 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSep: Universal Target Audio Separation with Language Models at Scale
Mar 31, 2025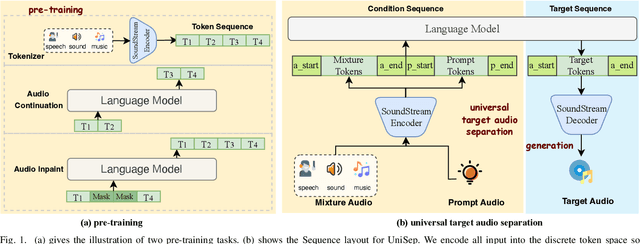
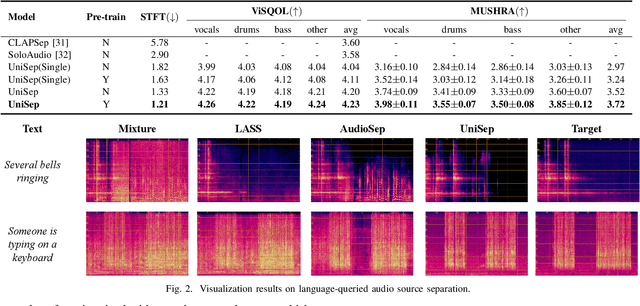

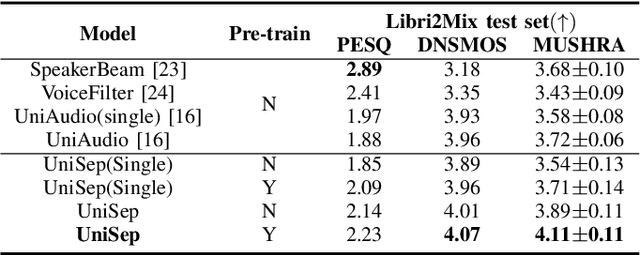
We propose Universal target audio Separation (UniSep), addressing the separation task on arbitrary mixtures of different types of audio. Distinguished from previous studies, UniSep is performed on unlimited source domains and unlimited source numbers. We formulate the separation task as a sequence-to-sequence problem, and a large language model (LLM) is used to model the audio sequence in the discrete latent space, leveraging the power of LLM in handling complex mixture audios with large-scale data. Moreover, a novel pre-training strategy is proposed to utilize audio-only data, which reduces the efforts of large-scale data simulation and enhances the ability of LLMs to understand the consistency and correlation of information within audio sequences. We also demonstrate the effectiveness of scaling datasets in an audio separation task: we use large-scale data (36.5k hours), including speech, music, and sound, to train a universal target audio separation model that is not limited to a specific domain. Experiments show that UniSep achieves competitive subjective and objective evaluation results compared with single-task models.
DrawSpeech: Expressive Speech Synthesis Using Prosodic Sketches as Control Conditions
Jan 08, 2025



Controlling text-to-speech (TTS) systems to synthesize speech with the prosodic characteristics expected by users has attracted much attention. To achieve controllability, current studies focus on two main directions: (1) using reference speech as prosody prompt to guide speech synthesis, and (2) using natural language descriptions to control the generation process. However, finding reference speech that exactly contains the prosody that users want to synthesize takes a lot of effort. Description-based guidance in TTS systems can only determine the overall prosody, which has difficulty in achieving fine-grained prosody control over the synthesized speech. In this paper, we propose DrawSpeech, a sketch-conditioned diffusion model capable of generating speech based on any prosody sketches drawn by users. Specifically, the prosody sketches are fed to DrawSpeech to provide a rough indication of the expected prosody trends. DrawSpeech then recovers the detailed pitch and energy contours based on the coarse sketches and synthesizes the desired speech. Experimental results show that DrawSpeech can generate speech with a wide variety of prosody and can precisely control the fine-grained prosody in a user-friendly manner. Our implementation and audio samples are publicly available.
SECap: Speech Emotion Captioning with Large Language Model
Dec 23, 2023



Speech emotions are crucial in human communication and are extensively used in fields like speech synthesis and natural language understanding. Most prior studies, such as speech emotion recognition, have categorized speech emotions into a fixed set of classes. Yet, emotions expressed in human speech are often complex, and categorizing them into predefined groups can be insufficient to adequately represent speech emotions. On the contrary, describing speech emotions directly by means of natural language may be a more effective approach. Regrettably, there are not many studies available that have focused on this direction. Therefore, this paper proposes a speech emotion captioning framework named SECap, aiming at effectively describing speech emotions using natural language. Owing to the impressive capabilities of large language models in language comprehension and text generation, SECap employs LLaMA as the text decoder to allow the production of coherent speech emotion captions. In addition, SECap leverages HuBERT as the audio encoder to extract general speech features and Q-Former as the Bridge-Net to provide LLaMA with emotion-related speech features. To accomplish this, Q-Former utilizes mutual information learning to disentangle emotion-related speech features and speech contents, while implementing contrastive learning to extract more emotion-related speech features. The results of objective and subjective evaluations demonstrate that: 1) the SECap framework outperforms the HTSAT-BART baseline in all objective evaluations; 2) SECap can generate high-quality speech emotion captions that attain performance on par with human annotators in subjective mean opinion score tests.
Automatic Prosody Annotation with Pre-Trained Text-Speech Model
Jun 16, 2022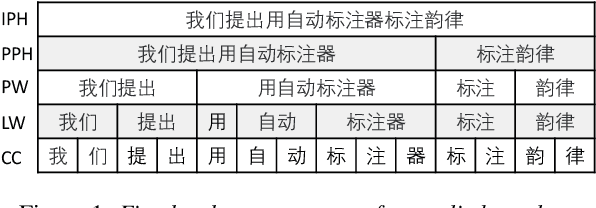
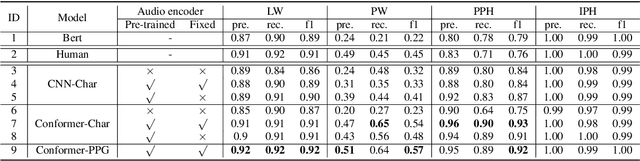
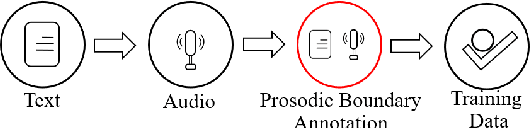

Prosodic boundary plays an important role in text-to-speech synthesis (TTS) in terms of naturalness and readability. However, the acquisition of prosodic boundary labels relies on manual annotation, which is costly and time-consuming. In this paper, we propose to automatically extract prosodic boundary labels from text-audio data via a neural text-speech model with pre-trained audio encoders. This model is pre-trained on text and speech data separately and jointly fine-tuned on TTS data in a triplet format: {speech, text, prosody}. The experimental results on both automatic evaluation and human evaluation demonstrate that: 1) the proposed text-speech prosody annotation framework significantly outperforms text-only baselines; 2) the quality of automatic prosodic boundary annotations is comparable to human annotations; 3) TTS systems trained with model-annotated boundaries are slightly better than systems that use manual ones.
Controllable Context-aware Conversational Speech Synthesis
Jun 21, 2021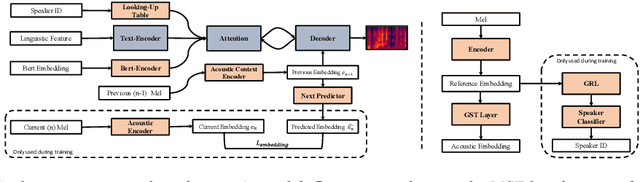
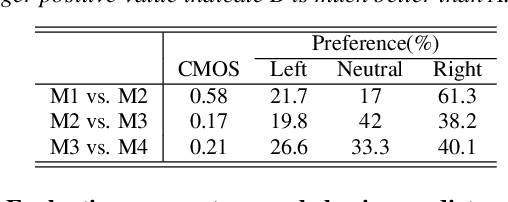

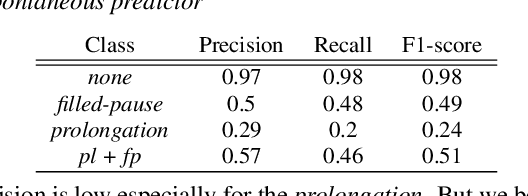
In spoken conversations, spontaneous behaviors like filled pause and prolongations always happen. Conversational partner tends to align features of their speech with their interlocutor which is known as entrainment. To produce human-like conversations, we propose a unified controllable spontaneous conversational speech synthesis framework to model the above two phenomena. Specifically, we use explicit labels to represent two typical spontaneous behaviors filled-pause and prolongation in the acoustic model and develop a neural network based predictor to predict the occurrences of the two behaviors from text. We subsequently develop an algorithm based on the predictor to control the occurrence frequency of the behaviors, making the synthesized speech vary from less disfluent to more disfluent. To model the speech entrainment at acoustic level, we utilize a context acoustic encoder to extract a global style embedding from the previous speech conditioning on the synthesizing of current speech. Furthermore, since the current and previous utterances belong to the different speakers in a conversation, we add a domain adversarial training module to eliminate the speaker-related information in the acoustic encoder while maintaining the style-related information. Experiments show that our proposed approach can synthesize realistic conversations and control the occurrences of the spontaneous behaviors naturally.
VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
Feb 12, 2021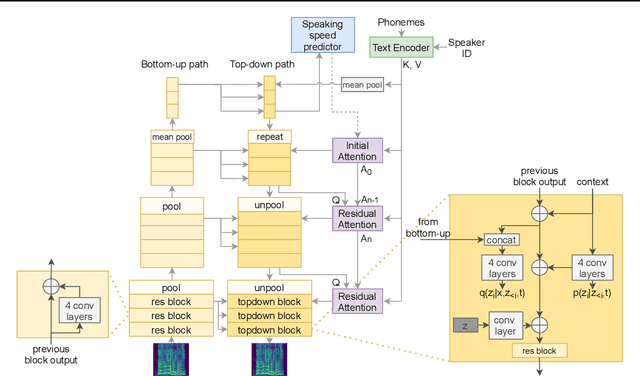
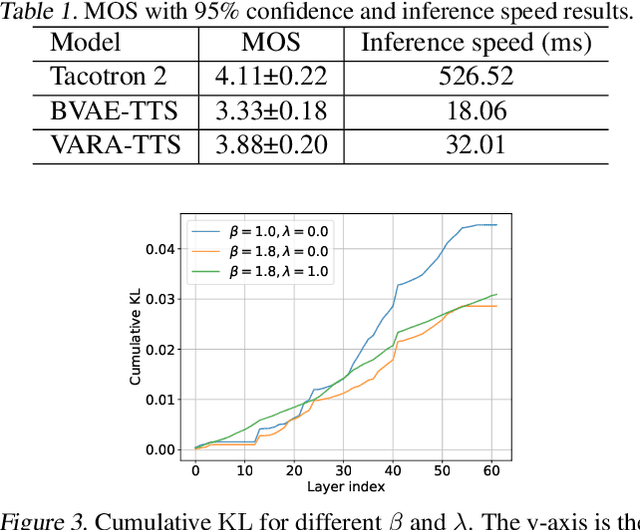

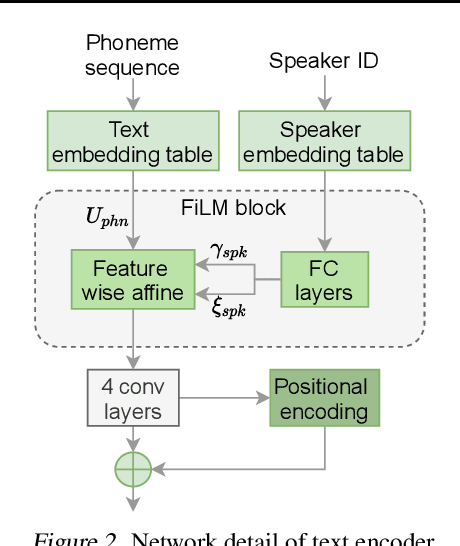
This paper proposes VARA-TTS, a non-autoregressive (non-AR) text-to-speech (TTS) model using a very deep Variational Autoencoder (VDVAE) with Residual Attention mechanism, which refines the textual-to-acoustic alignment layer-wisely. Hierarchical latent variables with different temporal resolutions from the VDVAE are used as queries for residual attention module. By leveraging the coarse global alignment from previous attention layer as an extra input, the following attention layer can produce a refined version of alignment. This amortizes the burden of learning the textual-to-acoustic alignment among multiple attention layers and outperforms the use of only a single attention layer in robustness. An utterance-level speaking speed factor is computed by a jointly-trained speaking speed predictor, which takes the mean-pooled latent variables of the coarsest layer as input, to determine number of acoustic frames at inference. Experimental results show that VARA-TTS achieves slightly inferior speech quality to an AR counterpart Tacotron 2 but an order-of-magnitude speed-up at inference; and outperforms an analogous non-AR model, BVAE-TTS, in terms of speech quality.
Maximizing Mutual Information for Tacotron
Aug 30, 2019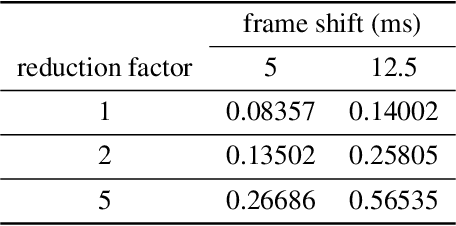
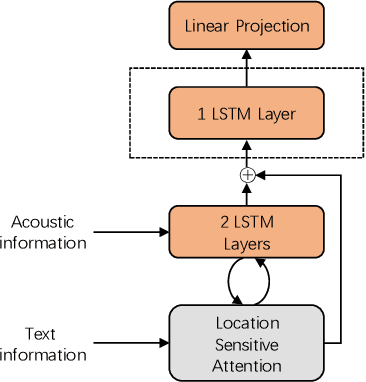
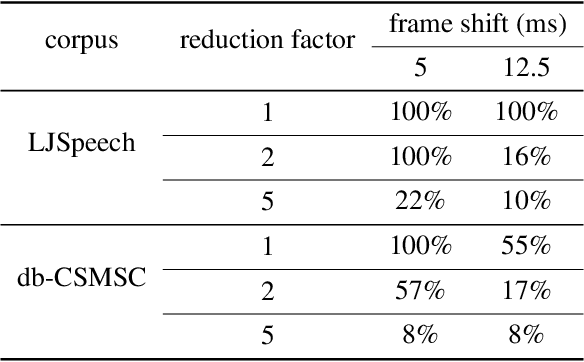
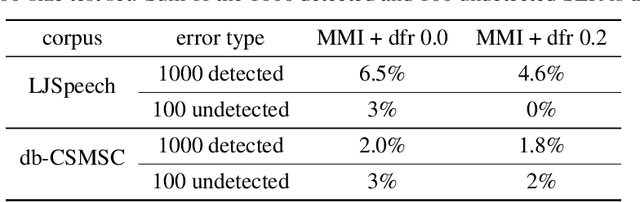
End-to-end speech synthesis method such as Tacotron, Tacotron2 and Transformer-TTS already achieves close to human quality performance. However compared to HMM-based method or NN-based frame-to-frame regression method, it is prone to some bad cases, such as missing words, repeating words and incomplete synthesis. More seriously, we cannot know whether such errors exist in a synthesized waveform or not unless we listen to it. We attribute the comparatively high sentence error rate to the local information preference of conditional autoregressive models. Inspired by the success of InfoGAN in learning interpretable representation by a mutual information regularization, in this paper, we propose to maximize the mutual information between the predicted acoustic features and the input text for end-to-end speech synthesis methods to address the local information preference problem and avoid such bad cases. What is more, we provide an indicator to detect errors in the predicted acoustic features as a byproduct. Experiment results show that our method can reduce the rate of bad cases and provide a reliable indicator to detect bad cases automatically.