 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Discrepancy Replay: Distribution-Discrepancy Condensation and Manifold-Consistent Replay for Continual Face Forgery Detection
Apr 14, 2026Continual face forgery detection (CFFD) requires detectors to learn emerging forgery paradigms without forgetting previously seen manipulations. Existing CFFD methods commonly rely on replaying a small amount of past data to mitigate forgetting. Such replay is typically implemented either by storing a few historical samples or by synthesizing pseudo-forgeries from detector-dependent perturbations. Under strict memory budgets, the former cannot adequately cover diverse forgery cues and may expose facial identities, while the latter remains strongly tied to past decision boundaries. We argue that the core role of replay in CFFD is to reinstate the distributions of previous forgery tasks during subsequent training. To this end, we directly condense the discrepancy between real and fake distributions and leverage real faces from the current stage to perform distribution-level replay. Specifically, we introduce Distribution-Discrepancy Condensation (DDC), which models the real-to-fake discrepancy via a surrogate factorization in characteristic-function space and condenses it into a tiny bank of distribution discrepancy maps. We further propose Manifold-Consistent Replay (MCR), which synthesizes replay samples through variance-preserving composition of these maps with current-stage real faces, yielding samples that reflect previous-task forgery cues while remaining compatible with current real-face statistics. Operating under an extremely small memory budget and without directly storing raw historical face images, our framework consistently outperforms prior CFFD baselines and significantly mitigates catastrophic forgetting. Replay-level privacy analysis further suggests reduced identity leakage risk relative to selection-based replay.
From Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
Mar 01, 2026Face recognition remains vulnerable to presentation attacks, calling for robust Face Anti-Spoofing (FAS) solutions. Recent MLLM-based FAS methods reformulate the binary classification task as the generation of brief textual descriptions to improve cross-domain generalization. However, their generalizability is still limited, as such descriptions mainly capture intuitive semantic cues (e.g., mask contours) while struggling to perceive fine-grained visual patterns. To address this limitation, we incorporate external visual tools into MLLMs to encourage deeper investigation of subtle spoof clues. Specifically, we propose the Tool-Augmented Reasoning FAS (TAR-FAS) framework, which reformulates the FAS task as a Chain-of-Thought with Visual Tools (CoT-VT) paradigm, allowing MLLMs to begin with intuitive observations and adaptively invoke external visual tools for fine-grained investigation. To this end, we design a tool-augmented data annotation pipeline and construct the ToolFAS-16K dataset, which contains multi-turn tool-use reasoning trajectories. Furthermore, we introduce a tool-aware FAS training pipeline, where Diverse-Tool Group Relative Policy Optimization (DT-GRPO) enables the model to autonomously learn efficient tool use. Extensive experiments under a challenging one-to-eleven cross-domain protocol demonstrate that TAR-FAS achieves SOTA performance while providing fine-grained visual investigation for trustworthy spoof detection.
UPA: Unsupervised Prompt Agent via Tree-Based Search and Selection
Jan 30, 2026Prompt agents have recently emerged as a promising paradigm for automated prompt optimization, framing refinement as a sequential decision-making problem over a structured prompt space. While this formulation enables the use of advanced planning algorithms, these methods typically assume access to supervised reward signals, which are often unavailable in practical scenarios. In this work, we propose UPA, an Unsupervised Prompt Agent that realizes structured search and selection without relying on supervised feedback. Specifically, during search, UPA iteratively constructs an evolving tree structure to navigate the prompt space, guided by fine-grained and order-invariant pairwise comparisons from Large Language Models (LLMs). Crucially, as these local comparisons do not inherently yield a consistent global scale, we decouple systematic prompt exploration from final selection, introducing a two-stage framework grounded in the Bradley-Terry-Luce (BTL) model. This framework first performs path-wise Bayesian aggregation of local comparisons to filter candidates under uncertainty, followed by global tournament-style comparisons to infer latent prompt quality and identify the optimal prompt. Experiments across multiple tasks demonstrate that UPA consistently outperforms existing prompt optimization methods, showing that agent-style optimization remains highly effective even in fully unsupervised settings.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
MLLM-Enhanced Face Forgery Detection: A Vision-Language Fusion Solution
May 04, 2025Reliable face forgery detection algorithms are crucial for countering the growing threat of deepfake-driven disinformation. Previous research has demonstrated the potential of Multimodal Large Language Models (MLLMs) in identifying manipulated faces. However, existing methods typically depend on either the Large Language Model (LLM) alone or an external detector to generate classification results, which often leads to sub-optimal integration of visual and textual modalities. In this paper, we propose VLF-FFD, a novel Vision-Language Fusion solution for MLLM-enhanced Face Forgery Detection. Our key contributions are twofold. First, we present EFF++, a frame-level, explainability-driven extension of the widely used FaceForensics++ (FF++) dataset. In EFF++, each manipulated video frame is paired with a textual annotation that describes both the forgery artifacts and the specific manipulation technique applied, enabling more effective and informative MLLM training. Second, we design a Vision-Language Fusion Network (VLF-Net) that promotes bidirectional interaction between visual and textual features, supported by a three-stage training pipeline to fully leverage its potential. VLF-FFD achieves state-of-the-art (SOTA) performance in both cross-dataset and intra-dataset evaluations, underscoring its exceptional effectiveness in face forgery detection.
WMamba: Wavelet-based Mamba for Face Forgery Detection
Jan 16, 2025



With the rapid advancement of deepfake generation technologies, the demand for robust and accurate face forgery detection algorithms has become increasingly critical. Recent studies have demonstrated that wavelet analysis can uncover subtle forgery artifacts that remain imperceptible in the spatial domain. Wavelets effectively capture important facial contours, which are often slender, fine-grained, and global in nature. However, existing wavelet-based approaches fail to fully leverage these unique characteristics, resulting in sub-optimal feature extraction and limited generalizability. To address this challenge, we introduce WMamba, a novel wavelet-based feature extractor built upon the Mamba architecture. WMamba maximizes the utility of wavelet information through two key innovations. First, we propose Dynamic Contour Convolution (DCConv), which employs specially crafted deformable kernels to adaptively model slender facial contours. Second, by leveraging the Mamba architecture, our method captures long-range spatial relationships with linear computational complexity. This efficiency allows for the extraction of fine-grained, global forgery artifacts from small image patches. Extensive experimental results show that WMamba achieves state-of-the-art (SOTA) performance, highlighting its effectiveness and superiority in face forgery detection.
Concept Discovery in Deep Neural Networks for Explainable Face Anti-Spoofing
Dec 23, 2024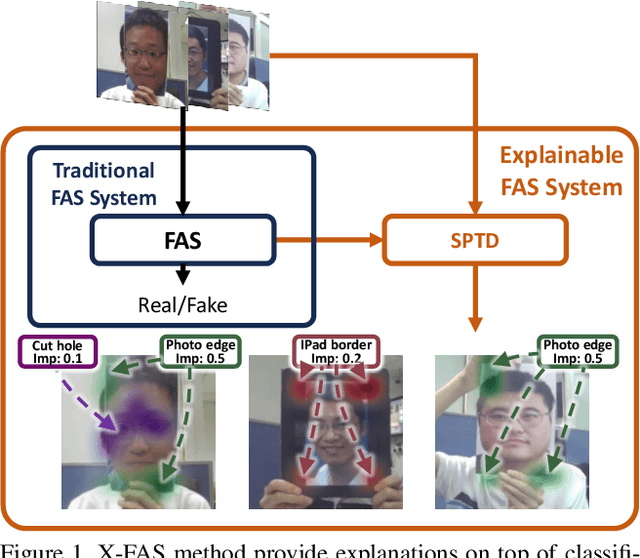
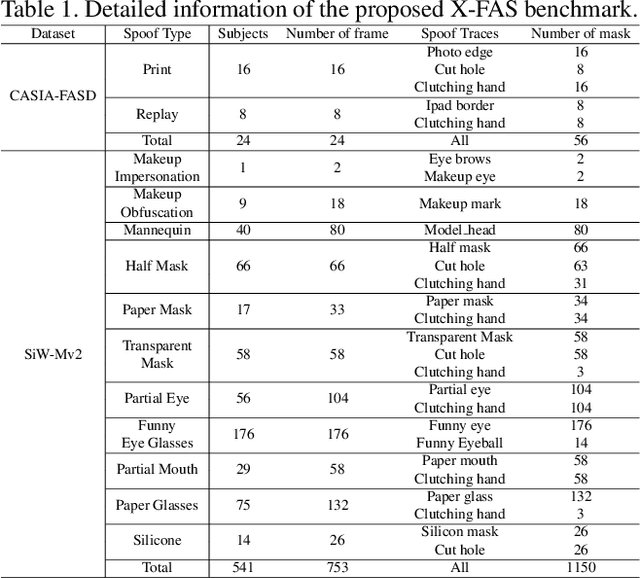
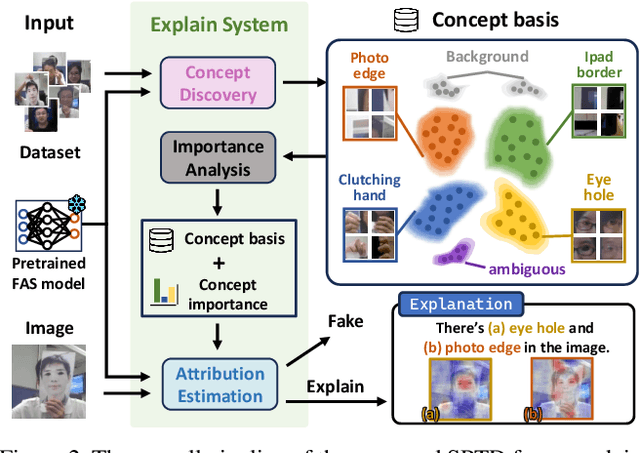
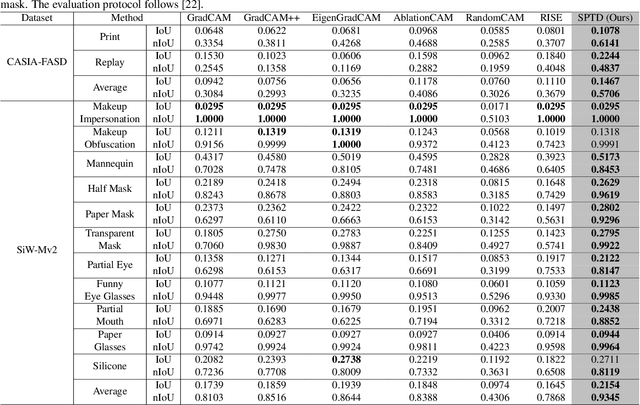
With the rapid growth usage of face recognition in people's daily life, face anti-spoofing becomes increasingly important to avoid malicious attacks. Recent face anti-spoofing models can reach a high classification accuracy on multiple datasets but these models can only tell people ``this face is fake'' while lacking the explanation to answer ``why it is fake''. Such a system undermines trustworthiness and causes user confusion, as it denies their requests without providing any explanations. In this paper, we incorporate XAI into face anti-spoofing and propose a new problem termed X-FAS (eXplainable Face Anti-Spoofing) empowering face anti-spoofing models to provide an explanation. We propose SPED (SPoofing Evidence Discovery), an X-FAS method which can discover spoof concepts and provide reliable explanations on the basis of discovered concepts. To evaluate the quality of X-FAS methods, we propose an X-FAS benchmark with annotated spoofing evidence by experts. We analyze SPED explanations on face anti-spoofing dataset and compare SPED quantitatively and qualitatively with previous XAI methods on proposed X-FAS benchmark. Experimental results demonstrate SPED's ability to generate reliable explanations.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
NTU4DRadLM: 4D Radar-centric Multi-Modal Dataset for Localization and Mapping
Sep 02, 2023



Simultaneous Localization and Mapping (SLAM) is moving towards a robust perception age. However, LiDAR- and visual- SLAM may easily fail in adverse conditions (rain, snow, smoke and fog, etc.). In comparison, SLAM based on 4D Radar, thermal camera and IMU can work robustly. But only a few literature can be found. A major reason is the lack of related datasets, which seriously hinders the research. Even though some datasets are proposed based on 4D radar in past four years, they are mainly designed for object detection, rather than SLAM. Furthermore, they normally do not include thermal camera. Therefore, in this paper, NTU4DRadLM is presented to meet this requirement. The main characteristics are: 1) It is the only dataset that simultaneously includes all 6 sensors: 4D radar, thermal camera, IMU, 3D LiDAR, visual camera and RTK GPS. 2) Specifically designed for SLAM tasks, which provides fine-tuned ground truth odometry and intentionally formulated loop closures. 3) Considered both low-speed robot platform and fast-speed unmanned vehicle platform. 4) Covered structured, unstructured and semi-structured environments. 5) Considered both middle- and large- scale outdoor environments, i.e., the 6 trajectories range from 246m to 6.95km. 6) Comprehensively evaluated three types of SLAM algorithms. Totally, the dataset is around 17.6km, 85mins, 50GB and it will be accessible from this link: https://github.com/junzhang2016/NTU4DRadLM
Contrastive Positive Mining for Unsupervised 3D Action Representation Learning
Aug 06, 2022



Recent contrastive based 3D action representation learning has made great progress. However, the strict positive/negative constraint is yet to be relaxed and the use of non-self positive is yet to be explored. In this paper, a Contrastive Positive Mining (CPM) framework is proposed for unsupervised skeleton 3D action representation learning. The CPM identifies non-self positives in a contextual queue to boost learning. Specifically, the siamese encoders are adopted and trained to match the similarity distributions of the augmented instances in reference to all instances in the contextual queue. By identifying the non-self positive instances in the queue, a positive-enhanced learning strategy is proposed to leverage the knowledge of mined positives to boost the robustness of the learned latent space against intra-class and inter-class diversity. Experimental results have shown that the proposed CPM is effective and outperforms the existing state-of-the-art unsupervised methods on the challenging NTU and PKU-MMD datasets.