 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Noise-independent Speech Representation for High-quality Voice Conversion for Noisy Target Speakers
Jul 02, 2022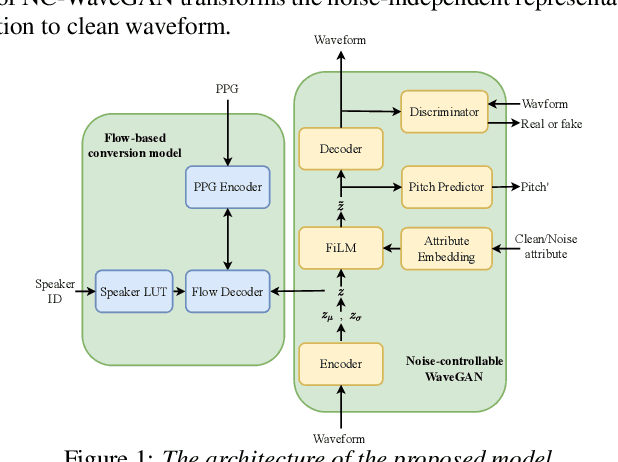



Building a voice conversion system for noisy target speakers, such as users providing noisy samples or Internet found data, is a challenging task since the use of contaminated speech in model training will apparently degrade the conversion performance. In this paper, we leverage the advances of our recently proposed Glow-WaveGAN and propose a noise-independent speech representation learning approach for high-quality voice conversion for noisy target speakers. Specifically, we learn a latent feature space where we ensure that the target distribution modeled by the conversion model is exactly from the modeled distribution of the waveform generator. With this premise, we further manage to make the latent feature to be noise-invariant. Specifically, we introduce a noise-controllable WaveGAN, which directly learns the noise-independent acoustic representation from waveform by the encoder and conducts noise control in the hidden space through a FiLM module in the decoder. As for the conversion model, importantly, we use a flow-based model to learn the distribution of noise-independent but speaker-related latent features from phoneme posteriorgrams. Experimental results demonstrate that the proposed model achieves high speech quality and speaker similarity in the voice conversion for noisy target speakers.
Controllable Context-aware Conversational Speech Synthesis
Jun 21, 2021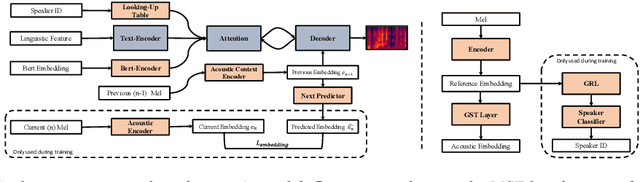
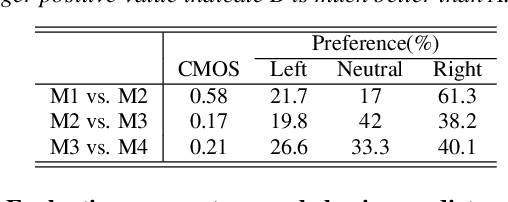

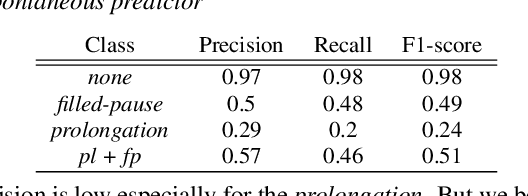
In spoken conversations, spontaneous behaviors like filled pause and prolongations always happen. Conversational partner tends to align features of their speech with their interlocutor which is known as entrainment. To produce human-like conversations, we propose a unified controllable spontaneous conversational speech synthesis framework to model the above two phenomena. Specifically, we use explicit labels to represent two typical spontaneous behaviors filled-pause and prolongation in the acoustic model and develop a neural network based predictor to predict the occurrences of the two behaviors from text. We subsequently develop an algorithm based on the predictor to control the occurrence frequency of the behaviors, making the synthesized speech vary from less disfluent to more disfluent. To model the speech entrainment at acoustic level, we utilize a context acoustic encoder to extract a global style embedding from the previous speech conditioning on the synthesizing of current speech. Furthermore, since the current and previous utterances belong to the different speakers in a conversation, we add a domain adversarial training module to eliminate the speaker-related information in the acoustic encoder while maintaining the style-related information. Experiments show that our proposed approach can synthesize realistic conversations and control the occurrences of the spontaneous behaviors naturally.
VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
Feb 12, 2021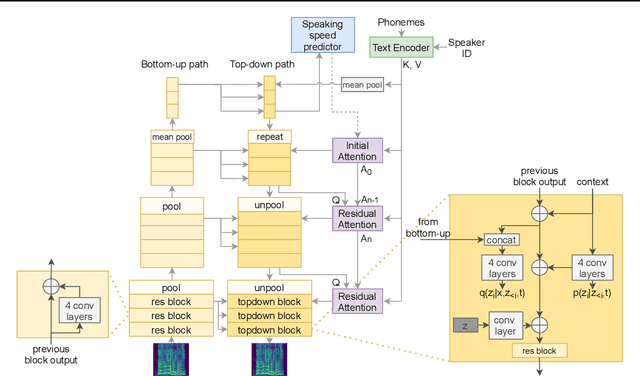
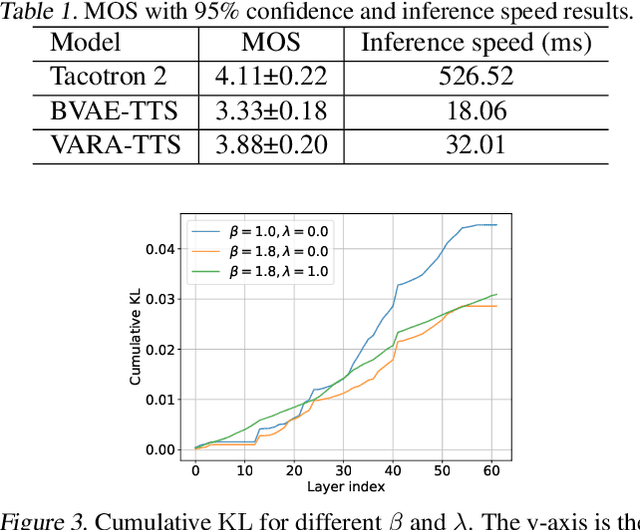

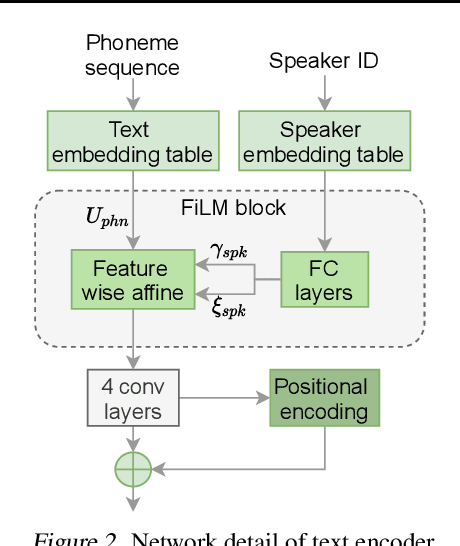
This paper proposes VARA-TTS, a non-autoregressive (non-AR) text-to-speech (TTS) model using a very deep Variational Autoencoder (VDVAE) with Residual Attention mechanism, which refines the textual-to-acoustic alignment layer-wisely. Hierarchical latent variables with different temporal resolutions from the VDVAE are used as queries for residual attention module. By leveraging the coarse global alignment from previous attention layer as an extra input, the following attention layer can produce a refined version of alignment. This amortizes the burden of learning the textual-to-acoustic alignment among multiple attention layers and outperforms the use of only a single attention layer in robustness. An utterance-level speaking speed factor is computed by a jointly-trained speaking speed predictor, which takes the mean-pooled latent variables of the coarsest layer as input, to determine number of acoustic frames at inference. Experimental results show that VARA-TTS achieves slightly inferior speech quality to an AR counterpart Tacotron 2 but an order-of-magnitude speed-up at inference; and outperforms an analogous non-AR model, BVAE-TTS, in terms of speech quality.
Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
Dec 03, 2020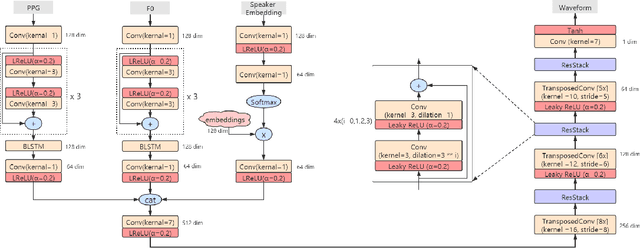

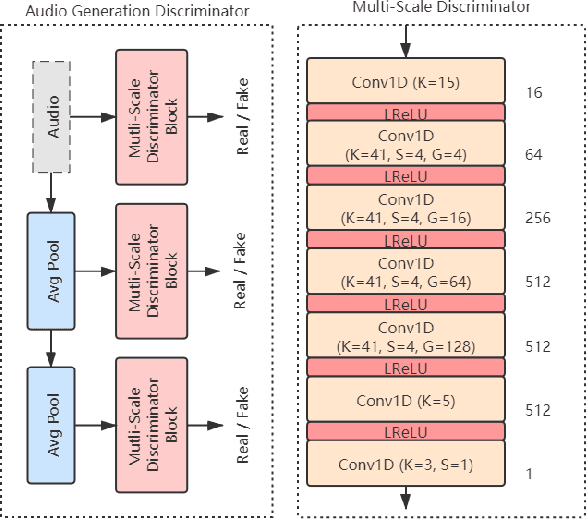

This paper describes an end-to-end adversarial singing voice conversion (EA-SVC) approach. It can directly generate arbitrary singing waveform by given phonetic posteriorgram (PPG) representing content, F0 representing pitch, and speaker embedding representing timbre, respectively. Proposed system is composed of three modules: generator $G$, the audio generation discriminator $D_{A}$, and the feature disentanglement discriminator $D_F$. The generator $G$ encodes the features in parallel and inversely transforms them into the target waveform. In order to make timbre conversion more stable and controllable, speaker embedding is further decomposed to the weighted sum of a group of trainable vectors representing different timbre clusters. Further, to realize more robust and accurate singing conversion, disentanglement discriminator $D_F$ is proposed to remove pitch and timbre related information that remains in the encoded PPG. Finally, a two-stage training is conducted to keep a stable and effective adversarial training process. Subjective evaluation results demonstrate the effectiveness of our proposed methods. Proposed system outperforms conventional cascade approach and the WaveNet based end-to-end approach in terms of both singing quality and singer similarity. Further objective analysis reveals that the model trained with the proposed two-stage training strategy can produce a smoother and sharper formant which leads to higher audio quality.
DurIAN: Duration Informed Attention Network For Multimodal Synthesis
Sep 05, 2019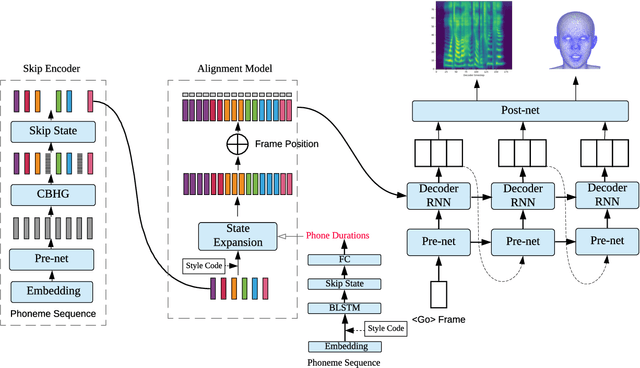
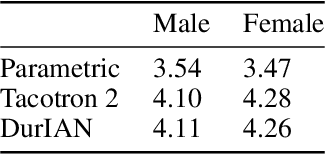
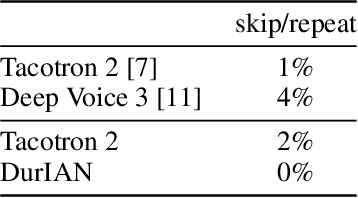
In this paper, we present a generic and robust multimodal synthesis system that produces highly natural speech and facial expression simultaneously. The key component of this system is the Duration Informed Attention Network (DurIAN), an autoregressive model in which the alignments between the input text and the output acoustic features are inferred from a duration model. This is different from the end-to-end attention mechanism used, and accounts for various unavoidable artifacts, in existing end-to-end speech synthesis systems such as Tacotron. Furthermore, DurIAN can be used to generate high quality facial expression which can be synchronized with generated speech with/without parallel speech and face data. To improve the efficiency of speech generation, we also propose a multi-band parallel generation strategy on top of the WaveRNN model. The proposed Multi-band WaveRNN effectively reduces the total computational complexity from 9.8 to 5.5 GFLOPS, and is able to generate audio that is 6 times faster than real time on a single CPU core. We show that DurIAN could generate highly natural speech that is on par with current state of the art end-to-end systems, while at the same time avoid word skipping/repeating errors in those systems. Finally, a simple yet effective approach for fine-grained control of expressiveness of speech and facial expression is introduced.