 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Forest and Trees in Images and Long Captions for Visually Grounded Understanding
Feb 03, 2026Large vision-language models such as CLIP struggle with long captions because they align images and texts as undifferentiated wholes. Fine-grained vision-language understanding requires hierarchical semantics capturing both global context and localized details across visual and textual domains. Yet linguistic hierarchies from syntax or semantics rarely match visual organization, and purely visual hierarchies tend to fragment scenes into appearance-driven parts without semantic focus. We propose CAFT (Cross-domain Alignment of Forests and Trees), a hierarchical image-text representation learning framework that aligns global and local semantics across images and long captions without pixel-level supervision. Coupling a fine-to-coarse visual encoder with a hierarchical text transformer, it uses a hierarchical alignment loss that matches whole images with whole captions while biasing region-sentence correspondences, so that coarse semantics are built from fine-grained evidence rather than from aggregation untethered to part-level grounding. Trained on 30M image-text pairs, CAFT achieves state-of-the-art performance on six long-text retrieval benchmarks and exhibits strong scaling behavior. Experiments show that hierarchical cross-domain alignment enables fine-grained, visually grounded image-text representations to emerge without explicit region-level supervision.
Open Ad-hoc Categorization with Contextualized Feature Learning
Dec 18, 2025Adaptive categorization of visual scenes is essential for AI agents to handle changing tasks. Unlike fixed common categories for plants or animals, ad-hoc categories are created dynamically to serve specific goals. We study open ad-hoc categorization: Given a few labeled exemplars and abundant unlabeled data, the goal is to discover the underlying context and to expand ad-hoc categories through semantic extension and visual clustering around it. Building on the insight that ad-hoc and common categories rely on similar perceptual mechanisms, we propose OAK, a simple model that introduces a small set of learnable context tokens at the input of a frozen CLIP and optimizes with both CLIP's image-text alignment objective and GCD's visual clustering objective. On Stanford and Clevr-4 datasets, OAK achieves state-of-the-art in accuracy and concept discovery across multiple categorizations, including 87.4% novel accuracy on Stanford Mood, surpassing CLIP and GCD by over 50%. Moreover, OAK produces interpretable saliency maps, focusing on hands for Action, faces for Mood, and backgrounds for Location, promoting transparency and trust while enabling adaptive and generalizable categorization.
* 26 pages, 17 figures
HyperVLA: Efficient Inference in Vision-Language-Action Models via Hypernetworks
Oct 06, 2025Built upon language and vision foundation models with strong generalization ability and trained on large-scale robotic data, Vision-Language-Action (VLA) models have recently emerged as a promising approach to learning generalist robotic policies. However, a key drawback of existing VLAs is their extremely high inference costs. In this paper, we propose HyperVLA to address this problem. Unlike existing monolithic VLAs that activate the whole model during both training and inference, HyperVLA uses a novel hypernetwork (HN)-based architecture that activates only a small task-specific policy during inference, while still retaining the high model capacity needed to accommodate diverse multi-task behaviors during training. Successfully training an HN-based VLA is nontrivial so HyperVLA contains several key algorithm design features that improve its performance, including properly utilizing the prior knowledge from existing vision foundation models, HN normalization, and an action generation strategy. Compared to monolithic VLAs, HyperVLA achieves a similar or even higher success rate for both zero-shot generalization and few-shot adaptation, while significantly reducing inference costs. Compared to OpenVLA, a state-of-the-art VLA model, HyperVLA reduces the number of activated parameters at test time by $90\times$, and accelerates inference speed by $120\times$. Code is publicly available at https://github.com/MasterXiong/HyperVLA
How Should We Meta-Learn Reinforcement Learning Algorithms?
Jul 23, 2025The process of meta-learning algorithms from data, instead of relying on manual design, is growing in popularity as a paradigm for improving the performance of machine learning systems. Meta-learning shows particular promise for reinforcement learning (RL), where algorithms are often adapted from supervised or unsupervised learning despite their suboptimality for RL. However, until now there has been a severe lack of comparison between different meta-learning algorithms, such as using evolution to optimise over black-box functions or LLMs to propose code. In this paper, we carry out this empirical comparison of the different approaches when applied to a range of meta-learned algorithms which target different parts of the RL pipeline. In addition to meta-train and meta-test performance, we also investigate factors including the interpretability, sample cost and train time for each meta-learning algorithm. Based on these findings, we propose several guidelines for meta-learning new RL algorithms which will help ensure that future learned algorithms are as performant as possible.
Dialogue Director: Bridging the Gap in Dialogue Visualization for Multimodal Storytelling
Dec 30, 2024



Recent advances in AI-driven storytelling have enhanced video generation and story visualization. However, translating dialogue-centric scripts into coherent storyboards remains a significant challenge due to limited script detail, inadequate physical context understanding, and the complexity of integrating cinematic principles. To address these challenges, we propose Dialogue Visualization, a novel task that transforms dialogue scripts into dynamic, multi-view storyboards. We introduce Dialogue Director, a training-free multimodal framework comprising a Script Director, Cinematographer, and Storyboard Maker. This framework leverages large multimodal models and diffusion-based architectures, employing techniques such as Chain-of-Thought reasoning, Retrieval-Augmented Generation, and multi-view synthesis to improve script understanding, physical context comprehension, and cinematic knowledge integration. Experimental results demonstrate that Dialogue Director outperforms state-of-the-art methods in script interpretation, physical world understanding, and cinematic principle application, significantly advancing the quality and controllability of dialogue-based story visualization.
A No-Reference Medical Image Quality Assessment Method Based on Automated Distortion Recognition Technology: Application to Preprocessing in MRI-guided Radiotherapy
Dec 10, 2024



Objective:To develop a no-reference image quality assessment method using automated distortion recognition to boost MRI-guided radiotherapy precision.Methods:We analyzed 106,000 MR images from 10 patients with liver metastasis,captured with the Elekta Unity MR-LINAC.Our No-Reference Quality Assessment Model includes:1)image preprocessing to enhance visibility of key diagnostic features;2)feature extraction and directional analysis using MSCN coefficients across four directions to capture textural attributes and gradients,vital for identifying image features and potential distortions;3)integrative Quality Index(QI)calculation,which integrates features via AGGD parameter estimation and K-means clustering.The QI,based on a weighted MAD computation of directional scores,provides a comprehensive image quality measure,robust against outliers.LOO-CV assessed model generalizability and performance.Tumor tracking algorithm performance was compared with and without preprocessing to verify tracking accuracy enhancements.Results:Preprocessing significantly improved image quality,with the QI showing substantial positive changes and surpassing other metrics.After normalization,the QI's average value was 79.6 times higher than CNR,indicating improved image definition and contrast.It also showed higher sensitivity in detail recognition with average values 6.5 times and 1.7 times higher than Tenengrad gradient and entropy.The tumor tracking algorithm confirmed significant tracking accuracy improvements with preprocessed images,validating preprocessing effectiveness.Conclusions:This study introduces a novel no-reference image quality evaluation method based on automated distortion recognition,offering a new quality control tool for MRIgRT tumor tracking.It enhances clinical application accuracy and facilitates medical image quality assessment standardization, with significant clinical and research value.
A Novel Automatic Real-time Motion Tracking Method for Magnetic Resonance Imaging-guided Radiotherapy: Leveraging the Enhanced Tracking-Learning-Detection Framework with Automatic Segmentation
Nov 12, 2024



Objective: Ensuring the precision in motion tracking for MRI-guided Radiotherapy (MRIgRT) is crucial for the delivery of effective treatments. This study refined the motion tracking accuracy in MRIgRT through the innovation of an automatic real-time tracking method, leveraging an enhanced Tracking-Learning-Detection (ETLD) framework coupled with automatic segmentation. Methods: We developed a novel MRIgRT motion tracking method by integrating two primary methods: the ETLD framework and an improved Chan-Vese model (ICV), named ETLD+ICV. The TLD framework was upgraded to suit real-time cine MRI, including advanced image preprocessing, no-reference image quality assessment, an enhanced median-flow tracker, and a refined detector with dynamic search region adjustments. Additionally, ICV was combined for precise coverage of the target volume, which refined the segmented region frame by frame using tracking results, with key parameters optimized. Tested on 3.5D MRI scans from 10 patients with liver metastases, our method ensures precise tracking and accurate segmentation vital for MRIgRT. Results: An evaluation of 106,000 frames across 77 treatment fractions revealed sub-millimeter tracking errors of less than 0.8mm, with over 99% precision and 98% recall for all subjects, underscoring the robustness and efficacy of the ETLD. Moreover, the ETLD+ICV yielded a dice global score of more than 82% for all subjects, demonstrating the proposed method's extensibility and precise target volume coverage. Conclusions: This study successfully developed an automatic real-time motion tracking method for MRIgRT that markedly surpasses current methods. The novel method not only delivers exceptional precision in tracking and segmentation but also demonstrates enhanced adaptability to clinical demands, positioning it as an indispensable asset in the quest to augment the efficacy of radiotherapy treatments.
Improving Generalization and Convergence by Enhancing Implicit Regularization
May 31, 2024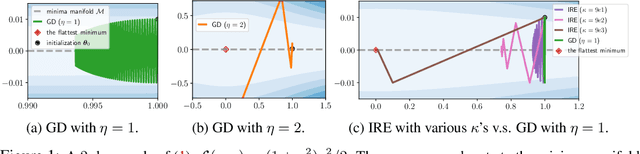
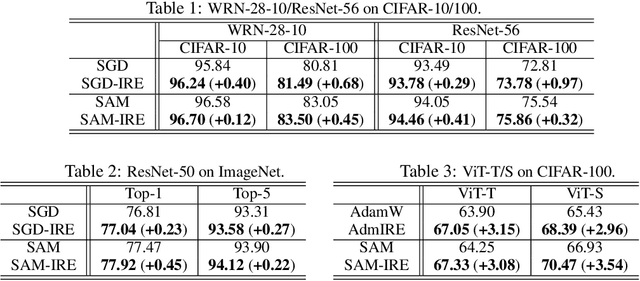
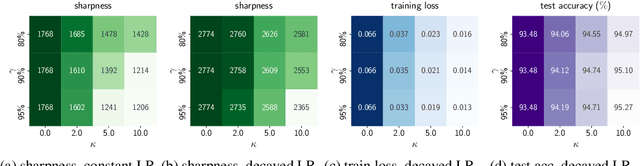
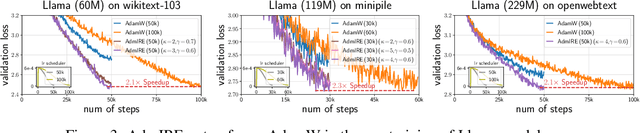
In this work, we propose an Implicit Regularization Enhancement (IRE) framework to accelerate the discovery of flat solutions in deep learning, thereby improving generalization and convergence. Specifically, IRE decouples the dynamics of flat and sharp directions, which boosts the sharpness reduction along flat directions while maintaining the training stability in sharp directions. We show that IRE can be practically incorporated with {\em generic base optimizers} without introducing significant computational overload. Experiments show that IRE consistently improves the generalization performance for image classification tasks across a variety of benchmark datasets (CIFAR-10/100, ImageNet) and models (ResNets and ViTs). Surprisingly, IRE also achieves a $2\times$ {\em speed-up} compared to AdamW in the pre-training of Llama models (of sizes ranging from 60M to 229M) on datasets including Wikitext-103, Minipile, and Openwebtext. Moreover, we provide theoretical guarantees, showing that IRE can substantially accelerate the convergence towards flat minima in Sharpness-aware Minimization (SAM).
Explore 3D Dance Generation via Reward Model from Automatically-Ranked Demonstrations
Dec 18, 2023This paper presents an Exploratory 3D Dance generation framework, E3D2, designed to address the exploration capability deficiency in existing music-conditioned 3D dance generation models. Current models often generate monotonous and simplistic dance sequences that misalign with human preferences because they lack exploration capabilities. The E3D2 framework involves a reward model trained from automatically-ranked dance demonstrations, which then guides the reinforcement learning process. This approach encourages the agent to explore and generate high quality and diverse dance movement sequences. The soundness of the reward model is both theoretically and experimentally validated. Empirical experiments demonstrate the effectiveness of E3D2 on the AIST++ dataset. Project Page: https://sites.google.com/view/e3d2.
Distance-rank Aware Sequential Reward Learning for Inverse Reinforcement Learning with Sub-optimal Demonstrations
Oct 13, 2023

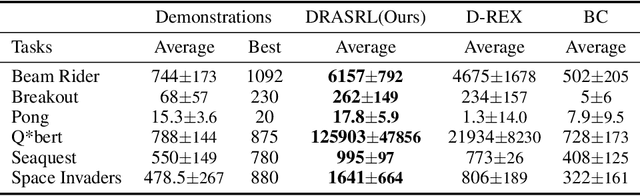

Inverse reinforcement learning (IRL) aims to explicitly infer an underlying reward function based on collected expert demonstrations. Considering that obtaining expert demonstrations can be costly, the focus of current IRL techniques is on learning a better-than-demonstrator policy using a reward function derived from sub-optimal demonstrations. However, existing IRL algorithms primarily tackle the challenge of trajectory ranking ambiguity when learning the reward function. They overlook the crucial role of considering the degree of difference between trajectories in terms of their returns, which is essential for further removing reward ambiguity. Additionally, it is important to note that the reward of a single transition is heavily influenced by the context information within the trajectory. To address these issues, we introduce the Distance-rank Aware Sequential Reward Learning (DRASRL) framework. Unlike existing approaches, DRASRL takes into account both the ranking of trajectories and the degrees of dissimilarity between them to collaboratively eliminate reward ambiguity when learning a sequence of contextually informed reward signals. Specifically, we leverage the distance between policies, from which the trajectories are generated, as a measure to quantify the degree of differences between traces. This distance-aware information is then used to infer embeddings in the representation space for reward learning, employing the contrastive learning technique. Meanwhile, we integrate the pairwise ranking loss function to incorporate ranking information into the latent features. Moreover, we resort to the Transformer architecture to capture the contextual dependencies within the trajectories in the latent space, leading to more accurate reward estimation. Through extensive experimentation, our DRASRL framework demonstrates significant performance improvements over previous SOTA methods.