 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobility-Aware Cache Framework for Scalable LLM-Based Human Mobility Simulation
Feb 17, 2026Large-scale human mobility simulation is critical for applications such as urban planning, epidemiology, and transportation analysis. Recent works treat large language models (LLMs) as human agents to simulate realistic mobility behaviors using structured reasoning, but their high computational cost limits scalability. To address this, we design a mobility-aware cache framework named MobCache that leverages reconstructible caches to enable efficient large-scale human mobility simulations. It consists of: (1) a reasoning component that encodes each reasoning step as a latent-space embedding and uses a latent-space evaluator to enable the reuse and recombination of reasoning steps; and (2) a decoding component that employs a lightweight decoder trained with mobility law-constrained distillation to translate latent-space reasoning chains into natural language, thereby improving simulation efficiency while maintaining fidelity. Experiments show that MobCache significantly improves efficiency across multiple dimensions while maintaining performance comparable to state-of-the-art LLM-based methods.
An Automatic Detection Method for Hematoma Features in Placental Abruption Ultrasound Images Based on Few-Shot Learning
Oct 24, 2025



Placental abruption is a severe complication during pregnancy, and its early accurate diagnosis is crucial for ensuring maternal and fetal safety. Traditional ultrasound diagnostic methods heavily rely on physician experience, leading to issues such as subjective bias and diagnostic inconsistencies. This paper proposes an improved model, EH-YOLOv11n (Enhanced Hemorrhage-YOLOv11n), based on small-sample learning, aiming to achieve automatic detection of hematoma features in placental ultrasound images. The model enhances performance through multidimensional optimization: it integrates wavelet convolution and coordinate convolution to strengthen frequency and spatial feature extraction; incorporates a cascaded group attention mechanism to suppress ultrasound artifacts and occlusion interference, thereby improving bounding box localization accuracy. Experimental results demonstrate a detection accuracy of 78%, representing a 2.5% improvement over YOLOv11n and a 13.7% increase over YOLOv8. The model exhibits significant superiority in precision-recall curves, confidence scores, and occlusion scenarios. Combining high accuracy with real-time processing, this model provides a reliable solution for computer-aided diagnosis of placental abruption, holding significant clinical application value.
LLM-Guided Reinforcement Learning: Addressing Training Bottlenecks through Policy Modulation
May 27, 2025While reinforcement learning (RL) has achieved notable success in various domains, training effective policies for complex tasks remains challenging. Agents often converge to local optima and fail to maximize long-term rewards. Existing approaches to mitigate training bottlenecks typically fall into two categories: (i) Automated policy refinement, which identifies critical states from past trajectories to guide policy updates, but suffers from costly and uncertain model training; and (ii) Human-in-the-loop refinement, where human feedback is used to correct agent behavior, but this does not scale well to environments with large or continuous action spaces. In this work, we design a large language model-guided policy modulation framework that leverages LLMs to improve RL training without additional model training or human intervention. We first prompt an LLM to identify critical states from a sub-optimal agent's trajectories. Based on these states, the LLM then provides action suggestions and assigns implicit rewards to guide policy refinement. Experiments across standard RL benchmarks demonstrate that our method outperforms state-of-the-art baselines, highlighting the effectiveness of LLM-based explanations in addressing RL training bottlenecks.
What makes a good data augmentation for few-shot unsupervised image anomaly detection?
Apr 21, 2023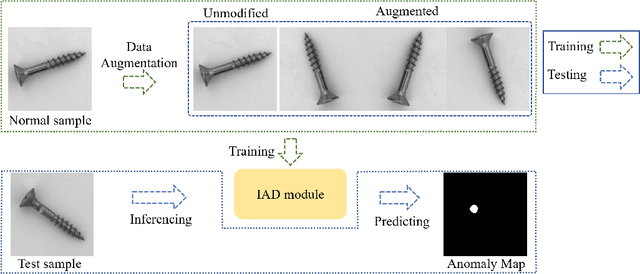



Data augmentation is a promising technique for unsupervised anomaly detection in industrial applications, where the availability of positive samples is often limited due to factors such as commercial competition and sample collection difficulties. In this paper, how to effectively select and apply data augmentation methods for unsupervised anomaly detection is studied. The impact of various data augmentation methods on different anomaly detection algorithms is systematically investigated through experiments. The experimental results show that the performance of different industrial image anomaly detection (termed as IAD) algorithms is not significantly affected by the specific data augmentation method employed and that combining multiple data augmentation methods does not necessarily yield further improvements in the accuracy of anomaly detection, although it can achieve excellent results on specific methods. These findings provide useful guidance on selecting appropriate data augmentation methods for different requirements in IAD.
Semi-Supervised Wide-Angle Portraits Correction by Multi-Scale Transformer
Sep 14, 2021
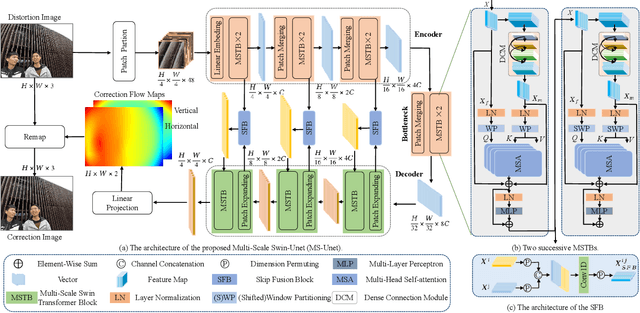
We propose a semi-supervised network for wide-angle portraits correction. Wide-angle images often suffer from skew and distortion affected by perspective distortion, especially noticeable at the face regions. Previous deep learning based approaches require the ground-truth correction flow maps for the training guidance. However, such labels are expensive, which can only be obtained manually. In this work, we propose a semi-supervised scheme, which can consume unlabeled data in addition to the labeled data for improvements. Specifically, our semi-supervised scheme takes the advantages of the consistency mechanism, with several novel components such as direction and range consistency (DRC) and regression consistency (RC). Furthermore, our network, named as Multi-Scale Swin-Unet (MS-Unet), is built upon the multi-scale swin transformer block (MSTB), which can learn both local-scale and long-range semantic information effectively. In addition, we introduce a high-quality unlabeled dataset with rich scenarios for the training. Extensive experiments demonstrate that the proposed method is superior over the state-of-the-art methods and other representative baselines.
SASICM A Multi-Task Benchmark For Subtext Recognition
Jul 04, 2021
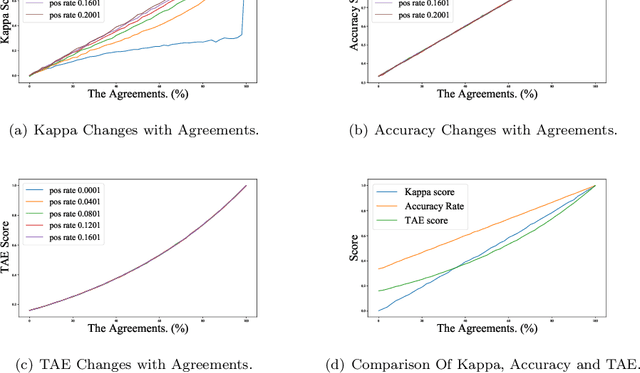

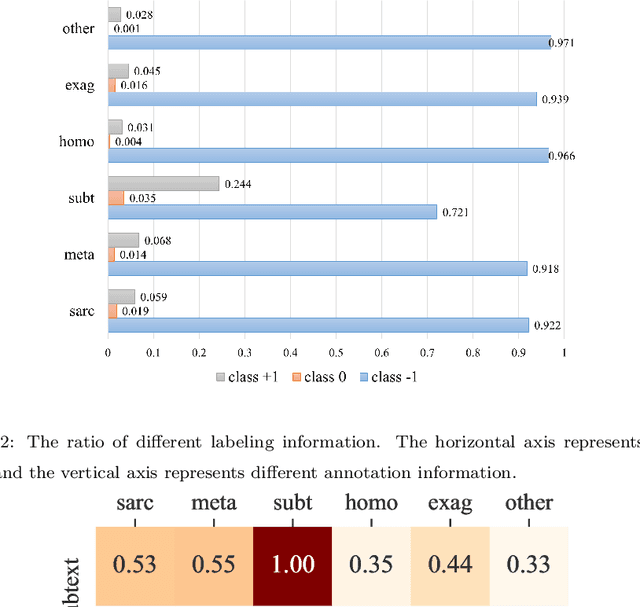
Subtext is a kind of deep semantics which can be acquired after one or more rounds of expression transformation. As a popular way of expressing one's intentions, it is well worth studying. In this paper, we try to make computers understand whether there is a subtext by means of machine learning. We build a Chinese dataset whose source data comes from the popular social media (e.g. Weibo, Netease Music, Zhihu, and Bilibili). In addition, we also build a baseline model called SASICM to deal with subtext recognition. The F1 score of SASICMg, whose pretrained model is GloVe, is as high as 64.37%, which is 3.97% higher than that of BERT based model, 12.7% higher than that of traditional methods on average, including support vector machine, logistic regression classifier, maximum entropy classifier, naive bayes classifier and decision tree and 2.39% higher than that of the state-of-the-art, including MARIN and BTM. The F1 score of SASICMBERT, whose pretrained model is BERT, is 65.12%, which is 0.75% higher than that of SASICMg. The accuracy rates of SASICMg and SASICMBERT are 71.16% and 70.76%, respectively, which can compete with those of other methods which are mentioned before.
Effective Neural Solution for Multi-Criteria Word Segmentation
Jan 04, 2018

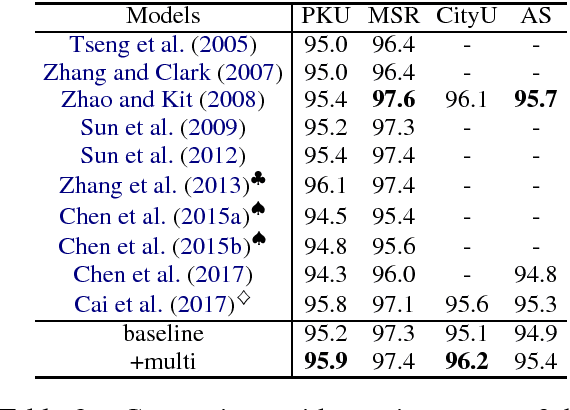
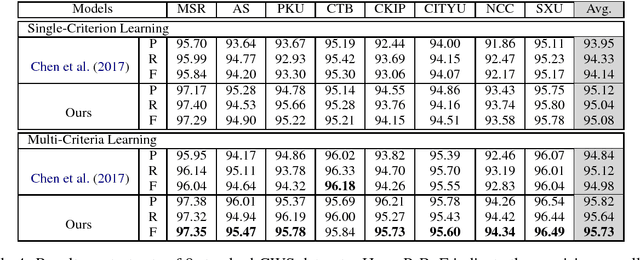
We present a simple yet elegant solution to train a single joint model on multi-criteria corpora for Chinese Word Segmentation (CWS). Our novel design requires no private layers in model architecture, instead, introduces two artificial tokens at the beginning and ending of input sentence to specify the required target criteria. The rest of the model including Long Short-Term Memory (LSTM) layer and Conditional Random Fields (CRFs) layer remains unchanged and is shared across all datasets, keeping the size of parameter collection minimal and constant. On Bakeoff 2005 and Bakeoff 2008 datasets, our innovative design has surpassed both single-criterion and multi-criteria state-of-the-art learning results. To the best knowledge, our design is the first one that has achieved the latest high performance on such large scale datasets. Source codes and corpora of this paper are available on GitHub.
Dual Long Short-Term Memory Networks for Sub-Character Representation Learning
Jan 04, 2018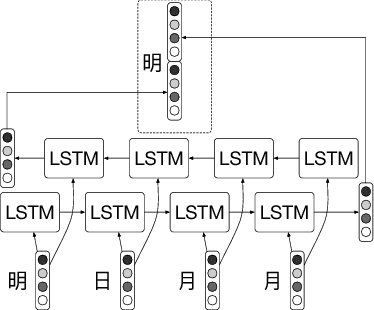
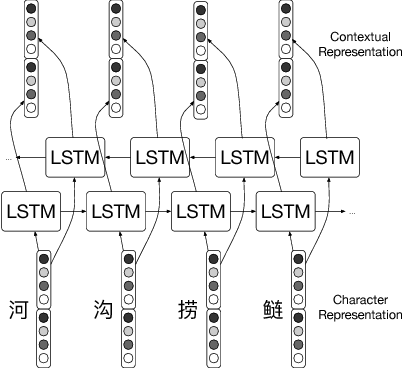
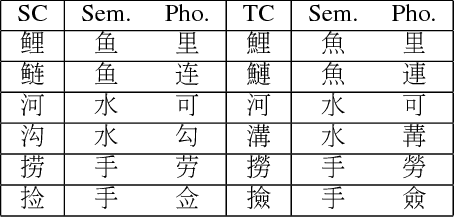
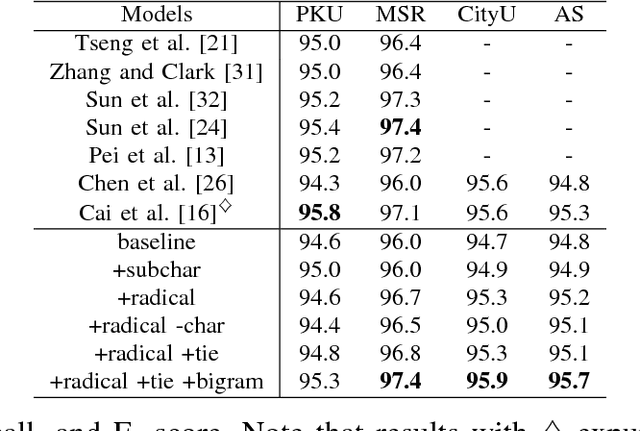
Characters have commonly been regarded as the minimal processing unit in Natural Language Processing (NLP). But many non-latin languages have hieroglyphic writing systems, involving a big alphabet with thousands or millions of characters. Each character is composed of even smaller parts, which are often ignored by the previous work. In this paper, we propose a novel architecture employing two stacked Long Short-Term Memory Networks (LSTMs) to learn sub-character level representation and capture deeper level of semantic meanings. To build a concrete study and substantiate the efficiency of our neural architecture, we take Chinese Word Segmentation as a research case example. Among those languages, Chinese is a typical case, for which every character contains several components called radicals. Our networks employ a shared radical level embedding to solve both Simplified and Traditional Chinese Word Segmentation, without extra Traditional to Simplified Chinese conversion, in such a highly end-to-end way the word segmentation can be significantly simplified compared to the previous work. Radical level embeddings can also capture deeper semantic meaning below character level and improve the system performance of learning. By tying radical and character embeddings together, the parameter count is reduced whereas semantic knowledge is shared and transferred between two levels, boosting the performance largely. On 3 out of 4 Bakeoff 2005 datasets, our method surpassed state-of-the-art results by up to 0.4%. Our results are reproducible, source codes and corpora are available on GitHub.