 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullSubNet+: Channel Attention FullSubNet with Complex Spectrograms for Speech Enhancement
Paper and Code
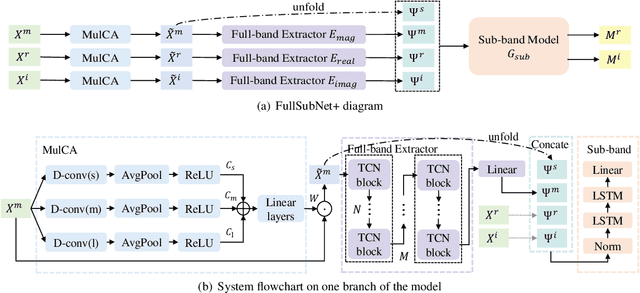
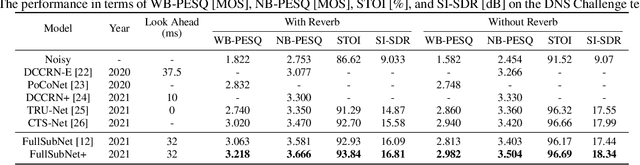
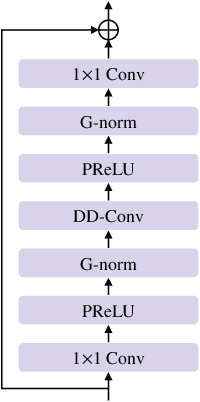

Previously proposed FullSubNet has achieved outstanding performance in Deep Noise Suppression (DNS) Challenge and attracted much attention. However, it still encounters issues such as input-output mismatch and coarse processing for frequency bands. In this paper, we propose an extended single-channel real-time speech enhancement framework called FullSubNet+ with following significant improvements. First, we design a lightweight multi-scale time sensitive channel attention (MulCA) module which adopts multi-scale convolution and channel attention mechanism to help the network focus on more discriminative frequency bands for noise reduction. Then, to make full use of the phase information in noisy speech, our model takes all the magnitude, real and imaginary spectrograms as inputs. Moreover, by replacing the long short-term memory (LSTM) layers in original full-band model with stacked temporal convolutional network (TCN) blocks, we design a more efficient full-band module called full-band extractor. The experimental results in DNS Challenge dataset show the superior performance of our FullSubNet+, which reaches the state-of-the-art (SOTA) performance and outperforms other existing speech enhancement approaches.