 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness in RGB-Skeleton Action Recognition: Leveraging Attention Modality Reweighter
Jul 29, 2024



Deep neural networks (DNNs) have been applied in many computer vision tasks and achieved state-of-the-art (SOTA) performance. However, misclassification will occur when DNNs predict adversarial examples which are created by adding human-imperceptible adversarial noise to natural examples. This limits the application of DNN in security-critical fields. In order to enhance the robustness of models, previous research has primarily focused on the unimodal domain, such as image recognition and video understanding. Although multi-modal learning has achieved advanced performance in various tasks, such as action recognition, research on the robustness of RGB-skeleton action recognition models is scarce. In this paper, we systematically investigate how to improve the robustness of RGB-skeleton action recognition models. We initially conducted empirical analysis on the robustness of different modalities and observed that the skeleton modality is more robust than the RGB modality. Motivated by this observation, we propose the \formatword{A}ttention-based \formatword{M}odality \formatword{R}eweighter (\formatword{AMR}), which utilizes an attention layer to re-weight the two modalities, enabling the model to learn more robust features. Our AMR is plug-and-play, allowing easy integration with multimodal models. To demonstrate the effectiveness of AMR, we conducted extensive experiments on various datasets. For example, compared to the SOTA methods, AMR exhibits a 43.77\% improvement against PGD20 attacks on the NTU-RGB+D 60 dataset. Furthermore, it effectively balances the differences in robustness between different modalities.
Sub-action Prototype Learning for Point-level Weakly-supervised Temporal Action Localization
Sep 16, 2023Point-level weakly-supervised temporal action localization (PWTAL) aims to localize actions with only a single timestamp annotation for each action instance. Existing methods tend to mine dense pseudo labels to alleviate the label sparsity, but overlook the potential sub-action temporal structures, resulting in inferior performance. To tackle this problem, we propose a novel sub-action prototype learning framework (SPL-Loc) which comprises Sub-action Prototype Clustering (SPC) and Ordered Prototype Alignment (OPA). SPC adaptively extracts representative sub-action prototypes which are capable to perceive the temporal scale and spatial content variation of action instances. OPA selects relevant prototypes to provide completeness clue for pseudo label generation by applying a temporal alignment loss. As a result, pseudo labels are derived from alignment results to improve action boundary prediction. Extensive experiments on three popular benchmarks demonstrate that the proposed SPL-Loc significantly outperforms existing SOTA PWTAL methods.
Image Reconstruction for Accelerated MR Scan with Faster Fourier Convolutional Neural Networks
Jun 05, 2023



Partial scan is a common approach to accelerate Magnetic Resonance Imaging (MRI) data acquisition in both 2D and 3D settings. However, accurately reconstructing images from partial scan data (i.e., incomplete k-space matrices) remains challenging due to lack of an effectively global receptive field in both spatial and k-space domains. To address this problem, we propose the following: (1) a novel convolutional operator called Faster Fourier Convolution (FasterFC) to replace the two consecutive convolution operations typically used in convolutional neural networks (e.g., U-Net, ResNet). Based on the spectral convolution theorem in Fourier theory, FasterFC employs alternating kernels of size 1 in 3D case) in different domains to extend the dual-domain receptive field to the global and achieves faster calculation speed than traditional Fast Fourier Convolution (FFC). (2) A 2D accelerated MRI method, FasterFC-End-to-End-VarNet, which uses FasterFC to improve the sensitivity maps and reconstruction quality. (3) A multi-stage 3D accelerated MRI method called FasterFC-based Single-to-group Network (FAS-Net) that utilizes a single-to-group algorithm to guide k-space domain reconstruction, followed by FasterFC-based cascaded convolutional neural networks to expand the effective receptive field in the dual-domain. Experimental results on the fastMRI and Stanford MRI Data datasets demonstrate that FasterFC improves the quality of both 2D and 3D reconstruction. Moreover, FAS-Net, as a 3D high-resolution multi-coil (eight) accelerated MRI method, achieves superior reconstruction performance in both qualitative and quantitative results compared with state-of-the-art 2D and 3D methods.
FT-HID: A Large Scale RGB-D Dataset for First and Third Person Human Interaction Analysis
Sep 21, 2022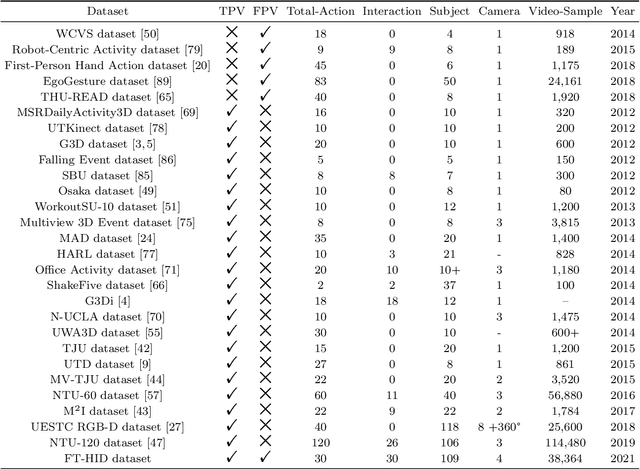
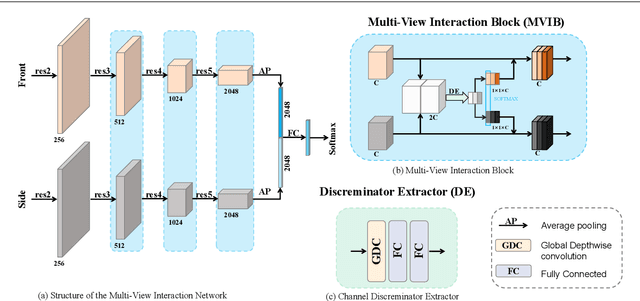
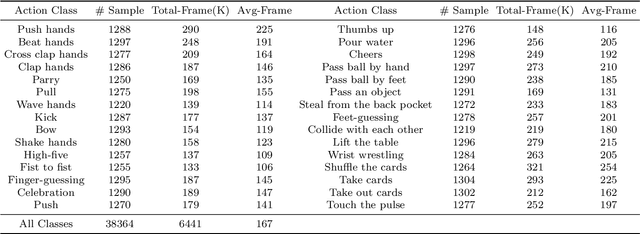
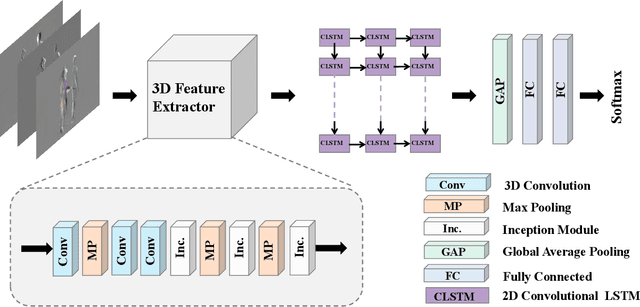
Analysis of human interaction is one important research topic of human motion analysis. It has been studied either using first person vision (FPV) or third person vision (TPV). However, the joint learning of both types of vision has so far attracted little attention. One of the reasons is the lack of suitable datasets that cover both FPV and TPV. In addition, existing benchmark datasets of either FPV or TPV have several limitations, including the limited number of samples, participant subjects, interaction categories, and modalities. In this work, we contribute a large-scale human interaction dataset, namely, FT-HID dataset. FT-HID contains pair-aligned samples of first person and third person visions. The dataset was collected from 109 distinct subjects and has more than 90K samples for three modalities. The dataset has been validated by using several existing action recognition methods. In addition, we introduce a novel multi-view interaction mechanism for skeleton sequences, and a joint learning multi-stream framework for first person and third person visions. Both methods yield promising results on the FT-HID dataset. It is expected that the introduction of this vision-aligned large-scale dataset will promote the development of both FPV and TPV, and their joint learning techniques for human action analysis. The dataset and code are available at \href{https://github.com/ENDLICHERE/FT-HID}{here}.
Contrastive Positive Mining for Unsupervised 3D Action Representation Learning
Aug 06, 2022



Recent contrastive based 3D action representation learning has made great progress. However, the strict positive/negative constraint is yet to be relaxed and the use of non-self positive is yet to be explored. In this paper, a Contrastive Positive Mining (CPM) framework is proposed for unsupervised skeleton 3D action representation learning. The CPM identifies non-self positives in a contextual queue to boost learning. Specifically, the siamese encoders are adopted and trained to match the similarity distributions of the augmented instances in reference to all instances in the contextual queue. By identifying the non-self positive instances in the queue, a positive-enhanced learning strategy is proposed to leverage the knowledge of mined positives to boost the robustness of the learned latent space against intra-class and inter-class diversity. Experimental results have shown that the proposed CPM is effective and outperforms the existing state-of-the-art unsupervised methods on the challenging NTU and PKU-MMD datasets.
Learning Using Privileged Information for Zero-Shot Action Recognition
Jun 22, 2022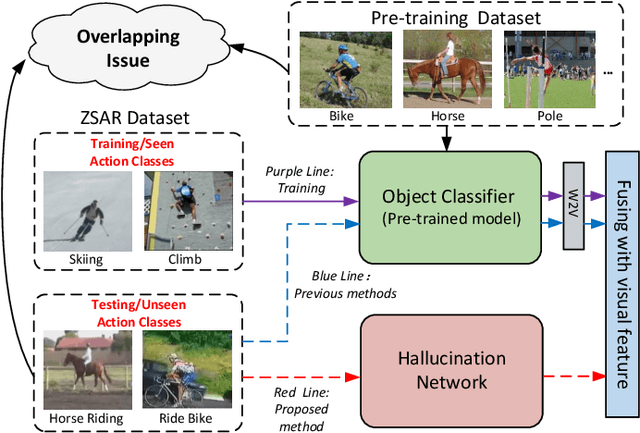
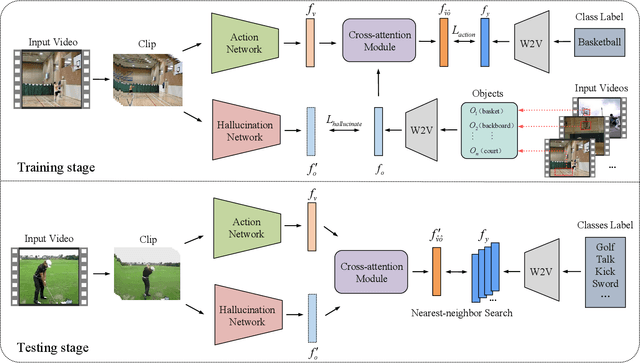
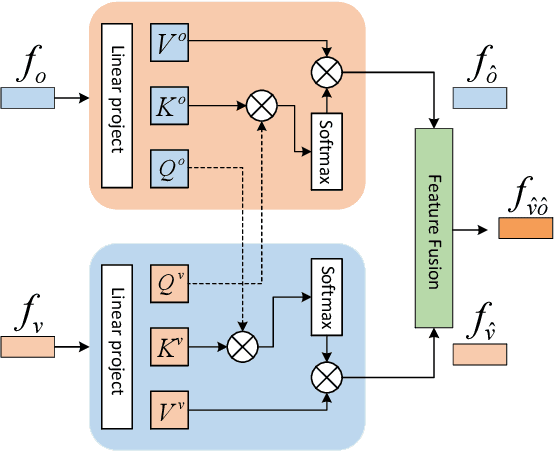
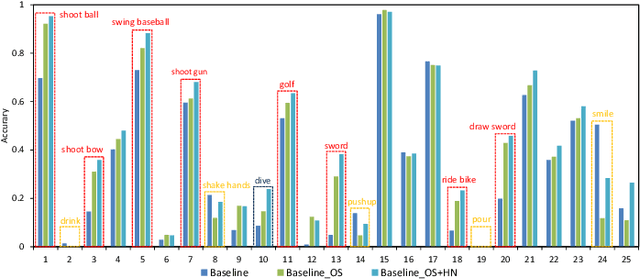
Zero-Shot Action Recognition (ZSAR) aims to recognize video actions that have never been seen during training. Most existing methods assume a shared semantic space between seen and unseen actions and intend to directly learn a mapping from a visual space to the semantic space. This approach has been challenged by the semantic gap between the visual space and semantic space. This paper presents a novel method that uses object semantics as privileged information to narrow the semantic gap and, hence, effectively, assist the learning. In particular, a simple hallucination network is proposed to implicitly extract object semantics during testing without explicitly extracting objects and a cross-attention module is developed to augment visual feature with the object semantics. Experiments on the Olympic Sports, HMDB51 and UCF101 datasets have shown that the proposed method outperforms the state-of-the-art methods by a large margin.
A Central Difference Graph Convolutional Operator for Skeleton-Based Action Recognition
Nov 13, 2021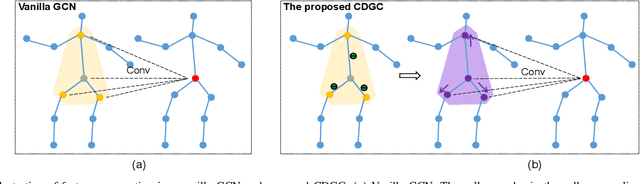
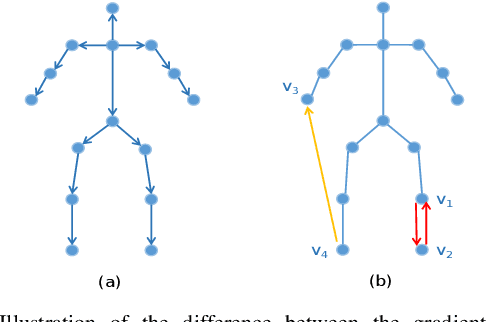
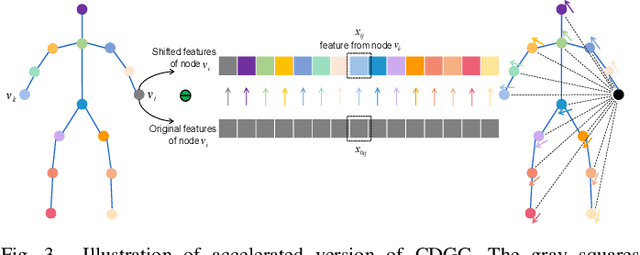
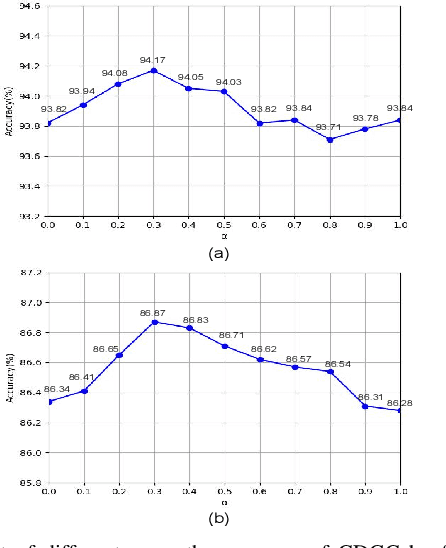
This paper proposes a new graph convolutional operator called central difference graph convolution (CDGC) for skeleton based action recognition. It is not only able to aggregate node information like a vanilla graph convolutional operation but also gradient information. Without introducing any additional parameters, CDGC can replace vanilla graph convolution in any existing Graph Convolutional Networks (GCNs). In addition, an accelerated version of the CDGC is developed which greatly improves the speed of training. Experiments on two popular large-scale datasets NTU RGB+D 60 & 120 have demonstrated the efficacy of the proposed CDGC. Code is available at https://github.com/iesymiao/CD-GCN.
Trear: Transformer-based RGB-D Egocentric Action Recognition
Jan 05, 2021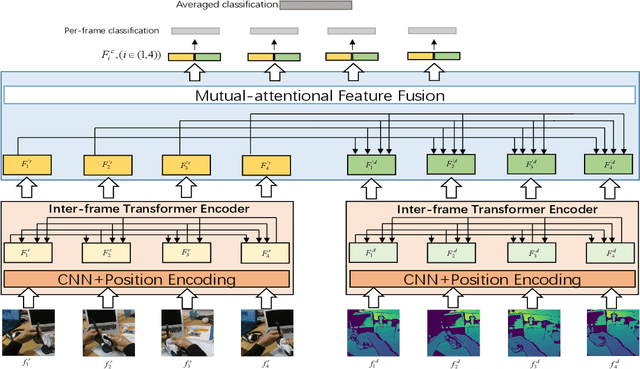
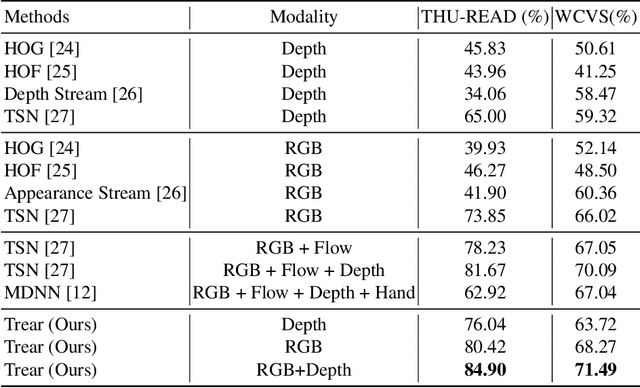
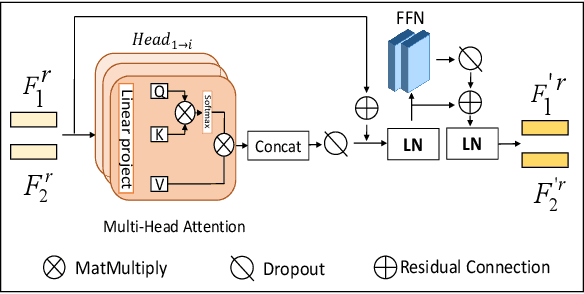
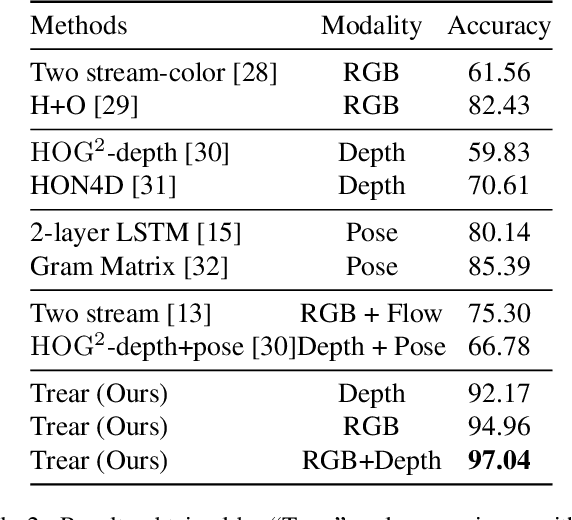
In this paper, we propose a \textbf{Tr}ansformer-based RGB-D \textbf{e}gocentric \textbf{a}ction \textbf{r}ecognition framework, called Trear. It consists of two modules, inter-frame attention encoder and mutual-attentional fusion block. Instead of using optical flow or recurrent units, we adopt self-attention mechanism to model the temporal structure of the data from different modalities. Input frames are cropped randomly to mitigate the effect of the data redundancy. Features from each modality are interacted through the proposed fusion block and combined through a simple yet effective fusion operation to produce a joint RGB-D representation. Empirical experiments on two large egocentric RGB-D datasets, THU-READ and FPHA, and one small dataset, WCVS, have shown that the proposed method outperforms the state-of-the-art results by a large margin.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020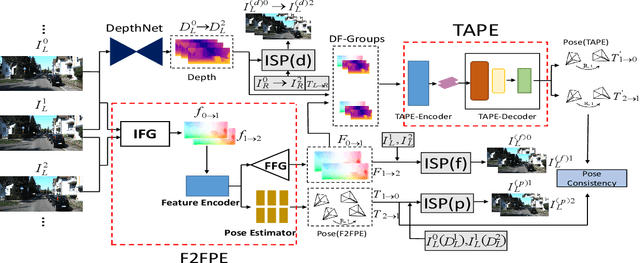
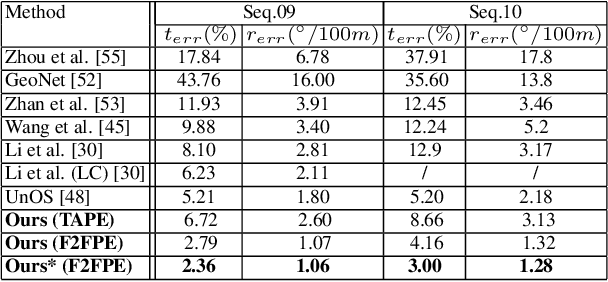
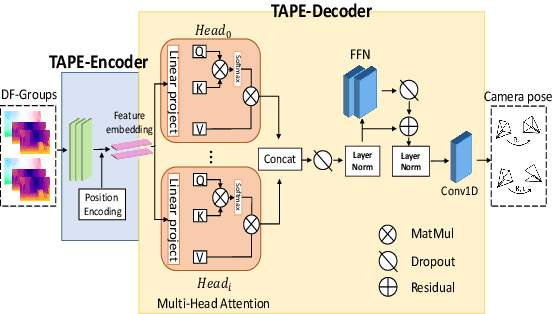
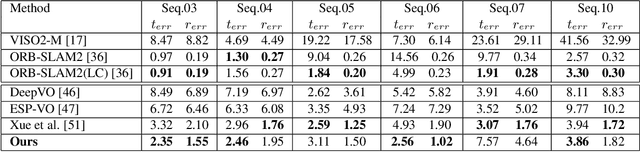
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.
SAR-NAS: Skeleton-based Action Recognition via Neural Architecture Searching
Oct 29, 2020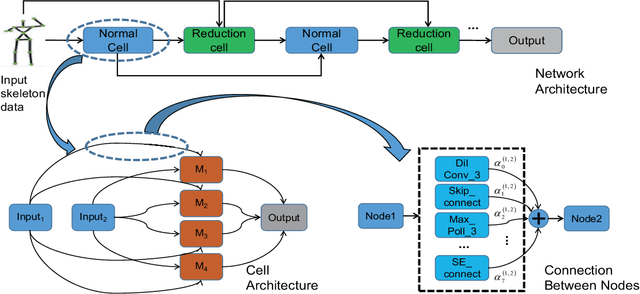
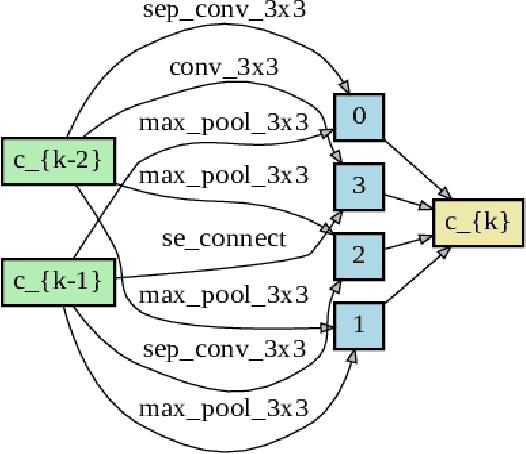
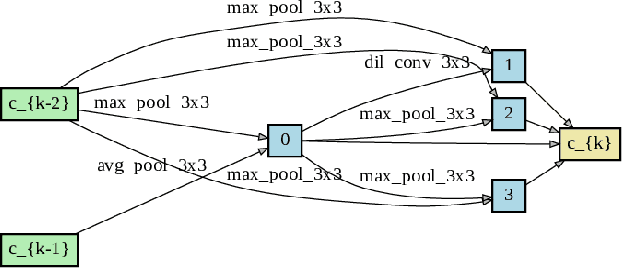

This paper presents a study of automatic design of neural network architectures for skeleton-based action recognition. Specifically, we encode a skeleton-based action instance into a tensor and carefully define a set of operations to build two types of network cells: normal cells and reduction cells. The recently developed DARTS (Differentiable Architecture Search) is adopted to search for an effective network architecture that is built upon the two types of cells. All operations are 2D based in order to reduce the overall computation and search space. Experiments on the challenging NTU RGB+D and Kinectics datasets have verified that most of the networks developed to date for skeleton-based action recognition are likely not compact and efficient. The proposed method provides an approach to search for such a compact network that is able to achieve comparative or even better performance than the state-of-the-art methods.