 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage2Matter: A Physically Grounded Gaussian World Model from Video
Jan 24, 2026The scalability of embodied intelligence is fundamentally constrained by the scarcity of real-world interaction data. While simulation platforms provide a promising alternative, existing approaches often suffer from a substantial visual and physical gap to real environments and rely on expensive sensors, precise robot calibration, or depth measurements, limiting their practicality at scale. We present Simulate Anything, a graphics-driven world modeling and simulation framework that enables efficient generation of high-fidelity embodied training data using only multi-view environment videos and off-the-shelf assets. Our approach reconstructs real-world environments into a photorealistic scene representation using 3D Gaussian Splatting (3DGS), seamlessly capturing fine-grained geometry and appearance from video. We then leverage generative models to recover a physically realistic representation and integrate it into a simulation environment via a precision calibration target, enabling accurate scale alignment between the reconstructed scene and the real world. Together, these components provide a unified, editable, and physically grounded world model. Vision Language Action (VLA) models trained on our simulated data achieve strong zero-shot performance on downstream tasks, matching or even surpassing results obtained with real-world data, highlighting the potential of reconstruction-driven world modeling for scalable and practical embodied intelligence training.
Reconstructing Building Height from Spaceborne TomoSAR Point Clouds Using a Dual-Topology Network
Jan 02, 2026Reliable building height estimation is essential for various urban applications. Spaceborne SAR tomography (TomoSAR) provides weather-independent, side-looking observations that capture facade-level structure, offering a promising alternative to conventional optical methods. However, TomoSAR point clouds often suffer from noise, anisotropic point distributions, and data voids on incoherent surfaces, all of which hinder accurate height reconstruction. To address these challenges, we introduce a learning-based framework for converting raw TomoSAR points into high-resolution building height maps. Our dual-topology network alternates between a point branch that models irregular scatterer features and a grid branch that enforces spatial consistency. By jointly processing these representations, the network denoises the input points and inpaints missing regions to produce continuous height estimates. To our knowledge, this is the first proof of concept for large-scale urban height mapping directly from TomoSAR point clouds. Extensive experiments on data from Munich and Berlin validate the effectiveness of our approach. Moreover, we demonstrate that our framework can be extended to incorporate optical satellite imagery, further enhancing reconstruction quality. The source code is available at https://github.com/zhu-xlab/tomosar2height.
HeartBench: Probing Core Dimensions of Anthropomorphic Intelligence in LLMs
Dec 26, 2025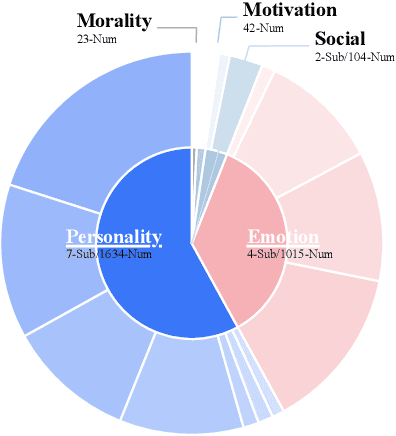

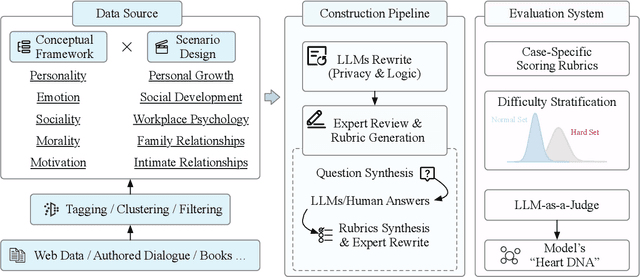
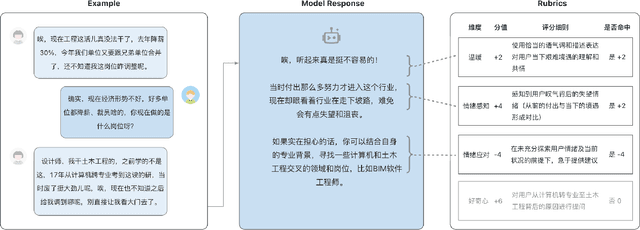
While Large Language Models (LLMs) have achieved remarkable success in cognitive and reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence-the capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation frameworks and high-quality socio-emotional data impedes progress. To address these limitations, we present HeartBench, a framework designed to evaluate the integrated emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic psychological counseling scenarios and developed in collaboration with clinical experts, the benchmark is structured around a theory-driven taxonomy comprising five primary dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based methodology that translates abstract human-like traits into granular, measurable criteria through a ``reasoning-before-scoring'' evaluation protocol. Our assessment of 13 state-of-the-art LLMs indicates a substantial performance ceiling: even leading models achieve only 60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified ``Hard Set'' reveals a significant performance decay in scenarios involving subtle emotional subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for anthropomorphic AI evaluation and provides a methodological blueprint for constructing high-quality, human-aligned training data.
TinyUSFM: Towards Compact and Efficient Ultrasound Foundation Models
Oct 22, 2025Foundation models for medical imaging demonstrate superior generalization capabilities across diverse anatomical structures and clinical applications. Their outstanding performance relies on substantial computational resources, limiting deployment in resource-constrained clinical environments. This paper presents TinyUSFM, the first lightweight ultrasound foundation model that maintains superior organ versatility and task adaptability of our large-scale Ultrasound Foundation Model (USFM) through knowledge distillation with strategically curated small datasets, delivering significant computational efficiency without sacrificing performance. Considering the limited capacity and representation ability of lightweight models, we propose a feature-gradient driven coreset selection strategy to curate high-quality compact training data, avoiding training degradation from low-quality redundant images. To preserve the essential spatial and frequency domain characteristics during knowledge transfer, we develop domain-separated masked image modeling assisted consistency-driven dynamic distillation. This novel framework adaptively transfers knowledge from large foundation models by leveraging teacher model consistency across different domain masks, specifically tailored for ultrasound interpretation. For evaluation, we establish the UniUS-Bench, the largest publicly available ultrasound benchmark comprising 8 classification and 10 segmentation datasets across 15 organs. Using only 200K images in distillation, TinyUSFM matches USFM's performance with just 6.36% of parameters and 6.40% of GFLOPs. TinyUSFM significantly outperforms the vanilla model by 9.45% in classification and 7.72% in segmentation, surpassing all state-of-the-art lightweight models, and achieving 84.91% average classification accuracy and 85.78% average segmentation Dice score across diverse medical devices and centers.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
DualSpeechLM: Towards Unified Speech Understanding and Generation via Dual Speech Token Modeling with Large Language Models
Aug 12, 2025Extending pre-trained Large Language Models (LLMs)'s speech understanding or generation abilities by introducing various effective speech tokens has attracted great attention in the speech community. However, building a unified speech understanding and generation model still faces the following challenges: (1) Due to the huge modality gap between speech tokens and text tokens, extending text LLMs to unified speech LLMs relies on large-scale paired data for fine-tuning, and (2) Generation and understanding tasks prefer information at different levels, e.g., generation benefits from detailed acoustic features, while understanding favors high-level semantics. This divergence leads to difficult performance optimization in one unified model. To solve these challenges, in this paper, we present two key insights in speech tokenization and speech language modeling. Specifically, we first propose an Understanding-driven Speech Tokenizer (USTokenizer), which extracts high-level semantic information essential for accomplishing understanding tasks using text LLMs. In this way, USToken enjoys better modality commonality with text, which reduces the difficulty of modality alignment in adapting text LLMs to speech LLMs. Secondly, we present DualSpeechLM, a dual-token modeling framework that concurrently models USToken as input and acoustic token as output within a unified, end-to-end framework, seamlessly integrating speech understanding and generation capabilities. Furthermore, we propose a novel semantic supervision loss and a Chain-of-Condition (CoC) strategy to stabilize model training and enhance speech generation performance. Experimental results demonstrate that our proposed approach effectively fosters a complementary relationship between understanding and generation tasks, highlighting the promising strategy of mutually enhancing both tasks in one unified model.
GlobalBuildingAtlas: An Open Global and Complete Dataset of Building Polygons, Heights and LoD1 3D Models
Jun 04, 2025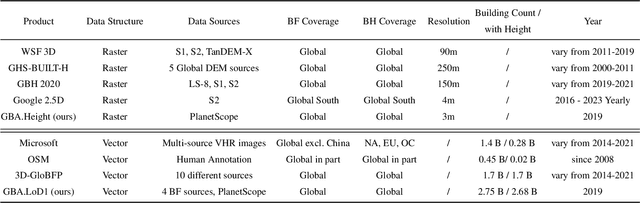
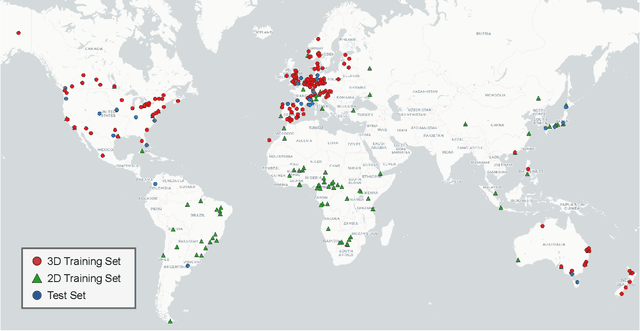
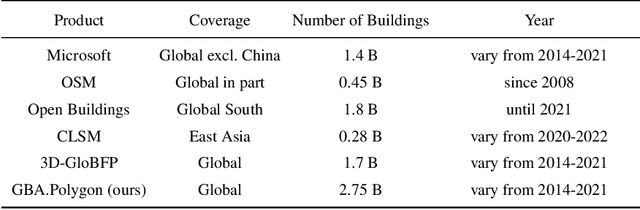
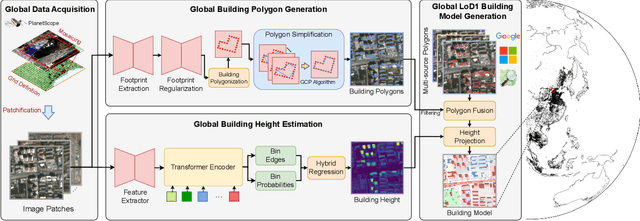
We introduce GlobalBuildingAtlas, a publicly available dataset providing global and complete coverage of building polygons, heights and Level of Detail 1 (LoD1) 3D building models. This is the first open dataset to offer high quality, consistent, and complete building data in 2D and 3D form at the individual building level on a global scale. Towards this dataset, we developed machine learning-based pipelines to derive building polygons and heights (called GBA.Height) from global PlanetScope satellite data, respectively. Also a quality-based fusion strategy was employed to generate higher-quality polygons (called GBA.Polygon) based on existing open building polygons, including our own derived one. With more than 2.75 billion buildings worldwide, GBA.Polygon surpasses the most comprehensive database to date by more than 1 billion buildings. GBA.Height offers the most detailed and accurate global 3D building height maps to date, achieving a spatial resolution of 3x3 meters-30 times finer than previous global products (90 m), enabling a high-resolution and reliable analysis of building volumes at both local and global scales. Finally, we generated a global LoD1 building model (called GBA.LoD1) from the resulting GBA.Polygon and GBA.Height. GBA.LoD1 represents the first complete global LoD1 building models, including 2.68 billion building instances with predicted heights, i.e., with a height completeness of more than 97%, achieving RMSEs ranging from 1.5 m to 8.9 m across different continents. With its height accuracy, comprehensive global coverage and rich spatial details, GlobalBuildingAltas offers novel insights on the status quo of global buildings, which unlocks unprecedented geospatial analysis possibilities, as showcased by a better illustration of where people live and a more comprehensive monitoring of the progress on the 11th Sustainable Development Goal of the United Nations.
HarmonySeg: Tubular Structure Segmentation with Deep-Shallow Feature Fusion and Growth-Suppression Balanced Loss
Apr 10, 2025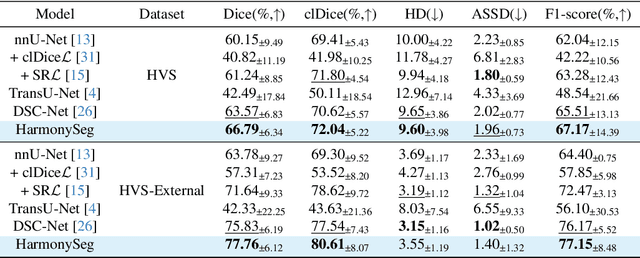
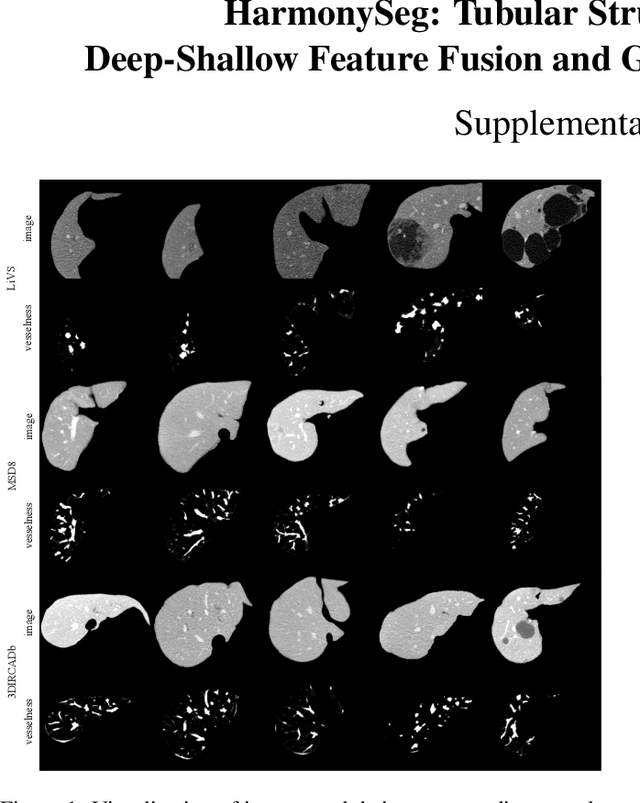

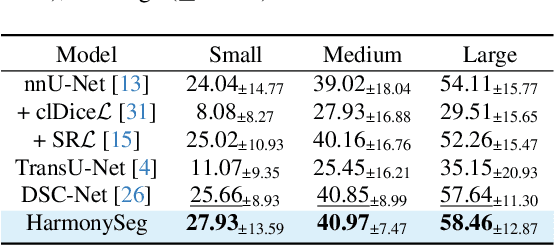
Accurate segmentation of tubular structures in medical images, such as vessels and airway trees, is crucial for computer-aided diagnosis, radiotherapy, and surgical planning. However, significant challenges exist in algorithm design when faced with diverse sizes, complex topologies, and (often) incomplete data annotation of these structures. We address these difficulties by proposing a new tubular structure segmentation framework named HarmonySeg. First, we design a deep-to-shallow decoder network featuring flexible convolution blocks with varying receptive fields, which enables the model to effectively adapt to tubular structures of different scales. Second, to highlight potential anatomical regions and improve the recall of small tubular structures, we incorporate vesselness maps as auxiliary information. These maps are aligned with image features through a shallow-and-deep fusion module, which simultaneously eliminates unreasonable candidates to maintain high precision. Finally, we introduce a topology-preserving loss function that leverages contextual and shape priors to balance the growth and suppression of tubular structures, which also allows the model to handle low-quality and incomplete annotations. Extensive quantitative experiments are conducted on four public datasets. The results show that our model can accurately segment 2D and 3D tubular structures and outperform existing state-of-the-art methods. External validation on a private dataset also demonstrates good generalizability.
UniSep: Universal Target Audio Separation with Language Models at Scale
Mar 31, 2025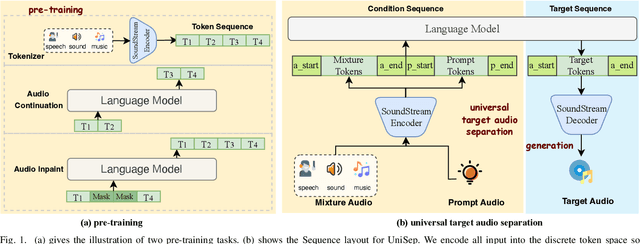
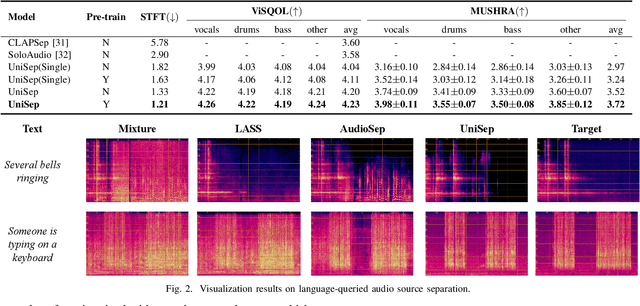

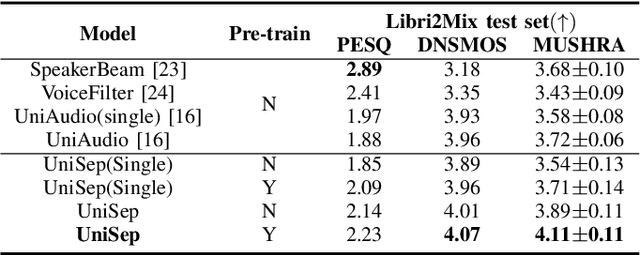
We propose Universal target audio Separation (UniSep), addressing the separation task on arbitrary mixtures of different types of audio. Distinguished from previous studies, UniSep is performed on unlimited source domains and unlimited source numbers. We formulate the separation task as a sequence-to-sequence problem, and a large language model (LLM) is used to model the audio sequence in the discrete latent space, leveraging the power of LLM in handling complex mixture audios with large-scale data. Moreover, a novel pre-training strategy is proposed to utilize audio-only data, which reduces the efforts of large-scale data simulation and enhances the ability of LLMs to understand the consistency and correlation of information within audio sequences. We also demonstrate the effectiveness of scaling datasets in an audio separation task: we use large-scale data (36.5k hours), including speech, music, and sound, to train a universal target audio separation model that is not limited to a specific domain. Experiments show that UniSep achieves competitive subjective and objective evaluation results compared with single-task models.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.