 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Discrepancy and Cross-modal Semantic Consistency Learning for Object Detection in Hyperspectral Image
Dec 20, 2025Hyperspectral images with high spectral resolution provide new insights into recognizing subtle differences in similar substances. However, object detection in hyperspectral images faces significant challenges in intra- and inter-class similarity due to the spatial differences in hyperspectral inter-bands and unavoidable interferences, e.g., sensor noises and illumination. To alleviate the hyperspectral inter-bands inconsistencies and redundancy, we propose a novel network termed \textbf{S}pectral \textbf{D}iscrepancy and \textbf{C}ross-\textbf{M}odal semantic consistency learning (SDCM), which facilitates the extraction of consistent information across a wide range of hyperspectral bands while utilizing the spectral dimension to pinpoint regions of interest. Specifically, we leverage a semantic consistency learning (SCL) module that utilizes inter-band contextual cues to diminish the heterogeneity of information among bands, yielding highly coherent spectral dimension representations. On the other hand, we incorporate a spectral gated generator (SGG) into the framework that filters out the redundant data inherent in hyperspectral information based on the importance of the bands. Then, we design the spectral discrepancy aware (SDA) module to enrich the semantic representation of high-level information by extracting pixel-level spectral features. Extensive experiments on two hyperspectral datasets demonstrate that our proposed method achieves state-of-the-art performance when compared with other ones.
Human Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023



Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.
Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition
Oct 06, 2022
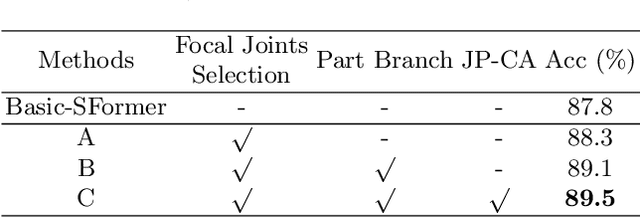
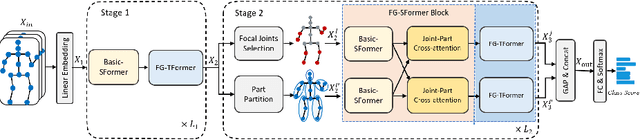

Despite great progress achieved by transformer in various vision tasks, it is still underexplored for skeleton-based action recognition with only a few attempts. Besides, these methods directly calculate the pair-wise global self-attention equally for all the joints in both the spatial and temporal dimensions, undervaluing the effect of discriminative local joints and the short-range temporal dynamics. In this work, we propose a novel Focal and Global Spatial-Temporal Transformer network (FG-STFormer), that is equipped with two key components: (1) FG-SFormer: focal joints and global parts coupling spatial transformer. It forces the network to focus on modelling correlations for both the learned discriminative spatial joints and human body parts respectively. The selective focal joints eliminate the negative effect of non-informative ones during accumulating the correlations. Meanwhile, the interactions between the focal joints and body parts are incorporated to enhance the spatial dependencies via mutual cross-attention. (2) FG-TFormer: focal and global temporal transformer. Dilated temporal convolution is integrated into the global self-attention mechanism to explicitly capture the local temporal motion patterns of joints or body parts, which is found to be vital important to make temporal transformer work. Extensive experimental results on three benchmarks, namely NTU-60, NTU-120 and NW-UCLA, show our FG-STFormer surpasses all existing transformer-based methods, and compares favourably with state-of-the art GCN-based methods.
FT-HID: A Large Scale RGB-D Dataset for First and Third Person Human Interaction Analysis
Sep 21, 2022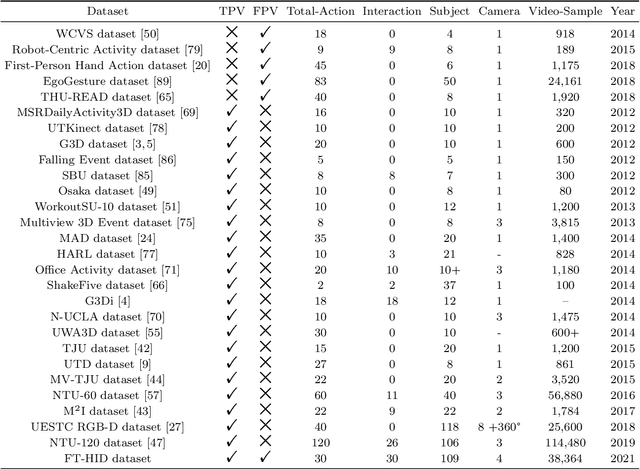
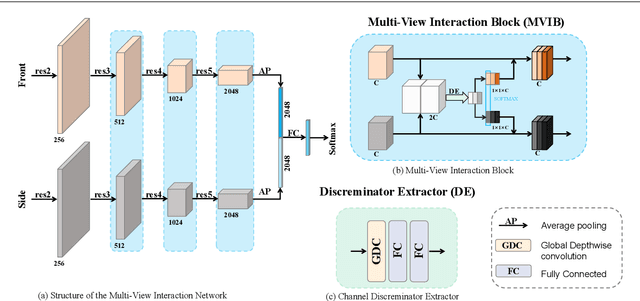
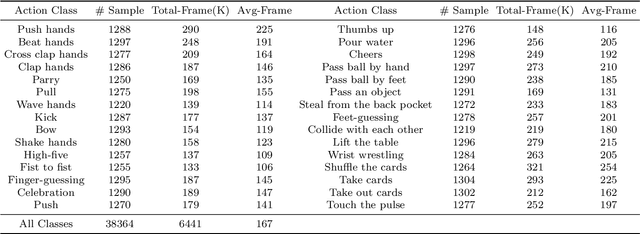
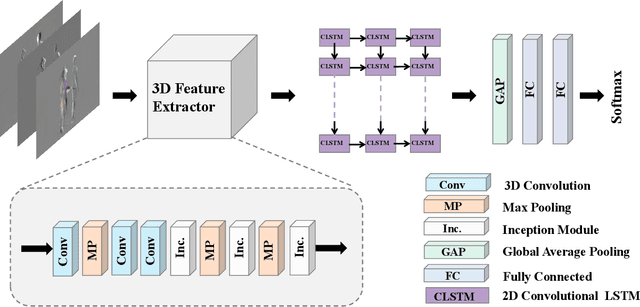
Analysis of human interaction is one important research topic of human motion analysis. It has been studied either using first person vision (FPV) or third person vision (TPV). However, the joint learning of both types of vision has so far attracted little attention. One of the reasons is the lack of suitable datasets that cover both FPV and TPV. In addition, existing benchmark datasets of either FPV or TPV have several limitations, including the limited number of samples, participant subjects, interaction categories, and modalities. In this work, we contribute a large-scale human interaction dataset, namely, FT-HID dataset. FT-HID contains pair-aligned samples of first person and third person visions. The dataset was collected from 109 distinct subjects and has more than 90K samples for three modalities. The dataset has been validated by using several existing action recognition methods. In addition, we introduce a novel multi-view interaction mechanism for skeleton sequences, and a joint learning multi-stream framework for first person and third person visions. Both methods yield promising results on the FT-HID dataset. It is expected that the introduction of this vision-aligned large-scale dataset will promote the development of both FPV and TPV, and their joint learning techniques for human action analysis. The dataset and code are available at \href{https://github.com/ENDLICHERE/FT-HID}{here}.
A Central Difference Graph Convolutional Operator for Skeleton-Based Action Recognition
Nov 13, 2021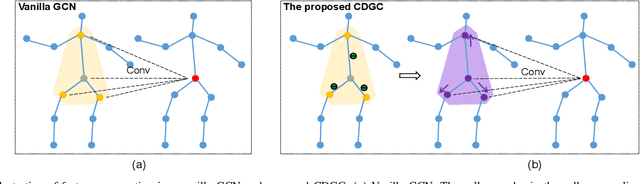
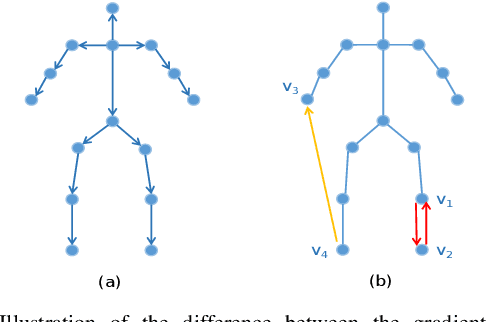
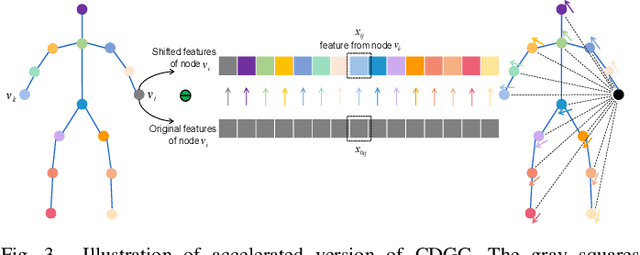
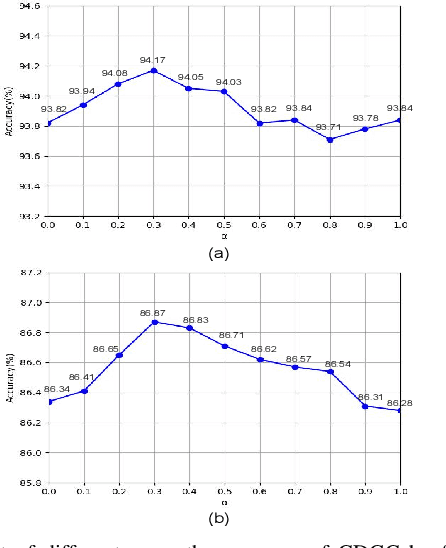
This paper proposes a new graph convolutional operator called central difference graph convolution (CDGC) for skeleton based action recognition. It is not only able to aggregate node information like a vanilla graph convolutional operation but also gradient information. Without introducing any additional parameters, CDGC can replace vanilla graph convolution in any existing Graph Convolutional Networks (GCNs). In addition, an accelerated version of the CDGC is developed which greatly improves the speed of training. Experiments on two popular large-scale datasets NTU RGB+D 60 & 120 have demonstrated the efficacy of the proposed CDGC. Code is available at https://github.com/iesymiao/CD-GCN.
Trear: Transformer-based RGB-D Egocentric Action Recognition
Jan 05, 2021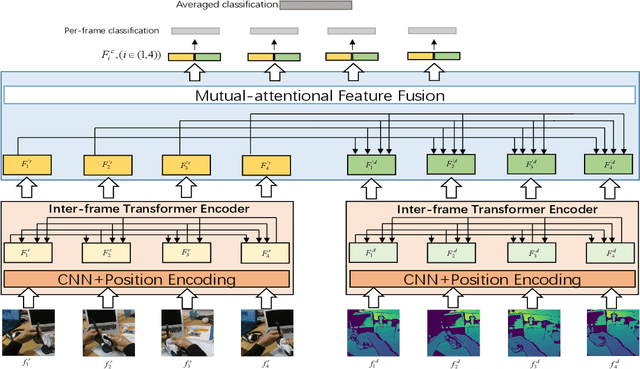
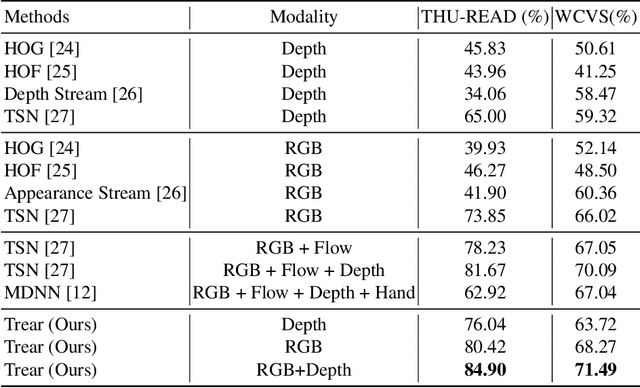
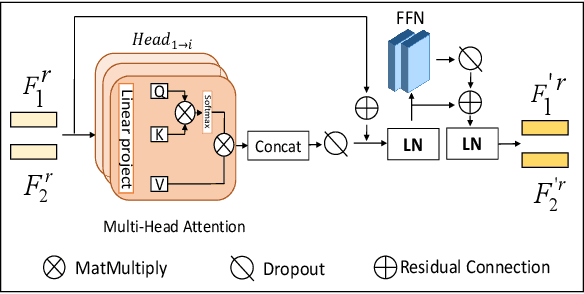
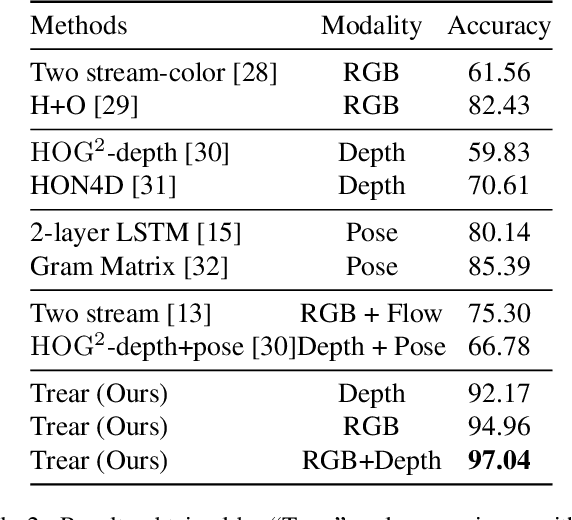
In this paper, we propose a \textbf{Tr}ansformer-based RGB-D \textbf{e}gocentric \textbf{a}ction \textbf{r}ecognition framework, called Trear. It consists of two modules, inter-frame attention encoder and mutual-attentional fusion block. Instead of using optical flow or recurrent units, we adopt self-attention mechanism to model the temporal structure of the data from different modalities. Input frames are cropped randomly to mitigate the effect of the data redundancy. Features from each modality are interacted through the proposed fusion block and combined through a simple yet effective fusion operation to produce a joint RGB-D representation. Empirical experiments on two large egocentric RGB-D datasets, THU-READ and FPHA, and one small dataset, WCVS, have shown that the proposed method outperforms the state-of-the-art results by a large margin.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020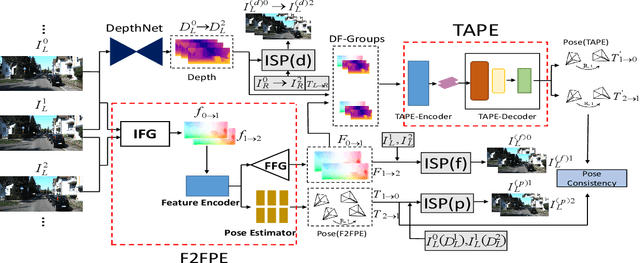
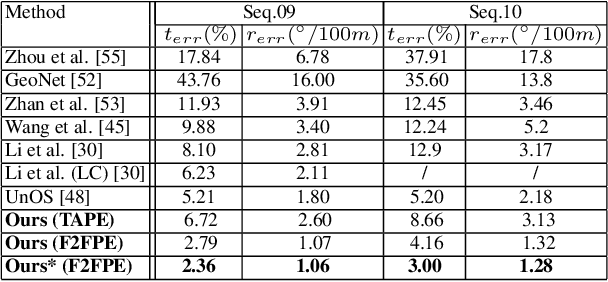
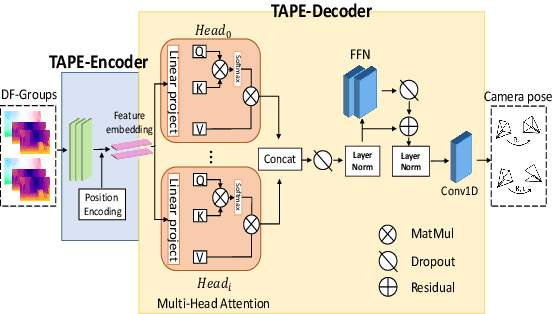
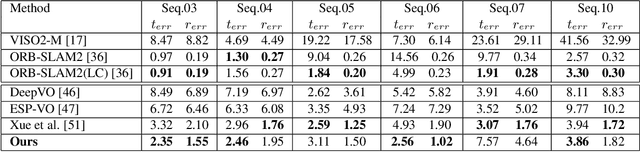
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.
Election with Bribed Voter Uncertainty: Hardness and Approximation Algorithm
Nov 07, 2018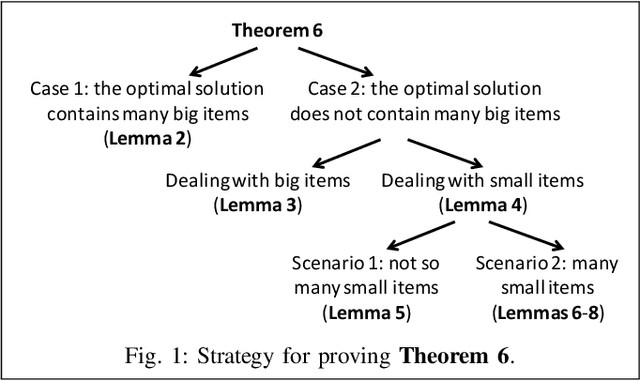
Bribery in election (or computational social choice in general) is an important problem that has received a considerable amount of attention. In the classic bribery problem, the briber (or attacker) bribes some voters in attempting to make the briber's designated candidate win an election. In this paper, we introduce a novel variant of the bribery problem, "Election with Bribed Voter Uncertainty" or BVU for short, accommodating the uncertainty that the vote of a bribed voter may or may not be counted. This uncertainty occurs either because a bribed voter may not cast its vote in fear of being caught, or because a bribed voter is indeed caught and therefore its vote is discarded. As a first step towards ultimately understanding and addressing this important problem, we show that it does not admit any multiplicative $O(1)$-approximation algorithm modulo standard complexity assumptions. We further show that there is an approximation algorithm that returns a solution with an additive-$\epsilon$ error in FPT time for any fixed $\epsilon$.
Depth Pooling Based Large-scale 3D Action Recognition with Convolutional Neural Networks
Apr 17, 2018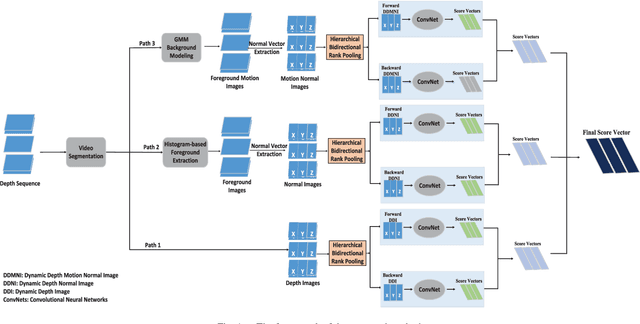
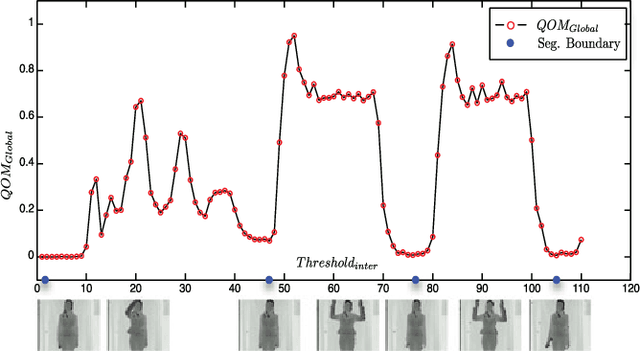
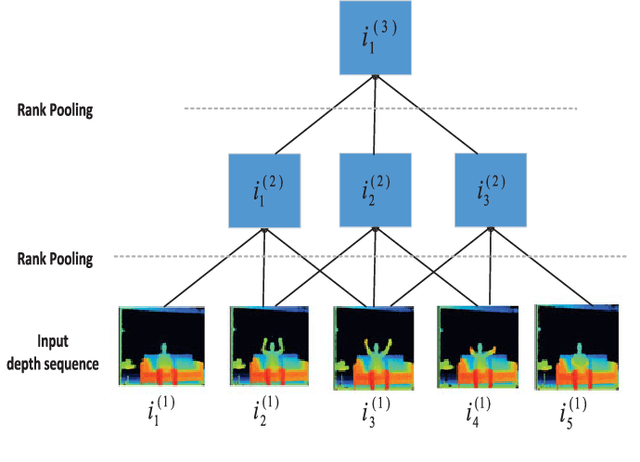
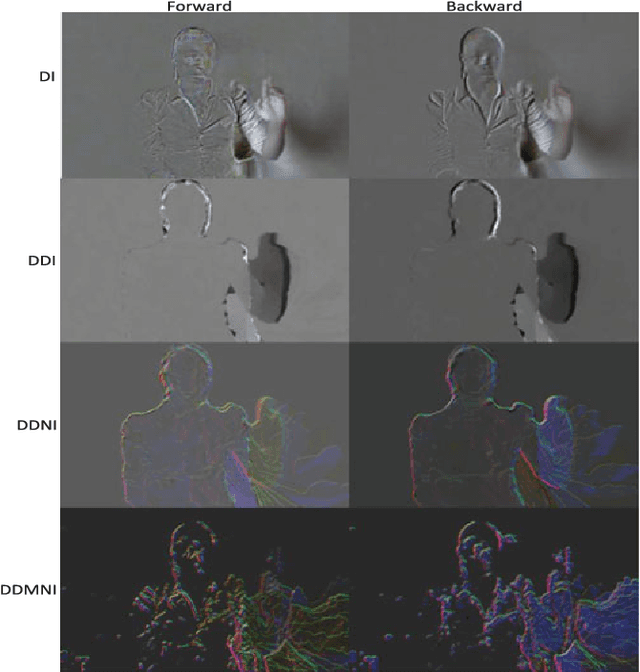
This paper proposes three simple, compact yet effective representations of depth sequences, referred to respectively as Dynamic Depth Images (DDI), Dynamic Depth Normal Images (DDNI) and Dynamic Depth Motion Normal Images (DDMNI), for both isolated and continuous action recognition. These dynamic images are constructed from a segmented sequence of depth maps using hierarchical bidirectional rank pooling to effectively capture the spatial-temporal information. Specifically, DDI exploits the dynamics of postures over time and DDNI and DDMNI exploit the 3D structural information captured by depth maps. Upon the proposed representations, a ConvNet based method is developed for action recognition. The image-based representations enable us to fine-tune the existing Convolutional Neural Network (ConvNet) models trained on image data without training a large number of parameters from scratch. The proposed method achieved the state-of-art results on three large datasets, namely, the Large-scale Continuous Gesture Recognition Dataset (means Jaccard index 0.4109), the Large-scale Isolated Gesture Recognition Dataset (59.21%), and the NTU RGB+D Dataset (87.08% cross-subject and 84.22% cross-view) even though only the depth modality was used.
Effective Neural Solution for Multi-Criteria Word Segmentation
Jan 04, 2018

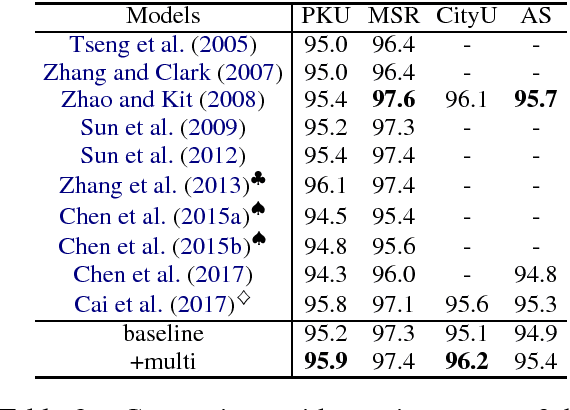
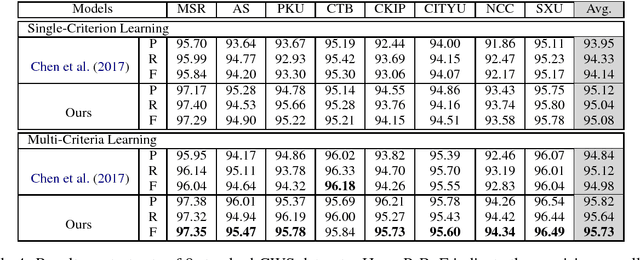
We present a simple yet elegant solution to train a single joint model on multi-criteria corpora for Chinese Word Segmentation (CWS). Our novel design requires no private layers in model architecture, instead, introduces two artificial tokens at the beginning and ending of input sentence to specify the required target criteria. The rest of the model including Long Short-Term Memory (LSTM) layer and Conditional Random Fields (CRFs) layer remains unchanged and is shared across all datasets, keeping the size of parameter collection minimal and constant. On Bakeoff 2005 and Bakeoff 2008 datasets, our innovative design has surpassed both single-criterion and multi-criteria state-of-the-art learning results. To the best knowledge, our design is the first one that has achieved the latest high performance on such large scale datasets. Source codes and corpora of this paper are available on GitHub.