 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Discrepancy and Cross-modal Semantic Consistency Learning for Object Detection in Hyperspectral Image
Dec 20, 2025Hyperspectral images with high spectral resolution provide new insights into recognizing subtle differences in similar substances. However, object detection in hyperspectral images faces significant challenges in intra- and inter-class similarity due to the spatial differences in hyperspectral inter-bands and unavoidable interferences, e.g., sensor noises and illumination. To alleviate the hyperspectral inter-bands inconsistencies and redundancy, we propose a novel network termed \textbf{S}pectral \textbf{D}iscrepancy and \textbf{C}ross-\textbf{M}odal semantic consistency learning (SDCM), which facilitates the extraction of consistent information across a wide range of hyperspectral bands while utilizing the spectral dimension to pinpoint regions of interest. Specifically, we leverage a semantic consistency learning (SCL) module that utilizes inter-band contextual cues to diminish the heterogeneity of information among bands, yielding highly coherent spectral dimension representations. On the other hand, we incorporate a spectral gated generator (SGG) into the framework that filters out the redundant data inherent in hyperspectral information based on the importance of the bands. Then, we design the spectral discrepancy aware (SDA) module to enrich the semantic representation of high-level information by extracting pixel-level spectral features. Extensive experiments on two hyperspectral datasets demonstrate that our proposed method achieves state-of-the-art performance when compared with other ones.
Smile on the Face, Sadness in the Eyes: Bridging the Emotion Gap with a Multimodal Dataset of Eye and Facial Behaviors
Dec 18, 2025Emotion Recognition (ER) is the process of analyzing and identifying human emotions from sensing data. Currently, the field heavily relies on facial expression recognition (FER) because visual channel conveys rich emotional cues. However, facial expressions are often used as social tools rather than manifestations of genuine inner emotions. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cue and construct an Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. To collect data with genuine emotions, spontaneous emotion induction paradigm is exploited with stimulus material, during which non-invasive eye behavior data, like eye movement sequences and eye fixation maps, is captured together with facial expression videos. To better illustrate the gap between ER and FER, multi-view emotion labels for mutimodal ER and FER are separately annotated. Furthermore, based on the new dataset, we design a simple yet effective Eye-behavior-aided MER Transformer (EMERT) that enhances ER by bridging the emotion gap. EMERT leverages modality-adversarial feature decoupling and a multitask Transformer to model eye behaviors as a strong complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance. Our EMER dataset and the trained EMERT models will be publicly available at https://github.com/kejun1/EMER.
When Genes Speak: A Semantic-Guided Framework for Spatially Resolved Transcriptomics Data Clustering
Nov 14, 2025Spatial transcriptomics enables gene expression profiling with spatial context, offering unprecedented insights into the tissue microenvironment. However, most computational models treat genes as isolated numerical features, ignoring the rich biological semantics encoded in their symbols. This prevents a truly deep understanding of critical biological characteristics. To overcome this limitation, we present SemST, a semantic-guided deep learning framework for spatial transcriptomics data clustering. SemST leverages Large Language Models (LLMs) to enable genes to "speak" through their symbolic meanings, transforming gene sets within each tissue spot into biologically informed embeddings. These embeddings are then fused with the spatial neighborhood relationships captured by Graph Neural Networks (GNNs), achieving a coherent integration of biological function and spatial structure. We further introduce the Fine-grained Semantic Modulation (FSM) module to optimally exploit these biological priors. The FSM module learns spot-specific affine transformations that empower the semantic embeddings to perform an element-wise calibration of the spatial features, thus dynamically injecting high-order biological knowledge into the spatial context. Extensive experiments on public spatial transcriptomics datasets show that SemST achieves state-of-the-art clustering performance. Crucially, the FSM module exhibits plug-and-play versatility, consistently improving the performance when integrated into other baseline methods.
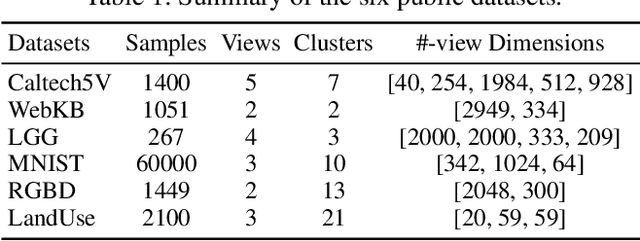
MoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025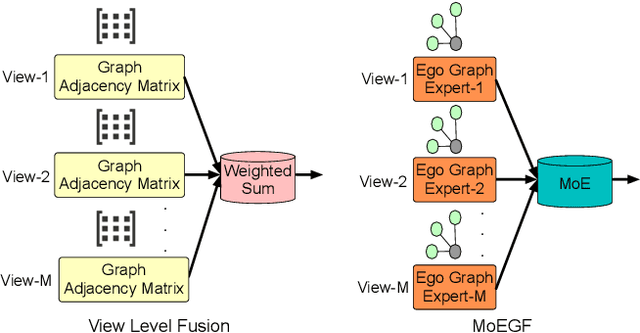
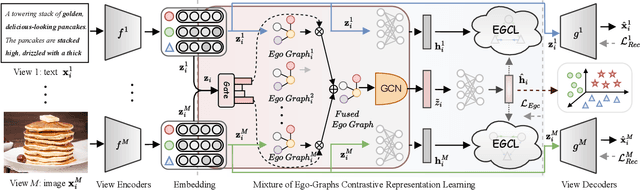
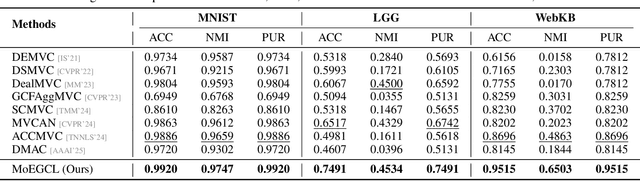
In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.
Generative Diffusion Contrastive Network for Multi-View Clustering
Sep 11, 2025In recent years, Multi-View Clustering (MVC) has been significantly advanced under the influence of deep learning. By integrating heterogeneous data from multiple views, MVC enhances clustering analysis, making multi-view fusion critical to clustering performance. However, there is a problem of low-quality data in multi-view fusion. This problem primarily arises from two reasons: 1) Certain views are contaminated by noisy data. 2) Some views suffer from missing data. This paper proposes a novel Stochastic Generative Diffusion Fusion (SGDF) method to address this problem. SGDF leverages a multiple generative mechanism for the multi-view feature of each sample. It is robust to low-quality data. Building on SGDF, we further present the Generative Diffusion Contrastive Network (GDCN). Extensive experiments show that GDCN achieves the state-of-the-art results in deep MVC tasks. The source code is publicly available at https://github.com/HackerHyper/GDCN.
Mask-informed Deep Contrastive Incomplete Multi-view Clustering
Feb 04, 2025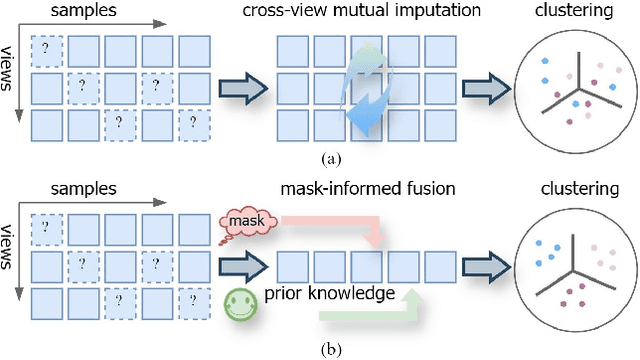
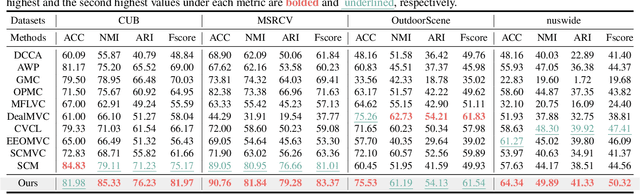
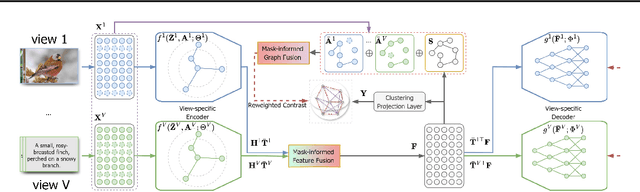
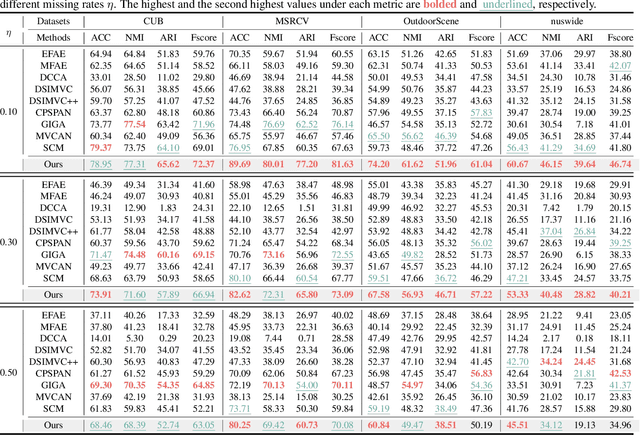
Multi-view clustering (MvC) utilizes information from multiple views to uncover the underlying structures of data. Despite significant advancements in MvC, mitigating the impact of missing samples in specific views on the integration of knowledge from different views remains a critical challenge. This paper proposes a novel Mask-informed Deep Contrastive Incomplete Multi-view Clustering (Mask-IMvC) method, which elegantly identifies a view-common representation for clustering. Specifically, we introduce a mask-informed fusion network that aggregates incomplete multi-view information while considering the observation status of samples across various views as a mask, thereby reducing the adverse effects of missing values. Additionally, we design a prior knowledge-assisted contrastive learning loss that boosts the representation capability of the aggregated view-common representation by injecting neighborhood information of samples from different views. Finally, extensive experiments are conducted to demonstrate the superiority of the proposed Mask-IMvC method over state-of-the-art approaches across multiple MvC datasets, both in complete and incomplete scenarios.
Balanced Multi-view Clustering
Jan 05, 2025



Multi-view clustering (MvC) aims to integrate information from different views to enhance the capability of the model in capturing the underlying data structures. The widely used joint training paradigm in MvC is potentially not fully leverage the multi-view information, since the imbalanced and under-optimized view-specific features caused by the uniform learning objective for all views. For instance, particular views with more discriminative information could dominate the learning process in the joint training paradigm, leading to other views being under-optimized. To alleviate this issue, we first analyze the imbalanced phenomenon in the joint-training paradigm of multi-view clustering from the perspective of gradient descent for each view-specific feature extractor. Then, we propose a novel balanced multi-view clustering (BMvC) method, which introduces a view-specific contrastive regularization (VCR) to modulate the optimization of each view. Concretely, VCR preserves the sample similarities captured from the joint features and view-specific ones into the clustering distributions corresponding to view-specific features to enhance the learning process of view-specific feature extractors. Additionally, a theoretical analysis is provided to illustrate that VCR adaptively modulates the magnitudes of gradients for updating the parameters of view-specific feature extractors to achieve a balanced multi-view learning procedure. In such a manner, BMvC achieves a better trade-off between the exploitation of view-specific patterns and the exploration of view-invariance patterns to fully learn the multi-view information for the clustering task. Finally, a set of experiments are conducted to verify the superiority of the proposed method compared with state-of-the-art approaches both on eight benchmark MvC datasets and two spatially resolved transcriptomics datasets.
Trusted Mamba Contrastive Network for Multi-View Clustering
Dec 21, 2024



Multi-view clustering can partition data samples into their categories by learning a consensus representation in an unsupervised way and has received more and more attention in recent years. However, there is an untrusted fusion problem. The reasons for this problem are as follows: 1) The current methods ignore the presence of noise or redundant information in the view; 2) The similarity of contrastive learning comes from the same sample rather than the same cluster in deep multi-view clustering. It causes multi-view fusion in the wrong direction. This paper proposes a novel multi-view clustering network to address this problem, termed as Trusted Mamba Contrastive Network (TMCN). Specifically, we present a new Trusted Mamba Fusion Network (TMFN), which achieves a trusted fusion of multi-view data through a selective mechanism. Moreover, we align the fused representation and the view-specific representation using the Average-similarity Contrastive Learning (AsCL) module. AsCL increases the similarity of view presentation from the same cluster, not merely from the same sample. Extensive experiments show that the proposed method achieves state-of-the-art results in deep multi-view clustering tasks.
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models
Oct 04, 2024
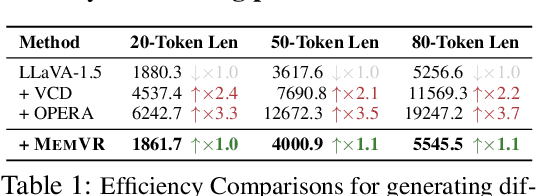
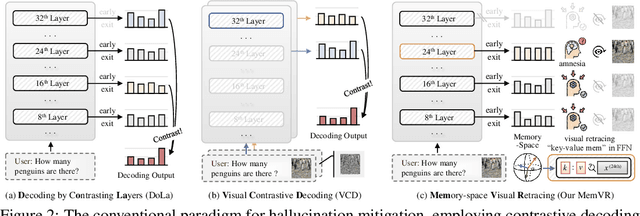
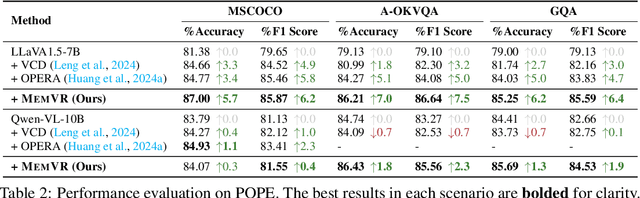
Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) are susceptible to hallucinations, especially assertively fabricating content not present in the visual inputs. To address the aforementioned challenge, we follow a common cognitive process - when one's initial memory of critical on-sight details fades, it is intuitive to look at them a second time to seek a factual and accurate answer. Therefore, we introduce Memory-space Visual Retracing (MemVR), a novel hallucination mitigation paradigm that without the need for external knowledge retrieval or additional fine-tuning. In particular, we treat visual prompts as supplementary evidence to be reinjected into MLLMs via Feed Forward Network (FFN) as key-value memory, when the model is uncertain or even amnesic about question-relevant visual memories. Comprehensive experimental evaluations demonstrate that MemVR significantly mitigates hallucination issues across various MLLMs and excels in general benchmarks without incurring added time overhead, thus emphasizing its potential for widespread applicability.
Learning to Discover Generalized Facial Expressions
Sep 30, 2024



We introduce Facial Expression Category Discovery (FECD), a novel task in the domain of open-world facial expression recognition (O-FER). While Generalized Category Discovery (GCD) has been explored in natural image datasets, applying it to facial expressions presents unique challenges. Specifically, we identify two key biases to better understand these challenges: Theoretical Bias-arising from the introduction of new categories in unlabeled training data, and Practical Bias-stemming from the imbalanced and fine-grained nature of facial expression data. To address these challenges, we propose FER-GCD, an adversarial approach that integrates both implicit and explicit debiasing components. In the implicit debiasing process, we devise F-discrepancy, a novel metric used to estimate the upper bound of Theoretical Bias, helping the model minimize this upper bound through adversarial training. The explicit debiasing process further optimizes the feature generator and classifier to reduce Practical Bias. Extensive experiments on GCD-based FER datasets demonstrate that our FER-GCD framework significantly improves accuracy on both old and new categories, achieving an average improvement of 9.8% over the baseline and outperforming state-of-the-art methods.