 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pontryagin Method of Model-based Reinforcement Learning via Hamiltonian Actor-Critic
Mar 30, 2026Model-based reinforcement learning (MBRL) improves sample efficiency by leveraging learned dynamics models for policy optimization. However, the effectiveness of methods such as actor-critic is often limited by compounding model errors, which degrade long-horizon value estimation. Existing approaches, such as Model-Based Value Expansion (MVE), partially mitigate this issue through multi-step rollouts, but remain sensitive to rollout horizon selection and residual model bias. Motivated by the Pontryagin Maximum Principle (PMP), we propose Hamiltonian Actor-Critic (HAC), a model-based approach that eliminates explicit value function learning by directly optimizing a Hamiltonian defined over the learned dynamics and reward for deterministic systems. By avoiding value approximation, HAC reduces sensitivity to model errors while admitting convergence guarantees. Extensive experiments on continuous control benchmarks, in both online and offline RL settings, demonstrate that HAC outperforms model-free and MVE-based baselines in control performance, convergence speed, and robustness to distributional shift, including out-of-distribution (OOD) scenarios. In offline settings with limited data, HAC matches or exceeds state-of-the-art methods, highlighting its strong sample efficiency.
STO-RL: Offline RL under Sparse Rewards via LLM-Guided Subgoal Temporal Order
Jan 13, 2026Offline reinforcement learning (RL) enables policy learning from pre-collected datasets, avoiding costly and risky online interactions, but it often struggles with long-horizon tasks involving sparse rewards. Existing goal-conditioned and hierarchical offline RL methods decompose such tasks and generate intermediate rewards to mitigate limitations of traditional offline RL, but usually overlook temporal dependencies among subgoals and rely on imprecise reward shaping, leading to suboptimal policies. To address these issues, we propose STO-RL (Offline RL using LLM-Guided Subgoal Temporal Order), an offline RL framework that leverages large language models (LLMs) to generate temporally ordered subgoal sequences and corresponding state-to-subgoal-stage mappings. Using this temporal structure, STO-RL applies potential-based reward shaping to transform sparse terminal rewards into dense, temporally consistent signals, promoting subgoal progress while avoiding suboptimal solutions. The resulting augmented dataset with shaped rewards enables efficient offline training of high-performing policies. Evaluations on four discrete and continuous sparse-reward benchmarks demonstrate that STO-RL consistently outperforms state-of-the-art offline goal-conditioned and hierarchical RL baselines, achieving faster convergence, higher success rates, and shorter trajectories. Ablation studies further confirm STO-RL's robustness to imperfect or noisy LLM-generated subgoal sequences, demonstrating that LLM-guided subgoal temporal structures combined with theoretically grounded reward shaping provide a practical and scalable solution for long-horizon offline RL.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025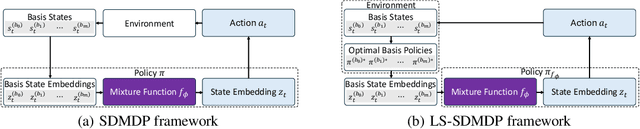
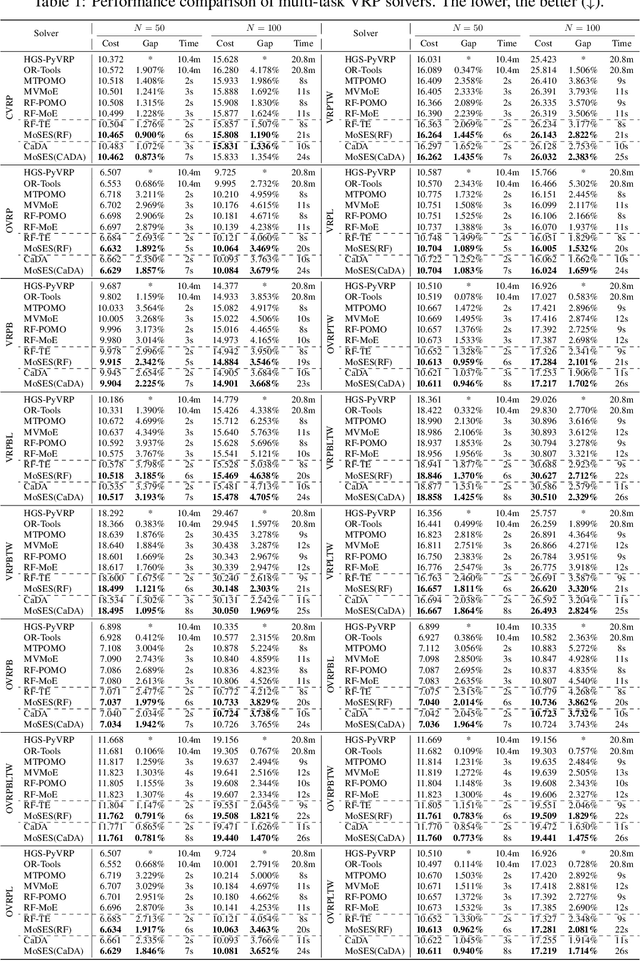
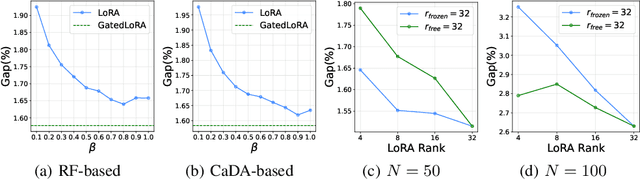
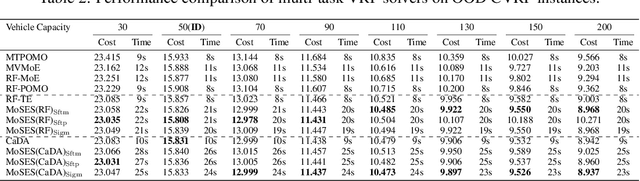
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.
Hierarchical Learning-based Graph Partition for Large-scale Vehicle Routing Problems
Feb 12, 2025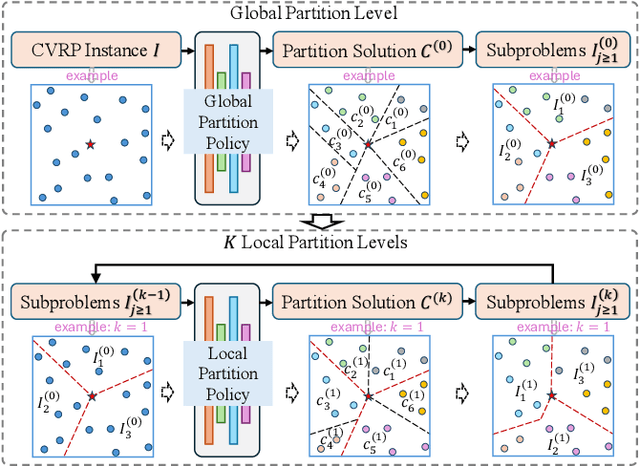
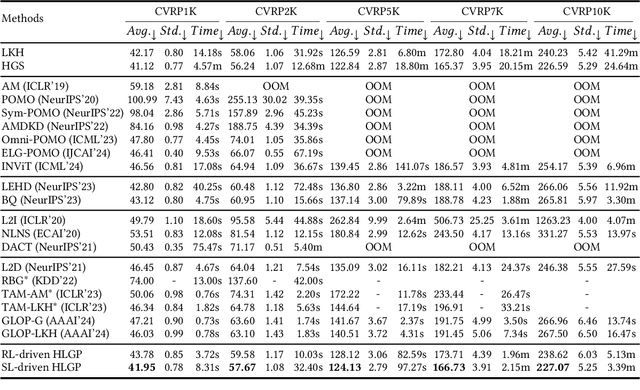
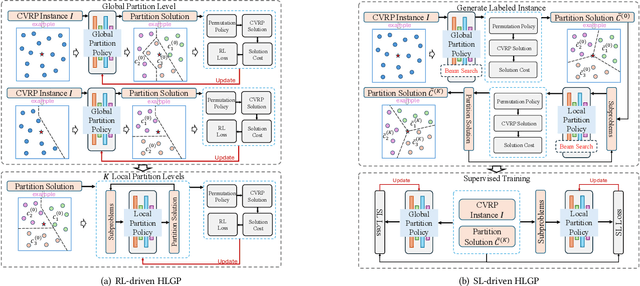
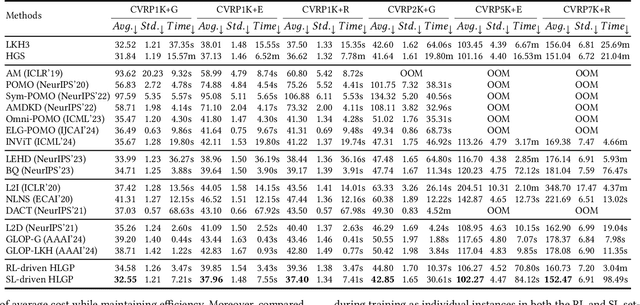
Neural solvers based on the divide-and-conquer approach for Vehicle Routing Problems (VRPs) in general, and capacitated VRP (CVRP) in particular, integrates the global partition of an instance with local constructions for each subproblem to enhance generalization. However, during the global partition phase, misclusterings within subgraphs have a tendency to progressively compound throughout the multi-step decoding process of the learning-based partition policy. This suboptimal behavior in the global partition phase, in turn, may lead to a dramatic deterioration in the performance of the overall decomposition-based system, despite using optimal local constructions. To address these challenges, we propose a versatile Hierarchical Learning-based Graph Partition (HLGP) framework, which is tailored to benefit the partition of CVRP instances by synergistically integrating global and local partition policies. Specifically, the global partition policy is tasked with creating the coarse multi-way partition to generate the sequence of simpler two-way partition subtasks. These subtasks mark the initiation of the subsequent K local partition levels. At each local partition level, subtasks exclusive for this level are assigned to the local partition policy which benefits from the insensitive local topological features to incrementally alleviate the compounded errors. This framework is versatile in the sense that it optimizes the involved partition policies towards a unified objective harmoniously compatible with both reinforcement learning (RL) and supervised learning (SL). (*Due to the notification of arXiv "The Abstract field cannot be longer than 1,920 characters", the appeared Abstract is shortened. For the full Abstract, please download the Article.)
SEAL: SEmantic-Augmented Imitation Learning via Language Model
Oct 03, 2024Hierarchical Imitation Learning (HIL) is a promising approach for tackling long-horizon decision-making tasks. While it is a challenging task due to the lack of detailed supervisory labels for sub-goal learning, and reliance on hundreds to thousands of expert demonstrations. In this work, we introduce SEAL, a novel framework that leverages Large Language Models (LLMs)'s powerful semantic and world knowledge for both specifying sub-goal space and pre-labeling states to semantically meaningful sub-goal representations without prior knowledge of task hierarchies. SEAL employs a dual-encoder structure, combining supervised LLM-guided sub-goal learning with unsupervised Vector Quantization (VQ) for more robust sub-goal representations. Additionally, SEAL incorporates a transition-augmented low-level planner for improved adaptation to sub-goal transitions. Our experiments demonstrate that SEAL outperforms state-of-the-art HIL methods and LLM-based planning approaches, particularly in settings with small expert datasets and complex long-horizon tasks.
C-MORL: Multi-Objective Reinforcement Learning through Efficient Discovery of Pareto Front
Oct 03, 2024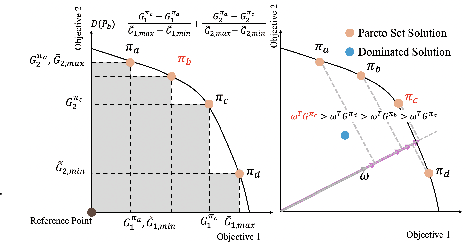
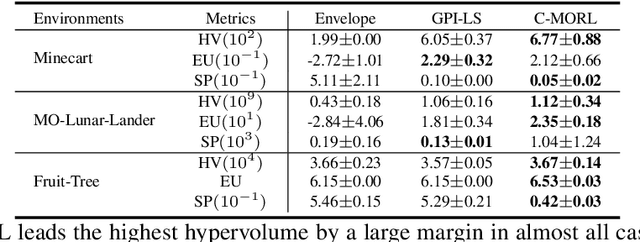
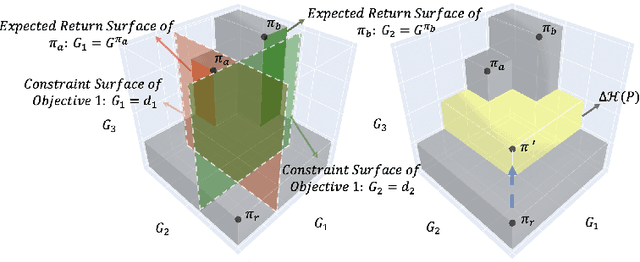
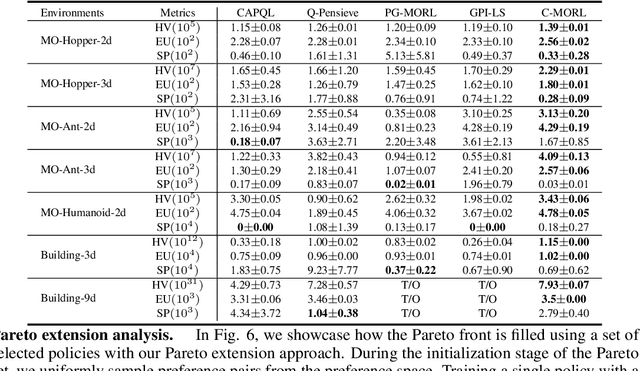
Multi-objective reinforcement learning (MORL) excels at handling rapidly changing preferences in tasks that involve multiple criteria, even for unseen preferences. However, previous dominating MORL methods typically generate a fixed policy set or preference-conditioned policy through multiple training iterations exclusively for sampled preference vectors, and cannot ensure the efficient discovery of the Pareto front. Furthermore, integrating preferences into the input of policy or value functions presents scalability challenges, in particular as the dimension of the state and preference space grow, which can complicate the learning process and hinder the algorithm's performance on more complex tasks. To address these issues, we propose a two-stage Pareto front discovery algorithm called Constrained MORL (C-MORL), which serves as a seamless bridge between constrained policy optimization and MORL. Concretely, a set of policies is trained in parallel in the initialization stage, with each optimized towards its individual preference over the multiple objectives. Then, to fill the remaining vacancies in the Pareto front, the constrained optimization steps are employed to maximize one objective while constraining the other objectives to exceed a predefined threshold. Empirically, compared to recent advancements in MORL methods, our algorithm achieves more consistent and superior performances in terms of hypervolume, expected utility, and sparsity on both discrete and continuous control tasks, especially with numerous objectives (up to nine objectives in our experiments).
Learning and Optimization for Price-based Demand Response of Electric Vehicle Charging
Apr 16, 2024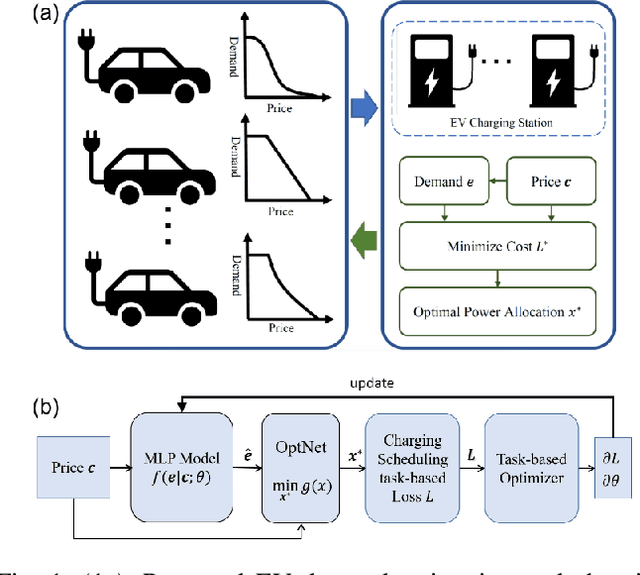
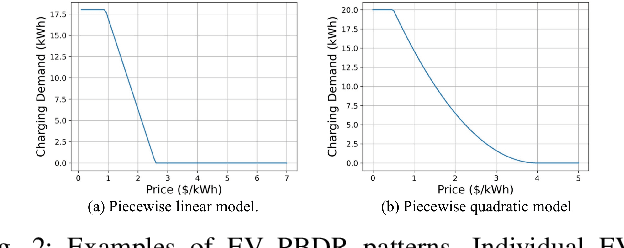
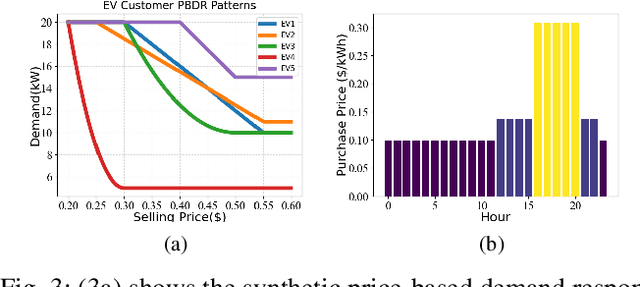
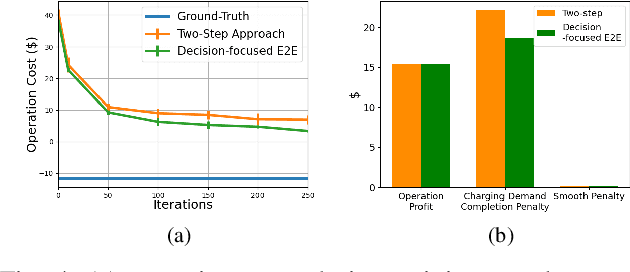
In the context of charging electric vehicles (EVs), the price-based demand response (PBDR) is becoming increasingly significant for charging load management. Such response usually encourages cost-sensitive customers to adjust their energy demand in response to changes in price for financial incentives. Thus, to model and optimize EV charging, it is important for charging station operator to model the PBDR patterns of EV customers by precisely predicting charging demands given price signals. Then the operator refers to these demands to optimize charging station power allocation policy. The standard pipeline involves offline fitting of a PBDR function based on historical EV charging records, followed by applying estimated EV demands in downstream charging station operation optimization. In this work, we propose a new decision-focused end-to-end framework for PBDR modeling that combines prediction errors and downstream optimization cost errors in the model learning stage. We evaluate the effectiveness of our method on a simulation of charging station operation with synthetic PBDR patterns of EV customers, and experimental results demonstrate that this framework can provide a more reliable prediction model for the ultimate optimization process, leading to more effective optimization solutions in terms of cost savings and charging station operation objectives with only a few training samples.
Distance-rank Aware Sequential Reward Learning for Inverse Reinforcement Learning with Sub-optimal Demonstrations
Oct 13, 2023

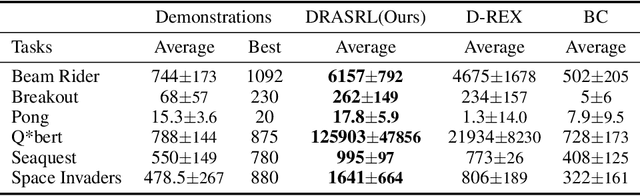

Inverse reinforcement learning (IRL) aims to explicitly infer an underlying reward function based on collected expert demonstrations. Considering that obtaining expert demonstrations can be costly, the focus of current IRL techniques is on learning a better-than-demonstrator policy using a reward function derived from sub-optimal demonstrations. However, existing IRL algorithms primarily tackle the challenge of trajectory ranking ambiguity when learning the reward function. They overlook the crucial role of considering the degree of difference between trajectories in terms of their returns, which is essential for further removing reward ambiguity. Additionally, it is important to note that the reward of a single transition is heavily influenced by the context information within the trajectory. To address these issues, we introduce the Distance-rank Aware Sequential Reward Learning (DRASRL) framework. Unlike existing approaches, DRASRL takes into account both the ranking of trajectories and the degrees of dissimilarity between them to collaboratively eliminate reward ambiguity when learning a sequence of contextually informed reward signals. Specifically, we leverage the distance between policies, from which the trajectories are generated, as a measure to quantify the degree of differences between traces. This distance-aware information is then used to infer embeddings in the representation space for reward learning, employing the contrastive learning technique. Meanwhile, we integrate the pairwise ranking loss function to incorporate ranking information into the latent features. Moreover, we resort to the Transformer architecture to capture the contextual dependencies within the trajectories in the latent space, leading to more accurate reward estimation. Through extensive experimentation, our DRASRL framework demonstrates significant performance improvements over previous SOTA methods.
Adjustable Robust Reinforcement Learning for Online 3D Bin Packing
Oct 06, 2023Designing effective policies for the online 3D bin packing problem (3D-BPP) has been a long-standing challenge, primarily due to the unpredictable nature of incoming box sequences and stringent physical constraints. While current deep reinforcement learning (DRL) methods for online 3D-BPP have shown promising results in optimizing average performance over an underlying box sequence distribution, they often fail in real-world settings where some worst-case scenarios can materialize. Standard robust DRL algorithms tend to overly prioritize optimizing the worst-case performance at the expense of performance under normal problem instance distribution. To address these issues, we first introduce a permutation-based attacker to investigate the practical robustness of both DRL-based and heuristic methods proposed for solving online 3D-BPP. Then, we propose an adjustable robust reinforcement learning (AR2L) framework that allows efficient adjustment of robustness weights to achieve the desired balance of the policy's performance in average and worst-case environments. Specifically, we formulate the objective function as a weighted sum of expected and worst-case returns, and derive the lower performance bound by relating to the return under a mixture dynamics. To realize this lower bound, we adopt an iterative procedure that searches for the associated mixture dynamics and improves the corresponding policy. We integrate this procedure into two popular robust adversarial algorithms to develop the exact and approximate AR2L algorithms. Experiments demonstrate that AR2L is versatile in the sense that it improves policy robustness while maintaining an acceptable level of performance for the nominal case.
Laxity-Aware Scalable Reinforcement Learning for HVAC Control
Jun 29, 2023



Demand flexibility plays a vital role in maintaining grid balance, reducing peak demand, and saving customers' energy bills. Given their highly shiftable load and significant contribution to a building's energy consumption, Heating, Ventilation, and Air Conditioning (HVAC) systems can provide valuable demand flexibility to the power systems by adjusting their energy consumption in response to electricity price and power system needs. To exploit this flexibility in both operation time and power, it is imperative to accurately model and aggregate the load flexibility of a large population of HVAC systems as well as designing effective control algorithms. In this paper, we tackle the curse of dimensionality issue in modeling and control by utilizing the concept of laxity to quantify the emergency level of each HVAC operation request. We further propose a two-level approach to address energy optimization for a large population of HVAC systems. The lower level involves an aggregator to aggregate HVAC load laxity information and use least-laxity-first (LLF) rule to allocate real-time power for individual HVAC systems based on the controller's total power. Due to the complex and uncertain nature of HVAC systems, we leverage a reinforcement learning (RL)-based controller to schedule the total power based on the aggregated laxity information and electricity price. We evaluate the temperature control and energy cost saving performance of a large-scale group of HVAC systems in both single-zone and multi-zone scenarios, under varying climate and electricity market conditions. The experiment results indicate that proposed approach outperforms the centralized methods in the majority of test scenarios, and performs comparably to model-based method in some scenarios.