 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-rank Aware Sequential Reward Learning for Inverse Reinforcement Learning with Sub-optimal Demonstrations
Paper and Code
Oct 13, 2023

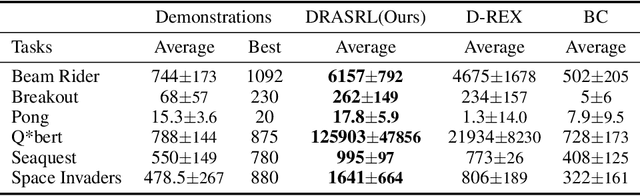

Inverse reinforcement learning (IRL) aims to explicitly infer an underlying reward function based on collected expert demonstrations. Considering that obtaining expert demonstrations can be costly, the focus of current IRL techniques is on learning a better-than-demonstrator policy using a reward function derived from sub-optimal demonstrations. However, existing IRL algorithms primarily tackle the challenge of trajectory ranking ambiguity when learning the reward function. They overlook the crucial role of considering the degree of difference between trajectories in terms of their returns, which is essential for further removing reward ambiguity. Additionally, it is important to note that the reward of a single transition is heavily influenced by the context information within the trajectory. To address these issues, we introduce the Distance-rank Aware Sequential Reward Learning (DRASRL) framework. Unlike existing approaches, DRASRL takes into account both the ranking of trajectories and the degrees of dissimilarity between them to collaboratively eliminate reward ambiguity when learning a sequence of contextually informed reward signals. Specifically, we leverage the distance between policies, from which the trajectories are generated, as a measure to quantify the degree of differences between traces. This distance-aware information is then used to infer embeddings in the representation space for reward learning, employing the contrastive learning technique. Meanwhile, we integrate the pairwise ranking loss function to incorporate ranking information into the latent features. Moreover, we resort to the Transformer architecture to capture the contextual dependencies within the trajectories in the latent space, leading to more accurate reward estimation. Through extensive experimentation, our DRASRL framework demonstrates significant performance improvements over previous SOTA methods.