 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrear: Transformer-based RGB-D Egocentric Action Recognition
Paper and Code
Jan 05, 2021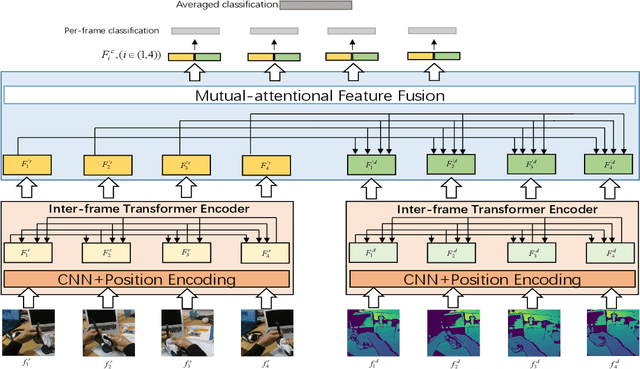
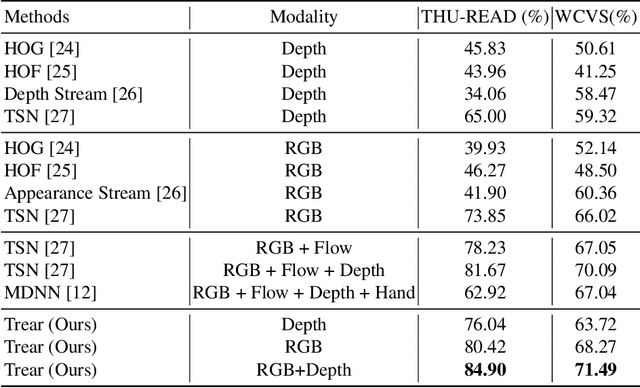
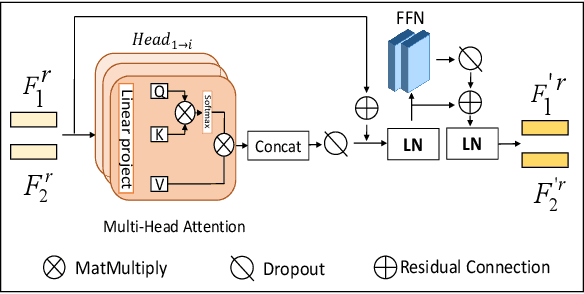
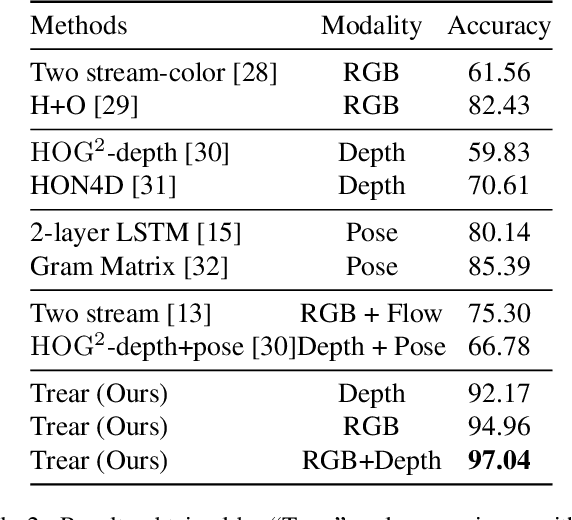
In this paper, we propose a \textbf{Tr}ansformer-based RGB-D \textbf{e}gocentric \textbf{a}ction \textbf{r}ecognition framework, called Trear. It consists of two modules, inter-frame attention encoder and mutual-attentional fusion block. Instead of using optical flow or recurrent units, we adopt self-attention mechanism to model the temporal structure of the data from different modalities. Input frames are cropped randomly to mitigate the effect of the data redundancy. Features from each modality are interacted through the proposed fusion block and combined through a simple yet effective fusion operation to produce a joint RGB-D representation. Empirical experiments on two large egocentric RGB-D datasets, THU-READ and FPHA, and one small dataset, WCVS, have shown that the proposed method outperforms the state-of-the-art results by a large margin.