 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMamba: Wavelet-based Mamba for Face Forgery Detection
Jan 16, 2025



With the rapid advancement of deepfake generation technologies, the demand for robust and accurate face forgery detection algorithms has become increasingly critical. Recent studies have demonstrated that wavelet analysis can uncover subtle forgery artifacts that remain imperceptible in the spatial domain. Wavelets effectively capture important facial contours, which are often slender, fine-grained, and global in nature. However, existing wavelet-based approaches fail to fully leverage these unique characteristics, resulting in sub-optimal feature extraction and limited generalizability. To address this challenge, we introduce WMamba, a novel wavelet-based feature extractor built upon the Mamba architecture. WMamba maximizes the utility of wavelet information through two key innovations. First, we propose Dynamic Contour Convolution (DCConv), which employs specially crafted deformable kernels to adaptively model slender facial contours. Second, by leveraging the Mamba architecture, our method captures long-range spatial relationships with linear computational complexity. This efficiency allows for the extraction of fine-grained, global forgery artifacts from small image patches. Extensive experimental results show that WMamba achieves state-of-the-art (SOTA) performance, highlighting its effectiveness and superiority in face forgery detection.
Concept Discovery in Deep Neural Networks for Explainable Face Anti-Spoofing
Dec 23, 2024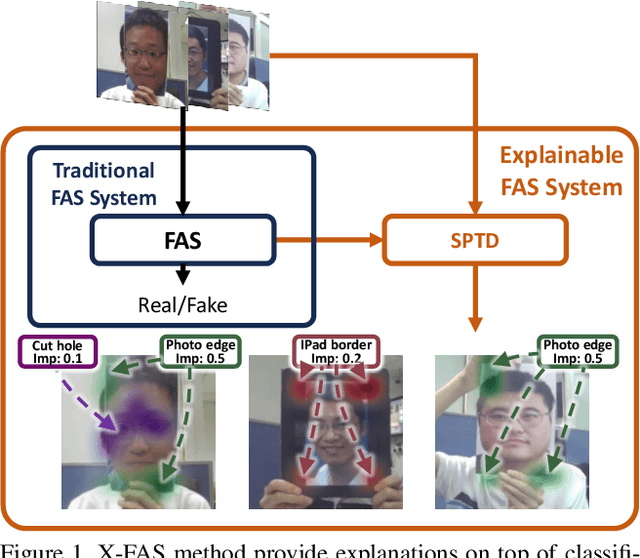
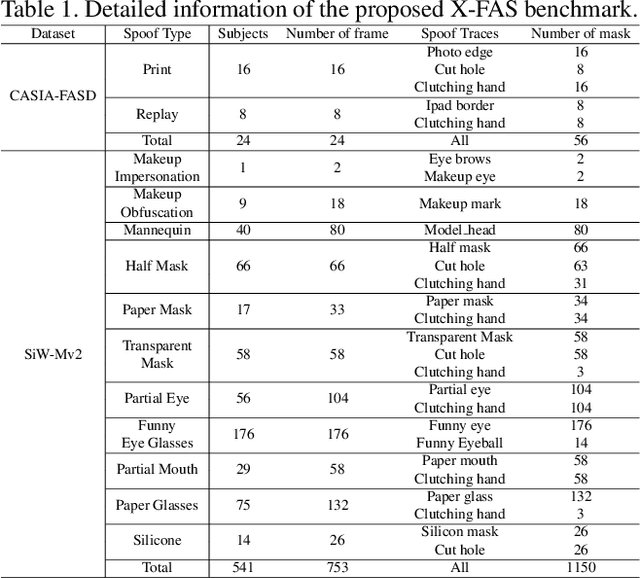
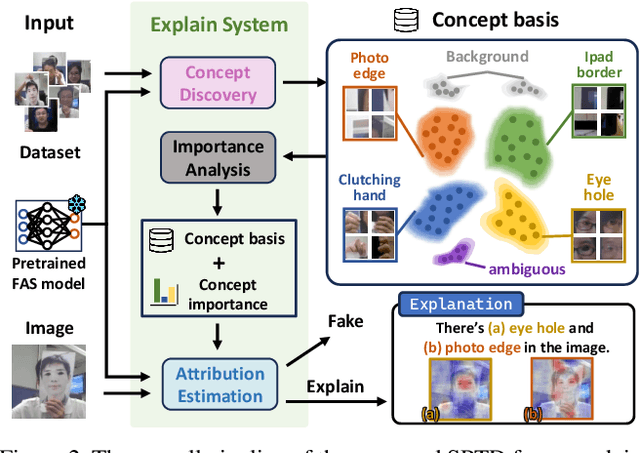
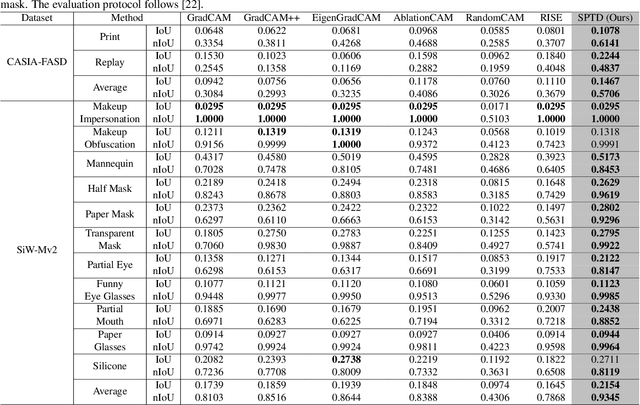
With the rapid growth usage of face recognition in people's daily life, face anti-spoofing becomes increasingly important to avoid malicious attacks. Recent face anti-spoofing models can reach a high classification accuracy on multiple datasets but these models can only tell people ``this face is fake'' while lacking the explanation to answer ``why it is fake''. Such a system undermines trustworthiness and causes user confusion, as it denies their requests without providing any explanations. In this paper, we incorporate XAI into face anti-spoofing and propose a new problem termed X-FAS (eXplainable Face Anti-Spoofing) empowering face anti-spoofing models to provide an explanation. We propose SPED (SPoofing Evidence Discovery), an X-FAS method which can discover spoof concepts and provide reliable explanations on the basis of discovered concepts. To evaluate the quality of X-FAS methods, we propose an X-FAS benchmark with annotated spoofing evidence by experts. We analyze SPED explanations on face anti-spoofing dataset and compare SPED quantitatively and qualitatively with previous XAI methods on proposed X-FAS benchmark. Experimental results demonstrate SPED's ability to generate reliable explanations.
Turbulence-Resilient Coherent Free-Space Optical Communications using Automatic Power-Efficient Pilot-Assisted Optoelectronic Beam Mixing of Many Modes
Jan 25, 2021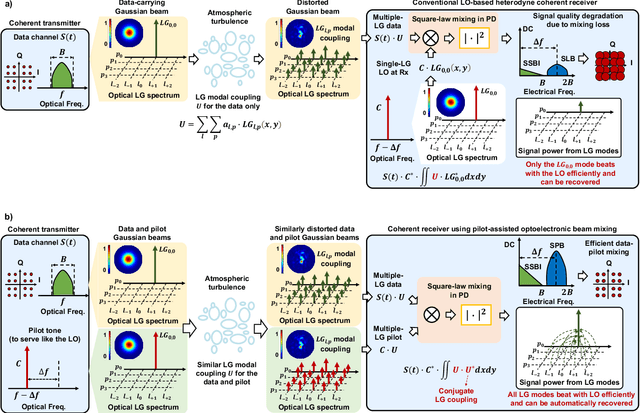
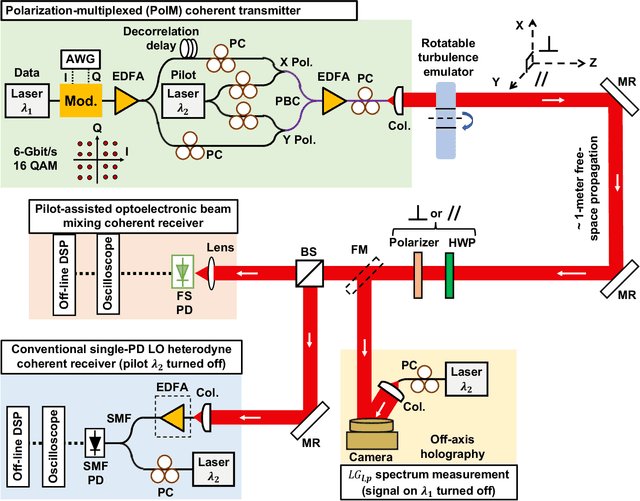
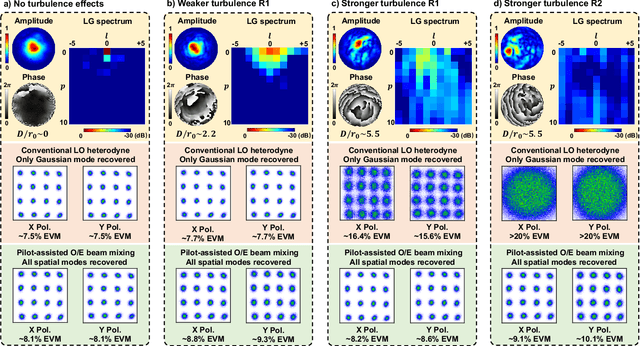
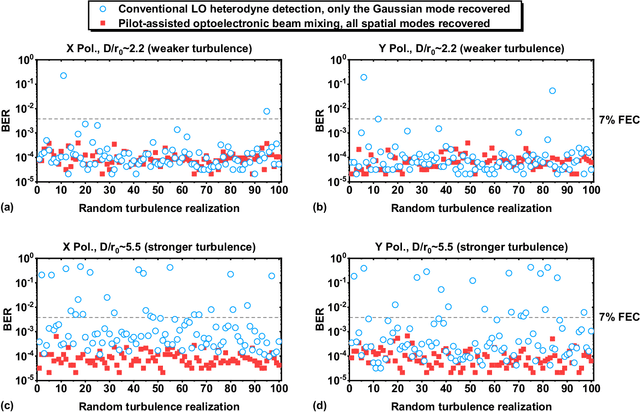
Atmospheric turbulence generally limits free-space optical (FSO) communications, and this problem is severely exacerbated when implementing highly sensitive and spectrally efficient coherent detection. Specifically, turbulence induces power coupling from the transmitted Gaussian mode to higher-order Laguerre-Gaussian (LG) modes, resulting in a significant decrease of the power that mixes with a single-mode local oscillator (LO). Instead, we transmit a frequency-offset Gaussian pilot tone along with the data signal, such that both experience similar turbulence and modal power coupling. Subsequently, the photodetector (PD) optoelectronically mixes all corresponding pairs of the beams' modes. During mixing, a conjugate of the turbulence experienced by the pilot tone is automatically generated and compensates the turbulence experienced by the data, and nearly all orders of the same corresponding modes efficiently mix. We demonstrate a 12-Gbit/s 16-quadrature-amplitude-modulation (16-QAM) polarization-multiplexed (PolM) FSO link that exhibits resilience to emulated turbulence. Experimental results for turbulence D/r_0~5.5 show up to ~20 dB reduction in the mixing power loss over a conventional coherent receiver. Therefore, our approach automatically recovers nearly all the captured data power to enable high-performance coherent FSO systems.