 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive 3D Convolution for Remote Sensing Image Fusion
May 10, 2026Remote sensing image fusion aims to create a high-resolution multi/hyper-spectral image from a high-resolution image with limited spectral information and a low-resolution image with abundant spectral data. Recently, deep learning (DL) techniques have shown significant effectiveness in this area. Most DL-based methods approach image fusion as a 2D problem by encoding spectral information into feature map channels. However, our research suggests that this strategy introduces notable spectral distortions. In contrast, some methods consider spectral data as an additional dimension, utilizing standard 3D convolutions to preserve spectral information. Nevertheless, in a standard 3D convolutional layer, the same set of kernels is applied across all input regions, which we have found to be sub-optimal for image fusion. Furthermore, standard 3D convolutions necessitate substantial computational resources. To address these challenges, we propose a novel convolutional paradigm called Adaptive 3D Convolution (Ada3D) for remote sensing image fusion. Ada3D applies a unique set of 3D kernels to each input voxel, enabling the capture of fine-grained details. These adaptive kernels are generated through a two-step process: (i) spatial and spectral kernels are derived from their respective image sources; (ii) these two types of kernels are then combined to form content-aware 3D kernels that effectively integrate spatial and spectral information. Additionally, adaptive biases are introduced to enhance the convolutional outcome at the voxel level. Furthermore, we incorporate the group convolution technique to reduce computational complexity. As a result, Ada3D offers full adaptivity in an efficient manner. Evaluation results across five datasets demonstrate that our method achieves SOTA performance, underscoring the superiority of Ada3D. The code is available at https://github.com/PSRben/Ada3D.
Direct Discrepancy Replay: Distribution-Discrepancy Condensation and Manifold-Consistent Replay for Continual Face Forgery Detection
Apr 14, 2026Continual face forgery detection (CFFD) requires detectors to learn emerging forgery paradigms without forgetting previously seen manipulations. Existing CFFD methods commonly rely on replaying a small amount of past data to mitigate forgetting. Such replay is typically implemented either by storing a few historical samples or by synthesizing pseudo-forgeries from detector-dependent perturbations. Under strict memory budgets, the former cannot adequately cover diverse forgery cues and may expose facial identities, while the latter remains strongly tied to past decision boundaries. We argue that the core role of replay in CFFD is to reinstate the distributions of previous forgery tasks during subsequent training. To this end, we directly condense the discrepancy between real and fake distributions and leverage real faces from the current stage to perform distribution-level replay. Specifically, we introduce Distribution-Discrepancy Condensation (DDC), which models the real-to-fake discrepancy via a surrogate factorization in characteristic-function space and condenses it into a tiny bank of distribution discrepancy maps. We further propose Manifold-Consistent Replay (MCR), which synthesizes replay samples through variance-preserving composition of these maps with current-stage real faces, yielding samples that reflect previous-task forgery cues while remaining compatible with current real-face statistics. Operating under an extremely small memory budget and without directly storing raw historical face images, our framework consistently outperforms prior CFFD baselines and significantly mitigates catastrophic forgetting. Replay-level privacy analysis further suggests reduced identity leakage risk relative to selection-based replay.
From Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
Mar 01, 2026Face recognition remains vulnerable to presentation attacks, calling for robust Face Anti-Spoofing (FAS) solutions. Recent MLLM-based FAS methods reformulate the binary classification task as the generation of brief textual descriptions to improve cross-domain generalization. However, their generalizability is still limited, as such descriptions mainly capture intuitive semantic cues (e.g., mask contours) while struggling to perceive fine-grained visual patterns. To address this limitation, we incorporate external visual tools into MLLMs to encourage deeper investigation of subtle spoof clues. Specifically, we propose the Tool-Augmented Reasoning FAS (TAR-FAS) framework, which reformulates the FAS task as a Chain-of-Thought with Visual Tools (CoT-VT) paradigm, allowing MLLMs to begin with intuitive observations and adaptively invoke external visual tools for fine-grained investigation. To this end, we design a tool-augmented data annotation pipeline and construct the ToolFAS-16K dataset, which contains multi-turn tool-use reasoning trajectories. Furthermore, we introduce a tool-aware FAS training pipeline, where Diverse-Tool Group Relative Policy Optimization (DT-GRPO) enables the model to autonomously learn efficient tool use. Extensive experiments under a challenging one-to-eleven cross-domain protocol demonstrate that TAR-FAS achieves SOTA performance while providing fine-grained visual investigation for trustworthy spoof detection.
UPA: Unsupervised Prompt Agent via Tree-Based Search and Selection
Jan 30, 2026Prompt agents have recently emerged as a promising paradigm for automated prompt optimization, framing refinement as a sequential decision-making problem over a structured prompt space. While this formulation enables the use of advanced planning algorithms, these methods typically assume access to supervised reward signals, which are often unavailable in practical scenarios. In this work, we propose UPA, an Unsupervised Prompt Agent that realizes structured search and selection without relying on supervised feedback. Specifically, during search, UPA iteratively constructs an evolving tree structure to navigate the prompt space, guided by fine-grained and order-invariant pairwise comparisons from Large Language Models (LLMs). Crucially, as these local comparisons do not inherently yield a consistent global scale, we decouple systematic prompt exploration from final selection, introducing a two-stage framework grounded in the Bradley-Terry-Luce (BTL) model. This framework first performs path-wise Bayesian aggregation of local comparisons to filter candidates under uncertainty, followed by global tournament-style comparisons to infer latent prompt quality and identify the optimal prompt. Experiments across multiple tasks demonstrate that UPA consistently outperforms existing prompt optimization methods, showing that agent-style optimization remains highly effective even in fully unsupervised settings.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
LAKAN: Landmark-assisted Adaptive Kolmogorov-Arnold Network for Face Forgery Detection
Oct 01, 2025The rapid development of deepfake generation techniques necessitates robust face forgery detection algorithms. While methods based on Convolutional Neural Networks (CNNs) and Transformers are effective, there is still room for improvement in modeling the highly complex and non-linear nature of forgery artifacts. To address this issue, we propose a novel detection method based on the Kolmogorov-Arnold Network (KAN). By replacing fixed activation functions with learnable splines, our KAN-based approach is better suited to this challenge. Furthermore, to guide the network's focus towards critical facial areas, we introduce a Landmark-assisted Adaptive Kolmogorov-Arnold Network (LAKAN) module. This module uses facial landmarks as a structural prior to dynamically generate the internal parameters of the KAN, creating an instance-specific signal that steers a general-purpose image encoder towards the most informative facial regions with artifacts. This core innovation creates a powerful combination between geometric priors and the network's learning process. Extensive experiments on multiple public datasets show that our proposed method achieves superior performance.
MLLM-Enhanced Face Forgery Detection: A Vision-Language Fusion Solution
May 04, 2025Reliable face forgery detection algorithms are crucial for countering the growing threat of deepfake-driven disinformation. Previous research has demonstrated the potential of Multimodal Large Language Models (MLLMs) in identifying manipulated faces. However, existing methods typically depend on either the Large Language Model (LLM) alone or an external detector to generate classification results, which often leads to sub-optimal integration of visual and textual modalities. In this paper, we propose VLF-FFD, a novel Vision-Language Fusion solution for MLLM-enhanced Face Forgery Detection. Our key contributions are twofold. First, we present EFF++, a frame-level, explainability-driven extension of the widely used FaceForensics++ (FF++) dataset. In EFF++, each manipulated video frame is paired with a textual annotation that describes both the forgery artifacts and the specific manipulation technique applied, enabling more effective and informative MLLM training. Second, we design a Vision-Language Fusion Network (VLF-Net) that promotes bidirectional interaction between visual and textual features, supported by a three-stage training pipeline to fully leverage its potential. VLF-FFD achieves state-of-the-art (SOTA) performance in both cross-dataset and intra-dataset evaluations, underscoring its exceptional effectiveness in face forgery detection.
A General Adaptive Dual-level Weighting Mechanism for Remote Sensing Pansharpening
Mar 17, 2025



Currently, deep learning-based methods for remote sensing pansharpening have advanced rapidly. However, many existing methods struggle to fully leverage feature heterogeneity and redundancy, thereby limiting their effectiveness. We use the covariance matrix to model the feature heterogeneity and redundancy and propose Correlation-Aware Covariance Weighting (CACW) to adjust them. CACW captures these correlations through the covariance matrix, which is then processed by a nonlinear function to generate weights for adjustment. Building upon CACW, we introduce a general adaptive dual-level weighting mechanism (ADWM) to address these challenges from two key perspectives, enhancing a wide range of existing deep-learning methods. First, Intra-Feature Weighting (IFW) evaluates correlations among channels within each feature to reduce redundancy and enhance unique information. Second, Cross-Feature Weighting (CFW) adjusts contributions across layers based on inter-layer correlations, refining the final output. Extensive experiments demonstrate the superior performance of ADWM compared to recent state-of-the-art (SOTA) methods. Furthermore, we validate the effectiveness of our approach through generality experiments, redundancy visualization, comparison experiments, key variables and complexity analysis, and ablation studies. Our code is available at https://github.com/Jie-1203/ADWM.
WMamba: Wavelet-based Mamba for Face Forgery Detection
Jan 16, 2025



With the rapid advancement of deepfake generation technologies, the demand for robust and accurate face forgery detection algorithms has become increasingly critical. Recent studies have demonstrated that wavelet analysis can uncover subtle forgery artifacts that remain imperceptible in the spatial domain. Wavelets effectively capture important facial contours, which are often slender, fine-grained, and global in nature. However, existing wavelet-based approaches fail to fully leverage these unique characteristics, resulting in sub-optimal feature extraction and limited generalizability. To address this challenge, we introduce WMamba, a novel wavelet-based feature extractor built upon the Mamba architecture. WMamba maximizes the utility of wavelet information through two key innovations. First, we propose Dynamic Contour Convolution (DCConv), which employs specially crafted deformable kernels to adaptively model slender facial contours. Second, by leveraging the Mamba architecture, our method captures long-range spatial relationships with linear computational complexity. This efficiency allows for the extraction of fine-grained, global forgery artifacts from small image patches. Extensive experimental results show that WMamba achieves state-of-the-art (SOTA) performance, highlighting its effectiveness and superiority in face forgery detection.
FusionMamba: Efficient Image Fusion with State Space Model
Apr 11, 2024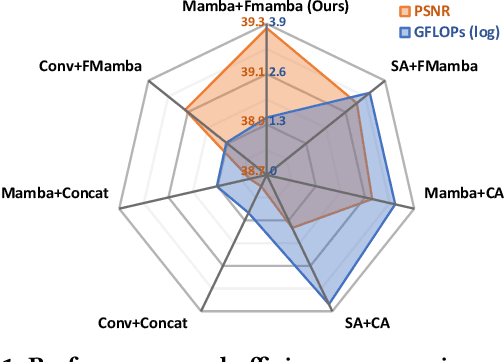
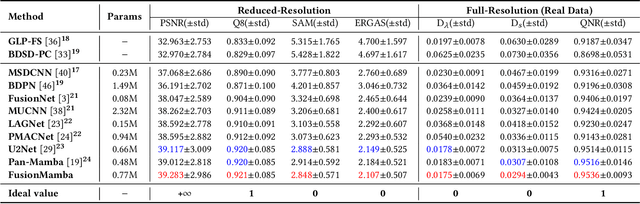
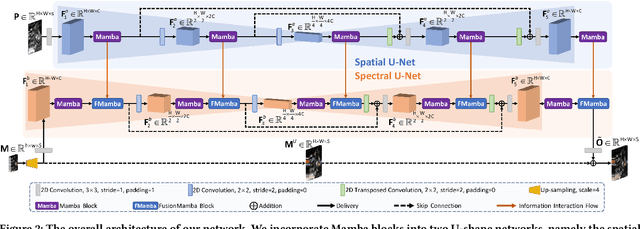
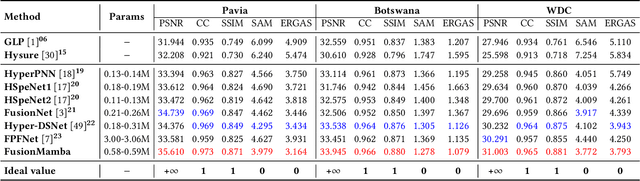
Image fusion aims to generate a high-resolution multi/hyper-spectral image by combining a high-resolution image with limited spectral information and a low-resolution image with abundant spectral data. Current deep learning (DL)-based methods for image fusion primarily rely on CNNs or Transformers to extract features and merge different types of data. While CNNs are efficient, their receptive fields are limited, restricting their capacity to capture global context. Conversely, Transformers excel at learning global information but are hindered by their quadratic complexity. Fortunately, recent advancements in the State Space Model (SSM), particularly Mamba, offer a promising solution to this issue by enabling global awareness with linear complexity. However, there have been few attempts to explore the potential of SSM in information fusion, which is a crucial ability in domains like image fusion. Therefore, we propose FusionMamba, an innovative method for efficient image fusion. Our contributions mainly focus on two aspects. Firstly, recognizing that images from different sources possess distinct properties, we incorporate Mamba blocks into two U-shaped networks, presenting a novel architecture that extracts spatial and spectral features in an efficient, independent, and hierarchical manner. Secondly, to effectively combine spatial and spectral information, we extend the Mamba block to accommodate dual inputs. This expansion leads to the creation of a new module called the FusionMamba block, which outperforms existing fusion techniques such as concatenation and cross-attention. To validate FusionMamba's effectiveness, we conduct a series of experiments on five datasets related to three image fusion tasks. The quantitative and qualitative evaluation results demonstrate that our method achieves state-of-the-art (SOTA) performance, underscoring the superiority of FusionMamba.