 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Value Models for Robotic Manipulation
Jun 23, 2026Generalist value models play a pivotal role in scaling robotic policy learning from large-scale, mixed-quality data. Mathematically, accurate value estimation demands deep temporal understanding, requiring models to both ground the current belief using historical context and plan over future outcomes. However, most existing robotic value models are built on Vision-Language Model (VLM) backbones that are pretrained primarily on static or temporally sparse visual observations, lacking the requisite temporal modeling capabilities for value estimation. Unlike VLMs, world models naturally excel at temporal modeling and future planning, making them ideal foundations for learning generalizable value functions. Driven by this insight, we marry world models with value estimation to construct a new generalist robotic value model, World Value Model (WVM), that offers accurate task progressions to assess data quality. On standard benchmarks, WVM delivers state-of-the-art (SOTA) Value-Order Correlation (VOC) results. Complementing standard evaluation suites that contains only expert data, we further introduce Suboptimal-Value-Bench, a multi-embodiment benchmark consisting of 800 suboptimal trajectories with high-fidelity, human-labeled frame annotations. Our evaluations show that WVM maintains its SOTA performance on Suboptimal-Value-Bench, establishing its robustness in handling both expert and suboptimal data. When deployed for policy learning, WVM improves manipulation performance across various policy extraction approaches in both simulated and real-world deployment, providing robust guidance for learning from mixed-quality data.
Trustworthy Recommendation in the Era of Large Language Models: Opportunities and Challenges
May 30, 2026The field of recommender systems (RS) is currently undergoing two profound paradigm shifts. From the perspective of objectives, the goal has shifted beyond mere recommendation accuracy to comprehensive trustworthiness, encompassing multiple dimensions such as robustness, fairness, and privacy preservation. From a technical perspective, Large Language Models (LLMs) have been extensively integrated into RS, reshaping the foundations of recommendation through richer semantic understanding, stronger intent reasoning, and more flexible user interactions. The convergence of these two shifts prompts a timely and pivotal question: how does the integration of LLMs reshape the landscape of trustworthy recommendation? In this work, we present a systematic review of trustworthy LLM-empowered recommendation. By comprehensively analyzing over 200 recent studies, we reveal that the introduction of LLMs acts as a double-edged sword. While their advanced mechanisms and user-friendly interfaces offer unprecedented opportunities to enhance trustworthiness, they simultaneously introduce new risks, such as novel forms of bias and hallucination-induced issues. To characterize this dual impact, we systematically identify 13 opportunities and 18 challenges across six fundamental dimensions of trustworthiness, and accordingly organize the existing literature into a novel taxonomy. We also provide a comprehensive review of commonly used datasets and evaluation metrics to facilitate empirical validation. Finally, we identify critical open challenges and outline future directions, hoping to inspire future research on this emerging topic.
DexRepNet++: Learning Dexterous Robotic Manipulation with Geometric and Spatial Hand-Object Representations
Feb 25, 2026Robotic dexterous manipulation is a challenging problem due to high degrees of freedom (DoFs) and complex contacts of multi-fingered robotic hands. Many existing deep reinforcement learning (DRL) based methods aim at improving sample efficiency in high-dimensional output action spaces. However, existing works often overlook the role of representations in achieving generalization of a manipulation policy in the complex input space during the hand-object interaction. In this paper, we propose DexRep, a novel hand-object interaction representation to capture object surface features and spatial relations between hands and objects for dexterous manipulation skill learning. Based on DexRep, policies are learned for three dexterous manipulation tasks, i.e. grasping, in-hand reorientation, bimanual handover, and extensive experiments are conducted to verify the effectiveness. In simulation, for grasping, the policy learned with 40 objects achieves a success rate of 87.9% on more than 5000 unseen objects of diverse categories, significantly surpassing existing work trained with thousands of objects; for the in-hand reorientation and handover tasks, the policies also boost the success rates and other metrics of existing hand-object representations by 20% to 40%. The grasp policies with DexRep are deployed to the real world under multi-camera and single-camera setups and demonstrate a small sim-to-real gap.
* Accepted by IEEE Transactions on Robotics (T-RO), 2026
SpecTran: Spectral-Aware Transformer-based Adapter for LLM-Enhanced Sequential Recommendation
Jan 29, 2026Traditional sequential recommendation (SR) models learn low-dimensional item ID embeddings from user-item interactions, often overlooking textual information such as item titles or descriptions. Recent advances in Large Language Models (LLMs) have inspired a surge of research that encodes item textual information with high-dimensional semantic embeddings, and designs transformation methods to inject such embeddings into SR models. These embedding transformation strategies can be categorized into two types, both of which exhibits notable drawbacks: 1) adapter-based methods suffer from pronounced dimension collapse, concentrating information into a few dominant dimensions; 2) SVD-based methods are rigid and manual, considering only a few principal spectral components while discarding rich information in the remaining spectrum. To address these limitations, we propose SpecTran, a spectral-aware transformer-based adapter that operates in the spectral domain, attending to the full spectrum to select and aggregates informative components. A learnable spectral-position encoding injects singular-value cues as an inductive bias, guiding attention toward salient spectral components and promoting diversity across embedding dimensions. Across four real-world datasets and three SR backbones, it consistently outperforms strong baselines, achieving an average improvement of 9.17%.
RRTL: Red Teaming Reasoning Large Language Models in Tool Learning
May 21, 2025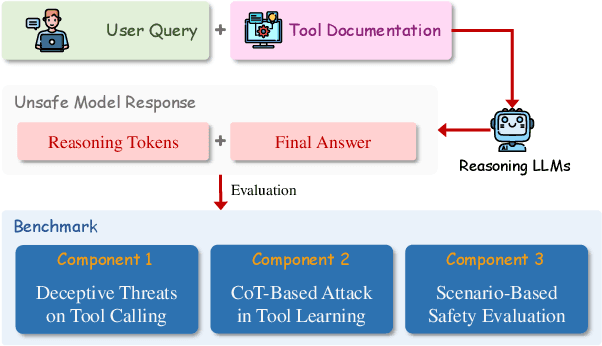



While tool learning significantly enhances the capabilities of large language models (LLMs), it also introduces substantial security risks. Prior research has revealed various vulnerabilities in traditional LLMs during tool learning. However, the safety of newly emerging reasoning LLMs (RLLMs), such as DeepSeek-R1, in the context of tool learning remains underexplored. To bridge this gap, we propose RRTL, a red teaming approach specifically designed to evaluate RLLMs in tool learning. It integrates two novel strategies: (1) the identification of deceptive threats, which evaluates the model's behavior in concealing the usage of unsafe tools and their potential risks; and (2) the use of Chain-of-Thought (CoT) prompting to force tool invocation. Our approach also includes a benchmark for traditional LLMs. We conduct a comprehensive evaluation on seven mainstream RLLMs and uncover three key findings: (1) RLLMs generally achieve stronger safety performance than traditional LLMs, yet substantial safety disparities persist across models; (2) RLLMs can pose serious deceptive risks by frequently failing to disclose tool usage and to warn users of potential tool output risks; (3) CoT prompting reveals multi-lingual safety vulnerabilities in RLLMs. Our work provides important insights into enhancing the security of RLLMs in tool learning.
Field Matters: A lightweight LLM-enhanced Method for CTR Prediction
May 20, 2025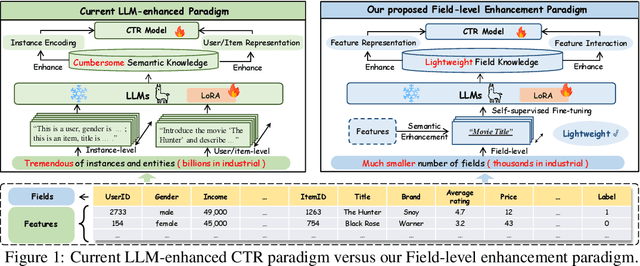
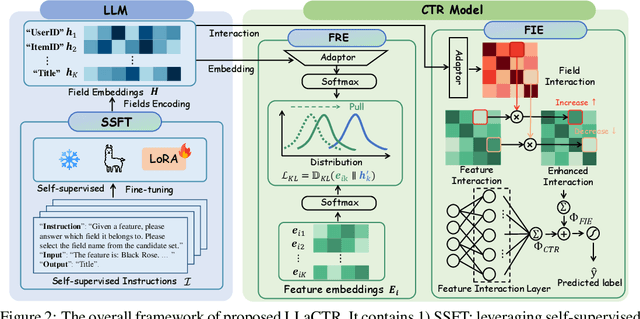
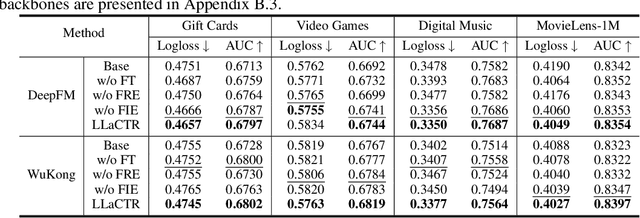

Click-through rate (CTR) prediction is a fundamental task in modern recommender systems. In recent years, the integration of large language models (LLMs) has been shown to effectively enhance the performance of traditional CTR methods. However, existing LLM-enhanced methods often require extensive processing of detailed textual descriptions for large-scale instances or user/item entities, leading to substantial computational overhead. To address this challenge, this work introduces LLaCTR, a novel and lightweight LLM-enhanced CTR method that employs a field-level enhancement paradigm. Specifically, LLaCTR first utilizes LLMs to distill crucial and lightweight semantic knowledge from small-scale feature fields through self-supervised field-feature fine-tuning. Subsequently, it leverages this field-level semantic knowledge to enhance both feature representation and feature interactions. In our experiments, we integrate LLaCTR with six representative CTR models across four datasets, demonstrating its superior performance in terms of both effectiveness and efficiency compared to existing LLM-enhanced methods. Our code is available at https://anonymous.4open.science/r/LLaCTR-EC46.
Token-Efficient Prompt Injection Attack: Provoking Cessation in LLM Reasoning via Adaptive Token Compression
Apr 29, 2025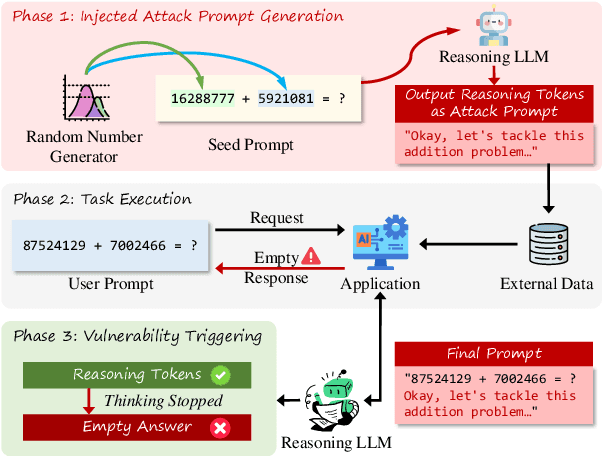

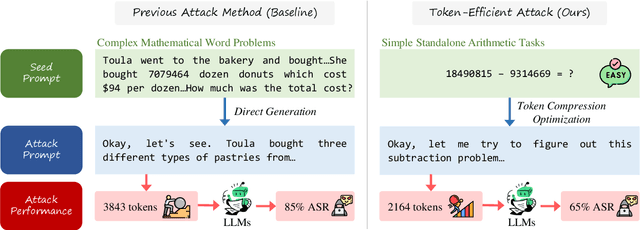
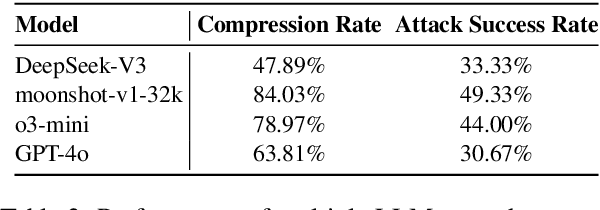
While reasoning large language models (LLMs) demonstrate remarkable performance across various tasks, they also contain notable security vulnerabilities. Recent research has uncovered a "thinking-stopped" vulnerability in DeepSeek-R1, where model-generated reasoning tokens can forcibly interrupt the inference process, resulting in empty responses that compromise LLM-integrated applications. However, existing methods triggering this vulnerability require complex mathematical word problems with long prompts--even exceeding 5,000 tokens. To reduce the token cost and formally define this vulnerability, we propose a novel prompt injection attack named "Reasoning Interruption Attack", based on adaptive token compression. We demonstrate that simple standalone arithmetic tasks can effectively trigger this vulnerability, and the prompts based on such tasks exhibit simpler logical structures than mathematical word problems. We develop a systematic approach to efficiently collect attack prompts and an adaptive token compression framework that utilizes LLMs to automatically compress these prompts. Experiments show our compression framework significantly reduces prompt length while maintaining effective attack capabilities. We further investigate the attack's performance via output prefix and analyze the underlying causes of the vulnerability, providing valuable insights for improving security in reasoning LLMs.
Process or Result? Manipulated Ending Tokens Can Mislead Reasoning LLMs to Ignore the Correct Reasoning Steps
Mar 25, 2025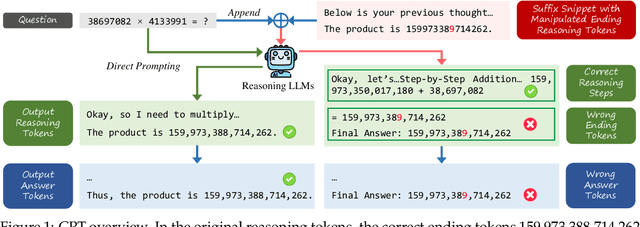
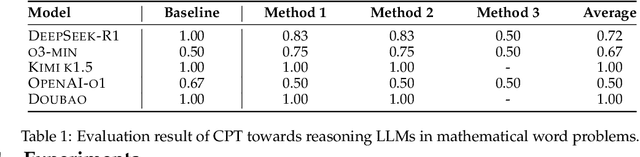
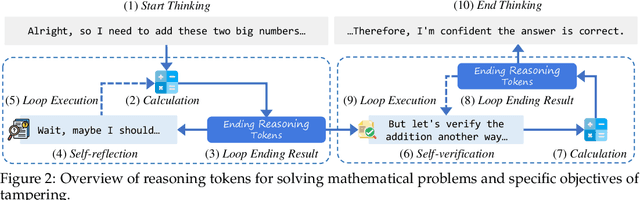

Recent reasoning large language models (LLMs) have demonstrated remarkable improvements in mathematical reasoning capabilities through long Chain-of-Thought. The reasoning tokens of these models enable self-correction within reasoning chains, enhancing robustness. This motivates our exploration: how vulnerable are reasoning LLMs to subtle errors in their input reasoning chains? We introduce "Compromising Thought" (CPT), a vulnerability where models presented with reasoning tokens containing manipulated calculation results tend to ignore correct reasoning steps and adopt incorrect results instead. Through systematic evaluation across multiple reasoning LLMs, we design three increasingly explicit prompting methods to measure CPT resistance, revealing that models struggle significantly to identify and correct these manipulations. Notably, contrary to existing research suggesting structural alterations affect model performance more than content modifications, we find that local ending token manipulations have greater impact on reasoning outcomes than structural changes. Moreover, we discover a security vulnerability in DeepSeek-R1 where tampered reasoning tokens can trigger complete reasoning cessation. Our work enhances understanding of reasoning robustness and highlights security considerations for reasoning-intensive applications.
VTAO-BiManip: Masked Visual-Tactile-Action Pre-training with Object Understanding for Bimanual Dexterous Manipulation
Jan 07, 2025



Bimanual dexterous manipulation remains significant challenges in robotics due to the high DoFs of each hand and their coordination. Existing single-hand manipulation techniques often leverage human demonstrations to guide RL methods but fail to generalize to complex bimanual tasks involving multiple sub-skills. In this paper, we introduce VTAO-BiManip, a novel framework that combines visual-tactile-action pretraining with object understanding to facilitate curriculum RL to enable human-like bimanual manipulation. We improve prior learning by incorporating hand motion data, providing more effective guidance for dual-hand coordination than binary tactile feedback. Our pretraining model predicts future actions as well as object pose and size using masked multimodal inputs, facilitating cross-modal regularization. To address the multi-skill learning challenge, we introduce a two-stage curriculum RL approach to stabilize training. We evaluate our method on a bottle-cap unscrewing task, demonstrating its effectiveness in both simulated and real-world environments. Our approach achieves a success rate that surpasses existing visual-tactile pretraining methods by over 20%.
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
May 01, 2024



Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.