 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Neural Solution for Multi-Criteria Word Segmentation
Paper and Code


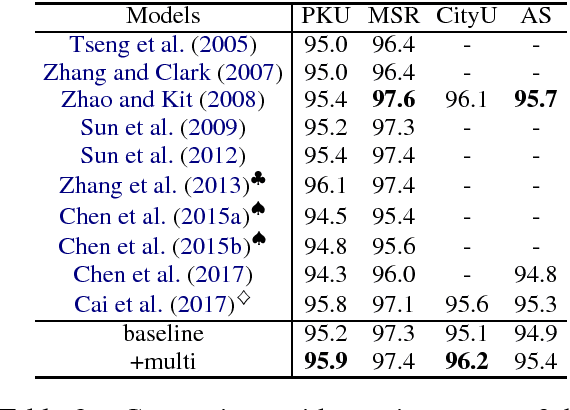
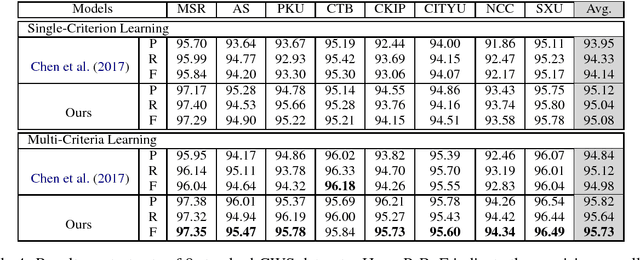
We present a simple yet elegant solution to train a single joint model on multi-criteria corpora for Chinese Word Segmentation (CWS). Our novel design requires no private layers in model architecture, instead, introduces two artificial tokens at the beginning and ending of input sentence to specify the required target criteria. The rest of the model including Long Short-Term Memory (LSTM) layer and Conditional Random Fields (CRFs) layer remains unchanged and is shared across all datasets, keeping the size of parameter collection minimal and constant. On Bakeoff 2005 and Bakeoff 2008 datasets, our innovative design has surpassed both single-criterion and multi-criteria state-of-the-art learning results. To the best knowledge, our design is the first one that has achieved the latest high performance on such large scale datasets. Source codes and corpora of this paper are available on GitHub.