 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improving the Expressiveness of Singing Voice Synthesis with BERT Derived Semantic Information
Aug 31, 2023



This paper presents an end-to-end high-quality singing voice synthesis (SVS) system that uses bidirectional encoder representation from Transformers (BERT) derived semantic embeddings to improve the expressiveness of the synthesized singing voice. Based on the main architecture of recently proposed VISinger, we put forward several specific designs for expressive singing voice synthesis. First, different from the previous SVS models, we use text representation of lyrics extracted from pre-trained BERT as additional input to the model. The representation contains information about semantics of the lyrics, which could help SVS system produce more expressive and natural voice. Second, we further introduce an energy predictor to stabilize the synthesized voice and model the wider range of energy variations that also contribute to the expressiveness of singing voice. Last but not the least, to attenuate the off-key issues, the pitch predictor is re-designed to predict the real to note pitch ratio. Both objective and subjective experimental results indicate that the proposed SVS system can produce singing voice with higher-quality outperforming VISinger.
Improving Mandarin Prosodic Structure Prediction with Multi-level Contextual Information
Aug 31, 2023



For text-to-speech (TTS) synthesis, prosodic structure prediction (PSP) plays an important role in producing natural and intelligible speech. Although inter-utterance linguistic information can influence the speech interpretation of the target utterance, previous works on PSP mainly focus on utilizing intrautterance linguistic information of the current utterance only. This work proposes to use inter-utterance linguistic information to improve the performance of PSP. Multi-level contextual information, which includes both inter-utterance and intrautterance linguistic information, is extracted by a hierarchical encoder from character level, utterance level and discourse level of the input text. Then a multi-task learning (MTL) decoder predicts prosodic boundaries from multi-level contextual information. Objective evaluation results on two datasets show that our method achieves better F1 scores in predicting prosodic word (PW), prosodic phrase (PPH) and intonational phrase (IPH). It demonstrates the effectiveness of using multi-level contextual information for PSP. Subjective preference tests also indicate the naturalness of synthesized speeches are improved.
CoverHunter: Cover Song Identification with Refined Attention and Alignments
Jun 15, 2023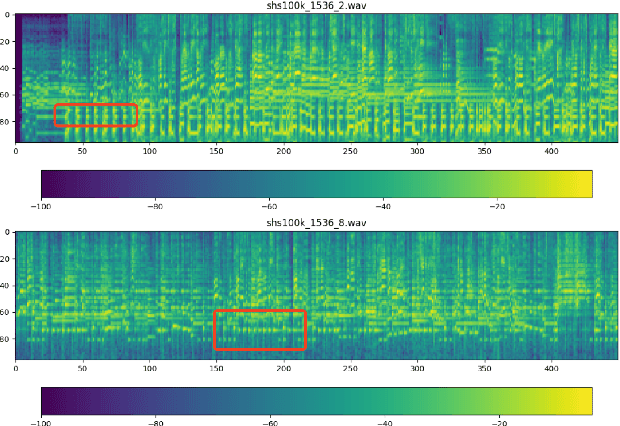
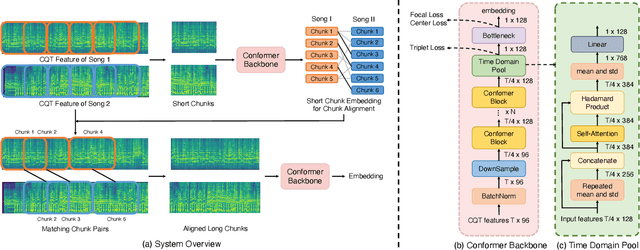
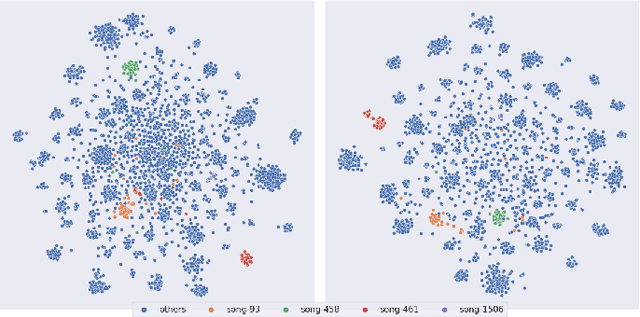
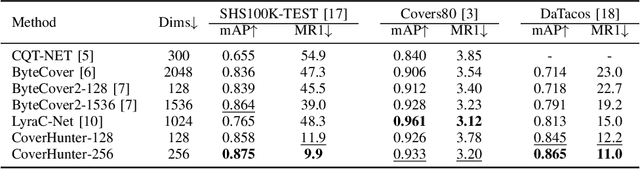
Abstract: Cover song identification (CSI) focuses on finding the same music with different versions in reference anchors given a query track. In this paper, we propose a novel system named CoverHunter that overcomes the shortcomings of existing detection schemes by exploring richer features with refined attention and alignments. CoverHunter contains three key modules: 1) A convolution-augmented transformer (i.e., Conformer) structure that captures both local and global feature interactions in contrast to previous methods mainly relying on convolutional neural networks; 2) An attention-based time pooling module that further exploits the attention in the time dimension; 3) A novel coarse-to-fine training scheme that first trains a network to roughly align the song chunks and then refines the network by training on the aligned chunks. At the same time, we also summarize some important training tricks used in our system that help achieve better results. Experiments on several standard CSI datasets show that our method significantly improves over state-of-the-art methods with an embedding size of 128 (2.3% on SHS100K-TEST and 17.7% on DaTacos).
FullSubNet+: Channel Attention FullSubNet with Complex Spectrograms for Speech Enhancement
Mar 26, 2022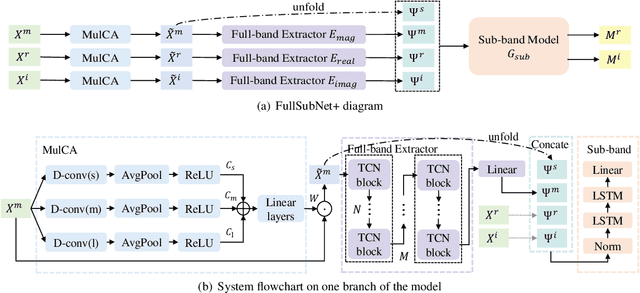
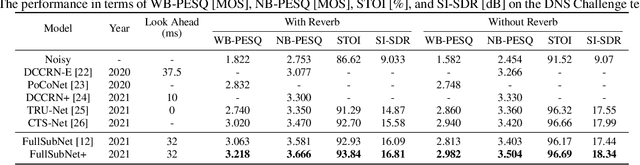
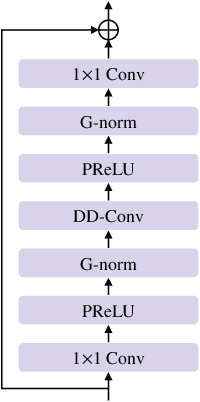

Previously proposed FullSubNet has achieved outstanding performance in Deep Noise Suppression (DNS) Challenge and attracted much attention. However, it still encounters issues such as input-output mismatch and coarse processing for frequency bands. In this paper, we propose an extended single-channel real-time speech enhancement framework called FullSubNet+ with following significant improvements. First, we design a lightweight multi-scale time sensitive channel attention (MulCA) module which adopts multi-scale convolution and channel attention mechanism to help the network focus on more discriminative frequency bands for noise reduction. Then, to make full use of the phase information in noisy speech, our model takes all the magnitude, real and imaginary spectrograms as inputs. Moreover, by replacing the long short-term memory (LSTM) layers in original full-band model with stacked temporal convolutional network (TCN) blocks, we design a more efficient full-band module called full-band extractor. The experimental results in DNS Challenge dataset show the superior performance of our FullSubNet+, which reaches the state-of-the-art (SOTA) performance and outperforms other existing speech enhancement approaches.
Disentangleing Content and Fine-grained Prosody Information via Hybrid ASR Bottleneck Features for Voice Conversion
Mar 24, 2022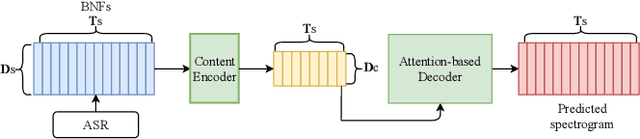


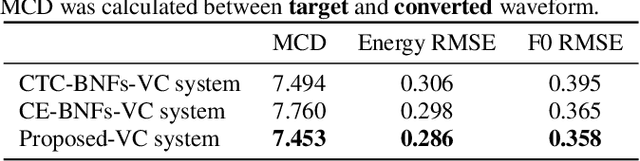
Non-parallel data voice conversion (VC) have achieved considerable breakthroughs recently through introducing bottleneck features (BNFs) extracted by the automatic speech recognition(ASR) model. However, selection of BNFs have a significant impact on VC result. For example, when extracting BNFs from ASR trained with Cross Entropy loss (CE-BNFs) and feeding into neural network to train a VC system, the timbre similarity of converted speech is significantly degraded. If BNFs are extracted from ASR trained using Connectionist Temporal Classification loss (CTC-BNFs), the naturalness of the converted speech may decrease. This phenomenon is caused by the difference of information contained in BNFs. In this paper, we proposed an any-to-one VC method using hybrid bottleneck features extracted from CTC-BNFs and CE-BNFs to complement each other advantages. Gradient reversal layer and instance normalization were used to extract prosody information from CE-BNFs and content information from CTC-BNFs. Auto-regressive decoder and Hifi-GAN vocoder were used to generate high-quality waveform. Experimental results show that our proposed method achieves higher similarity, naturalness, quality than baseline method and reveals the differences between the information contained in CE-BNFs and CTC-BNFs as well as the influence they have on the converted speech.
Speaker Independent and Multilingual/Mixlingual Speech-Driven Talking Head Generation Using Phonetic Posteriorgrams
Jun 20, 2020
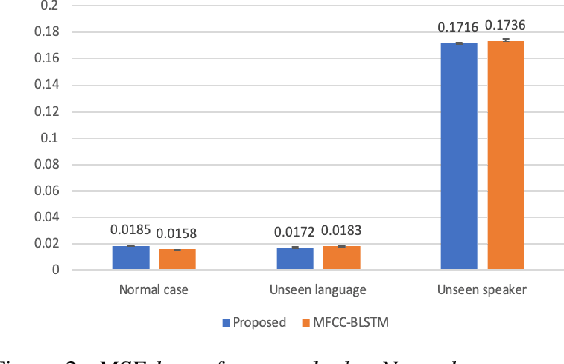
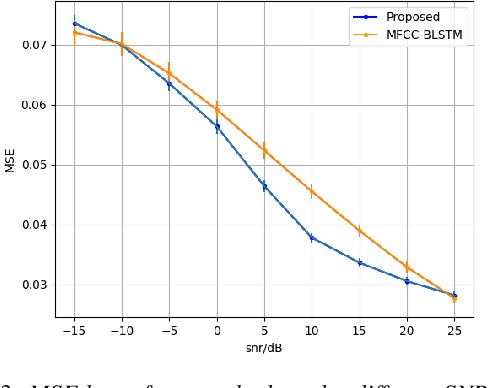
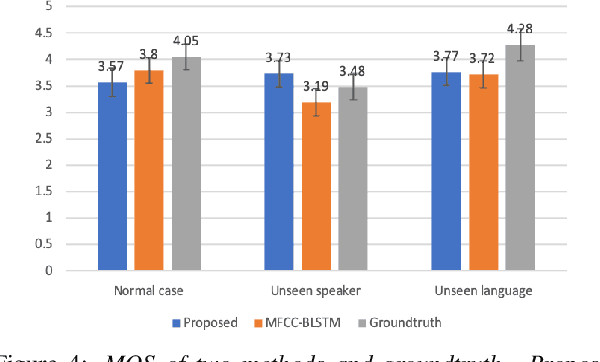
Generating 3D speech-driven talking head has received more and more attention in recent years. Recent approaches mainly have following limitations: 1) most speaker-independent methods need handcrafted features that are time-consuming to design or unreliable; 2) there is no convincing method to support multilingual or mixlingual speech as input. In this work, we propose a novel approach using phonetic posteriorgrams (PPG). In this way, our method doesn't need hand-crafted features and is more robust to noise compared to recent approaches. Furthermore, our method can support multilingual speech as input by building a universal phoneme space. As far as we know, our model is the first to support multilingual/mixlingual speech as input with convincing results. Objective and subjective experiments have shown that our model can generate high quality animations given speech from unseen languages or speakers and be robust to noise.
DurIAN: Duration Informed Attention Network For Multimodal Synthesis
Sep 05, 2019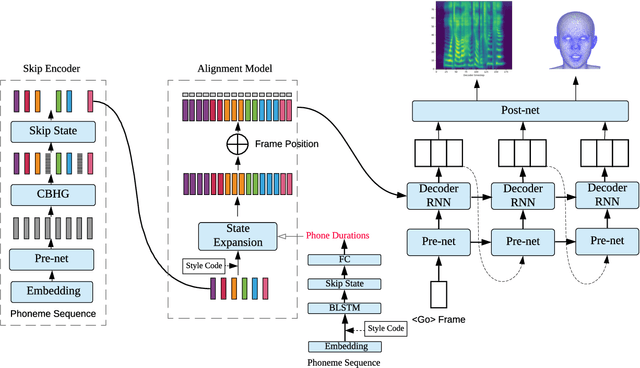
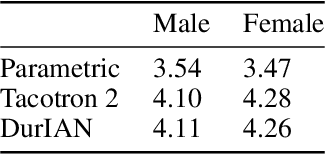
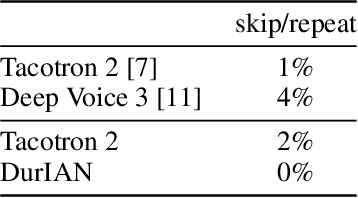
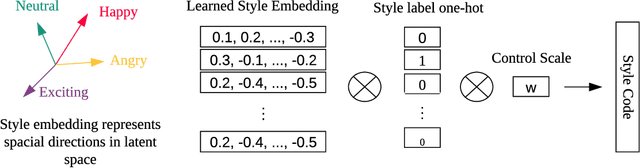
In this paper, we present a generic and robust multimodal synthesis system that produces highly natural speech and facial expression simultaneously. The key component of this system is the Duration Informed Attention Network (DurIAN), an autoregressive model in which the alignments between the input text and the output acoustic features are inferred from a duration model. This is different from the end-to-end attention mechanism used, and accounts for various unavoidable artifacts, in existing end-to-end speech synthesis systems such as Tacotron. Furthermore, DurIAN can be used to generate high quality facial expression which can be synchronized with generated speech with/without parallel speech and face data. To improve the efficiency of speech generation, we also propose a multi-band parallel generation strategy on top of the WaveRNN model. The proposed Multi-band WaveRNN effectively reduces the total computational complexity from 9.8 to 5.5 GFLOPS, and is able to generate audio that is 6 times faster than real time on a single CPU core. We show that DurIAN could generate highly natural speech that is on par with current state of the art end-to-end systems, while at the same time avoid word skipping/repeating errors in those systems. Finally, a simple yet effective approach for fine-grained control of expressiveness of speech and facial expression is introduced.