of multispectral images. Existing deep neural networks for this task typically rely on static activation functions, which limit their ability to dynamically model the complex, non-linear mappings required for optimal spatial-spectral fusion. While the recently introduced Kolmogorov-Arnold Network (KAN) utilizes learnable activation functions, traditional KANs lack dynamic adaptability during inference. To address this limitation, we propose a Pixel Adaptive Kolmogorov-Arnold Network framework. Starting from KAN, we design two adaptive variants: a 2D Adaptive KAN that generates spline summation weights across spatial dimensions and a 1D Adaptive KAN that generates them across spectral channels. These two components are then assembled into PAKAN 2to1 for feature fusion and PAKAN 1to1 for feature refinement. Extensive experiments demonstrate that our proposed modules significantly enhance network performance, proving the effectiveness and superiority of pixel-adaptive activation in pansharpening tasks.
Bi^2MAC: Bimodal Bi-Adaptive Mask-Aware Convolution for Remote Sensing Pansharpening
Dec 09, 2025Pansharpening aims to fuse a high-resolution panchromatic (PAN) image with a low-resolution multispectral (LRMS) image to generate a high-resolution multispectral image (HRMS). Conventional deep learning-based methods are inherently limited in their ability to adapt to regional heterogeneity within feature representations. Although various adaptive convolution methods have been proposed to address this limitation, they often suffer from excessive computational costs and a limited ability to capture heterogeneous regions in remote sensing images effectively. To overcome these challenges, we propose Bimodal Bi-Adaptive Mask-Aware Convolution (Bi^2MAC), which effectively exploits information from different types of regions while intelligently allocating computational resources. Specifically, we design a lightweight module to generate both soft and hard masks, which are used to modulate the input features preliminarily and to guide different types of regions into separate processing branches, respectively. Redundant features are directed to a compact branch for low-cost global processing. In contrast, heterogeneous features are routed to a focused branch that invests more computational resources for fine-grained modeling. Extensive experiments on multiple benchmark datasets demonstrate that Bi^2MAC achieves state-of-the-art (SOTA) performance while requiring substantially lower training time and parameter counts, and the minimal computational cost among adaptive convolution models.
Kernel Space Diffusion Model for Efficient Remote Sensing Pansharpening
May 25, 2025Pansharpening is a fundamental task in remote sensing that integrates high-resolution panchromatic imagery (PAN) with low-resolution multispectral imagery (LRMS) to produce an enhanced image with both high spatial and spectral resolution. Despite significant progress in deep learning-based approaches, existing methods often fail to capture the global priors inherent in remote sensing data distributions. Diffusion-based models have recently emerged as promising solutions due to their powerful distribution mapping capabilities; however, they suffer from significant inference latency, which limits their practical applicability. In this work, we propose the Kernel Space Diffusion Model (KSDiff), a novel approach that leverages diffusion processes in a latent space to generate convolutional kernels enriched with global contextual information, thereby improving pansharpening quality while enabling faster inference. Specifically, KSDiff constructs these kernels through the integration of a low-rank core tensor generator and a unified factor generator, orchestrated by a structure-aware multi-head attention mechanism. We further introduce a two-stage training strategy tailored for pansharpening, enabling KSDiff to serve as a framework for enhancing existing pansharpening architectures. Experiments on three widely used datasets, including WorldView-3, GaoFen-2, and QuickBird, demonstrate the superior performance of KSDiff both qualitatively and quantitatively. Code will be released upon possible acceptance.
Two-Stage Random Alternation Framework for Zero-Shot Pansharpening
May 10, 2025In recent years, pansharpening has seen rapid advancements with deep learning methods, which have demonstrated impressive fusion quality. However, the challenge of acquiring real high-resolution images limits the practical applicability of these methods. To address this, we propose a two-stage random alternating framework (TRA-PAN) that effectively integrates strong supervision constraints from reduced-resolution images with the physical characteristics of full-resolution images. The first stage introduces a pre-training procedure, which includes Degradation-Aware Modeling (DAM) to capture spatial-spectral degradation mappings, alongside a warm-up procedure designed to reduce training time and mitigate the negative effects of reduced-resolution data. In the second stage, Random Alternation Optimization (RAO) is employed, where random alternating training leverages the strengths of both reduced- and full-resolution images, further optimizing the fusion model. By primarily relying on full-resolution images, our method enables zero-shot training with just a single image pair, obviating the need for large datasets. Experimental results demonstrate that TRA-PAN outperforms state-of-the-art (SOTA) methods in both quantitative metrics and visual quality in real-world scenarios, highlighting its strong practical applicability.
A General Adaptive Dual-level Weighting Mechanism for Remote Sensing Pansharpening
Mar 17, 2025



Currently, deep learning-based methods for remote sensing pansharpening have advanced rapidly. However, many existing methods struggle to fully leverage feature heterogeneity and redundancy, thereby limiting their effectiveness. We use the covariance matrix to model the feature heterogeneity and redundancy and propose Correlation-Aware Covariance Weighting (CACW) to adjust them. CACW captures these correlations through the covariance matrix, which is then processed by a nonlinear function to generate weights for adjustment. Building upon CACW, we introduce a general adaptive dual-level weighting mechanism (ADWM) to address these challenges from two key perspectives, enhancing a wide range of existing deep-learning methods. First, Intra-Feature Weighting (IFW) evaluates correlations among channels within each feature to reduce redundancy and enhance unique information. Second, Cross-Feature Weighting (CFW) adjusts contributions across layers based on inter-layer correlations, refining the final output. Extensive experiments demonstrate the superior performance of ADWM compared to recent state-of-the-art (SOTA) methods. Furthermore, we validate the effectiveness of our approach through generality experiments, redundancy visualization, comparison experiments, key variables and complexity analysis, and ablation studies. Our code is available at https://github.com/Jie-1203/ADWM.
Wavelet-Assisted Multi-Frequency Attention Network for Pansharpening
Feb 07, 2025



Pansharpening aims to combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (LRMS) image to produce a high-resolution multispectral (HRMS) image. Although pansharpening in the frequency domain offers clear advantages, most existing methods either continue to operate solely in the spatial domain or fail to fully exploit the benefits of the frequency domain. To address this issue, we innovatively propose Multi-Frequency Fusion Attention (MFFA), which leverages wavelet transforms to cleanly separate frequencies and enable lossless reconstruction across different frequency domains. Then, we generate Frequency-Query, Spatial-Key, and Fusion-Value based on the physical meanings represented by different features, which enables a more effective capture of specific information in the frequency domain. Additionally, we focus on the preservation of frequency features across different operations. On a broader level, our network employs a wavelet pyramid to progressively fuse information across multiple scales. Compared to previous frequency domain approaches, our network better prevents confusion and loss of different frequency features during the fusion process. Quantitative and qualitative experiments on multiple datasets demonstrate that our method outperforms existing approaches and shows significant generalization capabilities for real-world scenarios.
ResPanDiff: Diffusion Model for Pansharpening by Inferring Residual Inference
Jan 10, 2025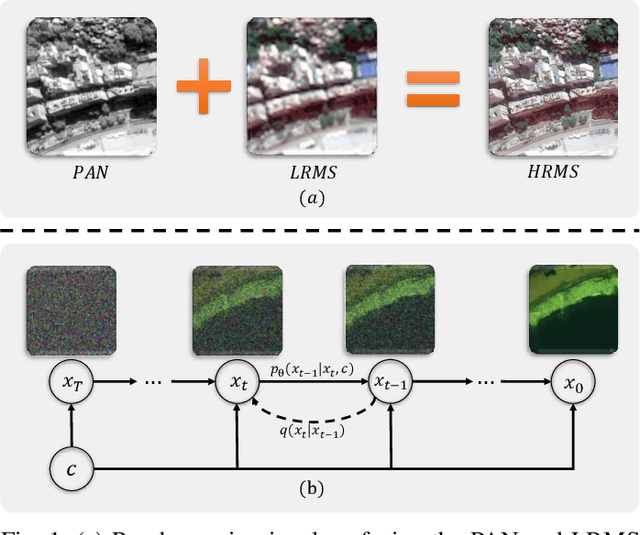


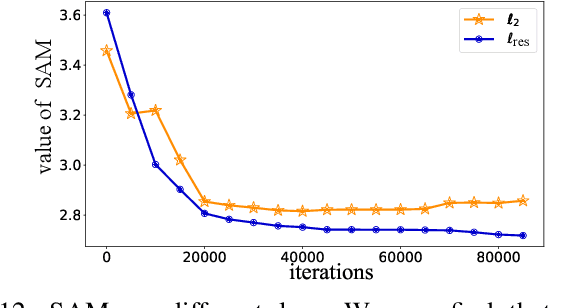
The implementation of diffusion-based pansharpening task is predominantly constrained by its slow inference speed, which results from numerous sampling steps. Despite the existing techniques aiming to accelerate sampling, they often compromise performance when fusing multi-source images. To ease this limitation, we introduce a novel and efficient diffusion model named Diffusion Model for Pansharpening by Inferring Residual Inference (ResPanDiff), which significantly reduces the number of diffusion steps without sacrificing the performance to tackle pansharpening task. In ResPanDiff, we innovatively propose a Markov chain that transits from noisy residuals to the residuals between the LRMS and HRMS images, thereby reducing the number of sampling steps and enhancing performance. Additionally, we design the latent space to help model extract more features at the encoding stage, Shallow Cond-Injection~(SC-I) to help model fetch cond-injected hidden features with higher dimensions, and loss functions to give a better guidance for the residual generation task. enabling the model to achieve superior performance in residual generation. Furthermore, experimental evaluations on pansharpening datasets demonstrate that the proposed method achieves superior outcomes compared to recent state-of-the-art~(SOTA) techniques, requiring only 15 sampling steps, which reduces over $90\%$ step compared with the benchmark diffusion models. Our experiments also include thorough discussions and ablation studies to underscore the effectiveness of our approach.
Tensor Decomposition Based Attention Module for Spiking Neural Networks
Oct 23, 2023The attention mechanism has been proven to be an effective way to improve spiking neural network (SNN). However, based on the fact that the current SNN input data flow is split into tensors to process on GPUs, none of the previous works consider the properties of tensors to implement an attention module. This inspires us to rethink current SNN from the perspective of tensor-relevant theories. Using tensor decomposition, we design the \textit{projected full attention} (PFA) module, which demonstrates excellent results with linearly growing parameters. Specifically, PFA is composed by the \textit{linear projection of spike tensor} (LPST) module and \textit{attention map composing} (AMC) module. In LPST, we start by compressing the original spike tensor into three projected tensors using a single property-preserving strategy with learnable parameters for each dimension. Then, in AMC, we exploit the inverse procedure of the tensor decomposition process to combine the three tensors into the attention map using a so-called connecting factor. To validate the effectiveness of the proposed PFA module, we integrate it into the widely used VGG and ResNet architectures for classification tasks. Our method achieves state-of-the-art performance on both static and dynamic benchmark datasets, surpassing the existing SNN models with Transformer-based and CNN-based backbones.