 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANCET: Neural Intervention via Structural Entropy for Mitigating Faithfulness Hallucinations in LLMs
Jan 04, 2026Large Language Models have revolutionized information processing, yet their reliability is severely compromised by faithfulness hallucinations. While current approaches attempt to mitigate this issue through node-level adjustments or coarse suppression, they often overlook the distributed nature of neural information, leading to imprecise interventions. Recognizing that hallucinations propagate through specific forward transmission pathways like an infection, we aim to surgically block this flow using precise structural analysis. To leverage this, we propose Lancet, a novel framework that achieves precise neural intervention by leveraging structural entropy and hallucination difference ratios. Lancet first locates hallucination-prone neurons via gradient-driven contrastive analysis, then maps their propagation pathways by minimizing structural entropy, and finally implements a hierarchical intervention strategy that preserves general model capabilities. Comprehensive evaluations across hallucination benchmark datasets demonstrate that Lancet significantly outperforms state-of-the-art methods, validating the effectiveness of our surgical approach to neural intervention.
BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
Dec 12, 2025The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the standard attention mechanism. To address this challenge, we introduce BLASST, a drop-in sparse attention method that dynamically prunes the attention matrix without any pre-computation or proxy scores. Our method uses a fixed threshold and existing information from online softmax to identify negligible attention scores, skipping softmax computation, Value block loading, and the subsequent matrix multiplication. This fits seamlessly into existing FlashAttention kernel designs with negligible latency overhead. The approach is applicable to both prefill and decode stages across all attention variants (MHA, GQA, MQA, and MLA), providing a unified solution for accelerating long-context inference. We develop an automated calibration procedure that reveals a simple inverse relationship between optimal threshold and context length, enabling robust deployment across diverse scenarios. Maintaining high accuracy, we demonstrate a 1.62x speedup for prefill at 74.7% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs. Furthermore, we explore sparsity-aware training as a natural extension, showing that models can be trained to be inherently more robust to sparse attention patterns, pushing the accuracy-sparsity frontier even further.
AlphaNet: Scaling Up Local Frame-based Atomistic Foundation Model
Jan 13, 2025
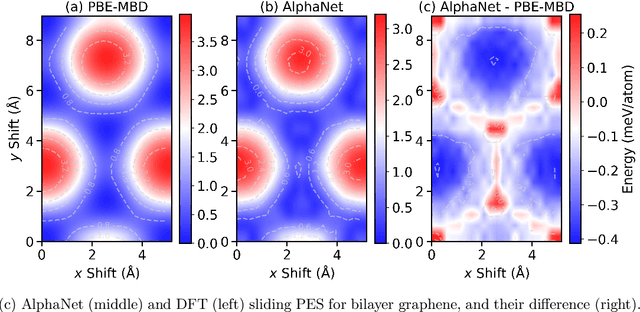
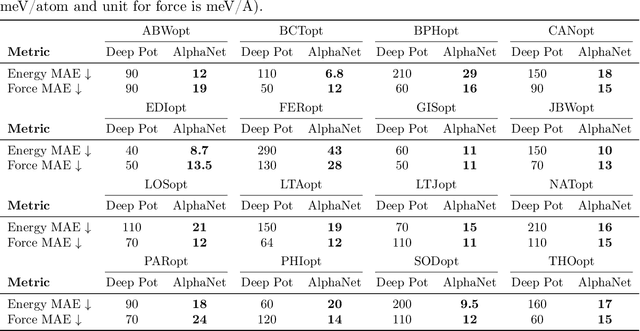
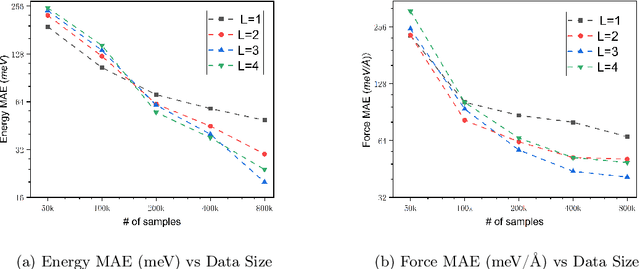
We present AlphaNet, a local frame-based equivariant model designed to achieve both accurate and efficient simulations for atomistic systems. Recently, machine learning force fields (MLFFs) have gained prominence in molecular dynamics simulations due to their advantageous efficiency-accuracy balance compared to classical force fields and quantum mechanical calculations, alongside their transferability across various systems. Despite the advancements in improving model accuracy, the efficiency and scalability of MLFFs remain significant obstacles in practical applications. AlphaNet enhances computational efficiency and accuracy by leveraging the local geometric structures of atomic environments through the construction of equivariant local frames and learnable frame transitions. We substantiate the efficacy of AlphaNet across diverse datasets, including defected graphene, formate decomposition, zeolites, and surface reactions. AlphaNet consistently surpasses well-established models, such as NequIP and DeepPot, in terms of both energy and force prediction accuracy. Notably, AlphaNet offers one of the best trade-offs between computational efficiency and accuracy among existing models. Moreover, AlphaNet exhibits scalability across a broad spectrum of system and dataset sizes, affirming its versatility.
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
May 01, 2024



Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Quick and Reliable LoRa Physical-layer Data Aggregation through Multi-Packet Reception
Dec 13, 2022This paper presents a Long Range (LoRa) physical-layer data aggregation system (LoRaPDA) that aggregates data (e.g., sum, average, min, max) directly in the physical layer. In particular, after coordinating a few nodes to transmit their data simultaneously, the gateway leverages a new multi-packet reception (MPR) approach to compute aggregate data from the phase-asynchronous superimposed signal. Different from the analog approach which requires additional power synchronization and phase synchronization, our MRP-based digital approach is compatible with commercial LoRa nodes and is more reliable. Different from traditional MPR approaches that are designed for the collision decoding scenario, our new MPR approach allows simultaneous transmissions with small packet arrival time offsets, and addresses a new co-located peak problem through the following components: 1) an improved channel and offset estimation algorithm that enables accurate phase tracking in each symbol, 2) a new symbol demodulation algorithm that finds the maximum likelihood sequence of nodes' data, and 3) a soft-decision packet decoding algorithm that utilizes the likelihoods of several sequences to improve decoding performance. Trace-driven simulation results show that the symbol demodulation algorithm outperforms the state-of-the-art MPR decoder by 5.3$\times$ in terms of physical-layer throughput, and the soft decoder is more robust to unavoidable adverse phase misalignment and estimation error in practice. Moreover, LoRaPDA outperforms the state-of-the-art MPR scheme by at least 2.1$\times$ for all SNRs in terms of network throughput, demonstrating quick and reliable data aggregation.
Evaluating the Practicality of Learned Image Compression
Jul 29, 2022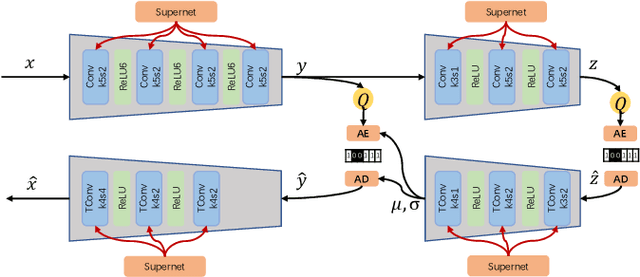
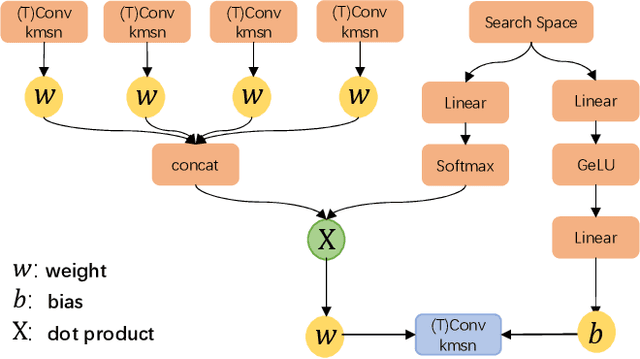
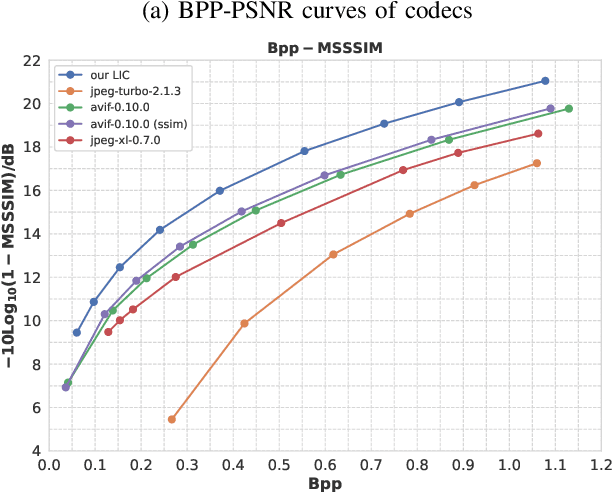
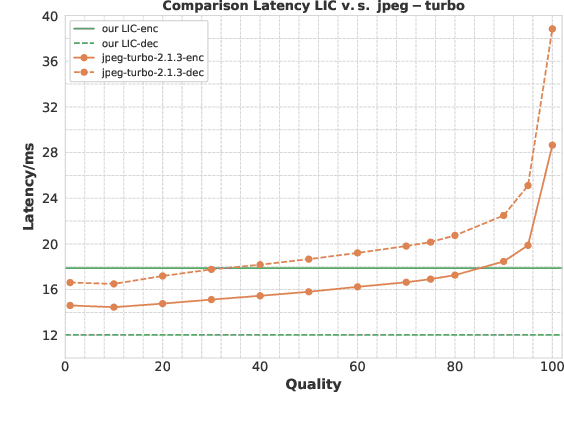
Learned image compression has achieved extraordinary rate-distortion performance in PSNR and MS-SSIM compared to traditional methods. However, it suffers from intensive computation, which is intolerable for real-world applications and leads to its limited industrial application for now. In this paper, we introduce neural architecture search (NAS) to designing more efficient networks with lower latency, and leverage quantization to accelerate the inference process. Meanwhile, efforts in engineering like multi-threading and SIMD have been made to improve efficiency. Optimized using a hybrid loss of PSNR and MS-SSIM for better visual quality, we obtain much higher MS-SSIM than JPEG, JPEG XL and AVIF over all bit rates, and PSNR between that of JPEG XL and AVIF. Our software implementation of LIC achieves comparable or even faster inference speed compared to jpeg-turbo while being multiple times faster than JPEG XL and AVIF. Besides, our implementation of LIC reaches stunning throughput of 145 fps for encoding and 208 fps for decoding on a Tesla T4 GPU for 1080p images. On CPU, the latency of our implementation is comparable with JPEG XL.