 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: SEmantic-Augmented Imitation Learning via Language Model
Oct 03, 2024Hierarchical Imitation Learning (HIL) is a promising approach for tackling long-horizon decision-making tasks. While it is a challenging task due to the lack of detailed supervisory labels for sub-goal learning, and reliance on hundreds to thousands of expert demonstrations. In this work, we introduce SEAL, a novel framework that leverages Large Language Models (LLMs)'s powerful semantic and world knowledge for both specifying sub-goal space and pre-labeling states to semantically meaningful sub-goal representations without prior knowledge of task hierarchies. SEAL employs a dual-encoder structure, combining supervised LLM-guided sub-goal learning with unsupervised Vector Quantization (VQ) for more robust sub-goal representations. Additionally, SEAL incorporates a transition-augmented low-level planner for improved adaptation to sub-goal transitions. Our experiments demonstrate that SEAL outperforms state-of-the-art HIL methods and LLM-based planning approaches, particularly in settings with small expert datasets and complex long-horizon tasks.
Hi-Map: Hierarchical Factorized Radiance Field for High-Fidelity Monocular Dense Mapping
Jan 06, 2024In this paper, we introduce Hi-Map, a novel monocular dense mapping approach based on Neural Radiance Field (NeRF). Hi-Map is exceptional in its capacity to achieve efficient and high-fidelity mapping using only posed RGB inputs. Our method eliminates the need for external depth priors derived from e.g., a depth estimation model. Our key idea is to represent the scene as a hierarchical feature grid that encodes the radiance and then factorizes it into feature planes and vectors. As such, the scene representation becomes simpler and more generalizable for fast and smooth convergence on new observations. This allows for efficient computation while alleviating noise patterns by reducing the complexity of the scene representation. Buttressed by the hierarchical factorized representation, we leverage the Sign Distance Field (SDF) as a proxy of rendering for inferring the volume density, demonstrating high mapping fidelity. Moreover, we introduce a dual-path encoding strategy to strengthen the photometric cues and further boost the mapping quality, especially for the distant and textureless regions. Extensive experiments demonstrate our method's superiority in geometric and textural accuracy over the state-of-the-art NeRF-based monocular mapping methods.
Dynamic PlenOctree for Adaptive Sampling Refinement in Explicit NeRF
Jul 28, 2023The explicit neural radiance field (NeRF) has gained considerable interest for its efficient training and fast inference capabilities, making it a promising direction such as virtual reality and gaming. In particular, PlenOctree (POT)[1], an explicit hierarchical multi-scale octree representation, has emerged as a structural and influential framework. However, POT's fixed structure for direct optimization is sub-optimal as the scene complexity evolves continuously with updates to cached color and density, necessitating refining the sampling distribution to capture signal complexity accordingly. To address this issue, we propose the dynamic PlenOctree DOT, which adaptively refines the sample distribution to adjust to changing scene complexity. Specifically, DOT proposes a concise yet novel hierarchical feature fusion strategy during the iterative rendering process. Firstly, it identifies the regions of interest through training signals to ensure adaptive and efficient refinement. Next, rather than directly filtering out valueless nodes, DOT introduces the sampling and pruning operations for octrees to aggregate features, enabling rapid parameter learning. Compared with POT, our DOT outperforms it by enhancing visual quality, reducing over $55.15$/$68.84\%$ parameters, and providing 1.7/1.9 times FPS for NeRF-synthetic and Tanks $\&$ Temples, respectively. Project homepage:https://vlislab22.github.io/DOT. [1] Yu, Alex, et al. "Plenoctrees for real-time rendering of neural radiance fields." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
FMapping: Factorized Efficient Neural Field Mapping for Real-Time Dense RGB SLAM
Jun 01, 2023In this paper, we introduce FMapping, an efficient neural field mapping framework that facilitates the continuous estimation of a colorized point cloud map in real-time dense RGB SLAM. To achieve this challenging goal without depth, a hurdle is how to improve efficiency and reduce the mapping uncertainty of the RGB SLAM system. To this end, we first build up a theoretical analysis by decomposing the SLAM system into tracking and mapping parts, and the mapping uncertainty is explicitly defined within the frame of neural representations. Based on the analysis, we then propose an effective factorization scheme for scene representation and introduce a sliding window strategy to reduce the uncertainty for scene reconstruction. Specifically, we leverage the factorized neural field to decompose uncertainty into a lower-dimensional space, which enhances robustness to noise and improves training efficiency. We then propose the sliding window sampler to reduce uncertainty by incorporating coherent geometric cues from observed frames during map initialization to enhance convergence. Our factorized neural mapping approach enjoys some advantages, such as low memory consumption, more efficient computation, and fast convergence during map initialization. Experiments on two benchmark datasets show that our method can update the map of high-fidelity colorized point clouds around 2 seconds in real time while requiring no customized CUDA kernels. Additionally, it utilizes x20 fewer parameters than the most concise neural implicit mapping of prior methods for SLAM, e.g., iMAP [ 31] and around x1000 fewer parameters than the state-of-the-art approach, e.g., NICE-SLAM [ 42]. For more details, please refer to our project homepage: https://vlis2022.github.io/fmap/.
CompoNeRF: Text-guided Multi-object Compositional NeRF with Editable 3D Scene Layout
Mar 24, 2023


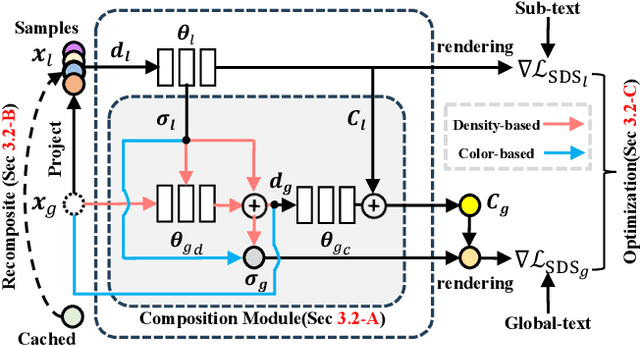
Recent research endeavors have shown that combining neural radiance fields (NeRFs) with pre-trained diffusion models holds great potential for text-to-3D generation.However, a hurdle is that they often encounter guidance collapse when rendering complex scenes from multi-object texts. Because the text-to-image diffusion models are inherently unconstrained, making them less competent to accurately associate object semantics with specific 3D structures. To address this issue, we propose a novel framework, dubbed CompoNeRF, that explicitly incorporates an editable 3D scene layout to provide effective guidance at the single object (i.e., local) and whole scene (i.e., global) levels. Firstly, we interpret the multi-object text as an editable 3D scene layout containing multiple local NeRFs associated with the object-specific 3D box coordinates and text prompt, which can be easily collected from users. Then, we introduce a global MLP to calibrate the compositional latent features from local NeRFs, which surprisingly improves the view consistency across different local NeRFs. Lastly, we apply the text guidance on global and local levels through their corresponding views to avoid guidance ambiguity. This way, our CompoNeRF allows for flexible scene editing and re-composition of trained local NeRFs into a new scene by manipulating the 3D layout or text prompt. Leveraging the open-source Stable Diffusion model, our CompoNeRF can generate faithful and editable text-to-3D results while opening a potential direction for text-guided multi-object composition via the editable 3D scene layout.
Patch-Mix Transformer for Unsupervised Domain Adaptation: A Game Perspective
Mar 23, 2023Endeavors have been recently made to leverage the vision transformer (ViT) for the challenging unsupervised domain adaptation (UDA) task. They typically adopt the cross-attention in ViT for direct domain alignment. However, as the performance of cross-attention highly relies on the quality of pseudo labels for targeted samples, it becomes less effective when the domain gap becomes large. We solve this problem from a game theory's perspective with the proposed model dubbed as PMTrans, which bridges source and target domains with an intermediate domain. Specifically, we propose a novel ViT-based module called PatchMix that effectively builds up the intermediate domain, i.e., probability distribution, by learning to sample patches from both domains based on the game-theoretical models. This way, it learns to mix the patches from the source and target domains to maximize the cross entropy (CE), while exploiting two semi-supervised mixup losses in the feature and label spaces to minimize it. As such, we interpret the process of UDA as a min-max CE game with three players, including the feature extractor, classifier, and PatchMix, to find the Nash Equilibria. Moreover, we leverage attention maps from ViT to re-weight the label of each patch by its importance, making it possible to obtain more domain-discriminative feature representations. We conduct extensive experiments on four benchmark datasets, and the results show that PMTrans significantly surpasses the ViT-based and CNN-based SoTA methods by +3.6% on Office-Home, +1.4% on Office-31, and +17.7% on DomainNet, respectively.
Weakly Supervised Object Localization via Transformer with Implicit Spatial Calibration
Jul 21, 2022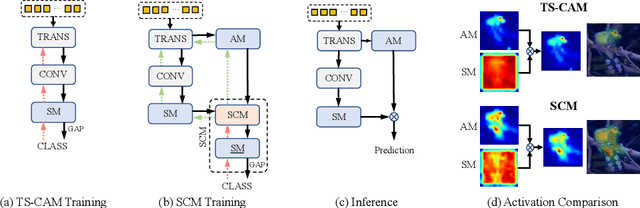
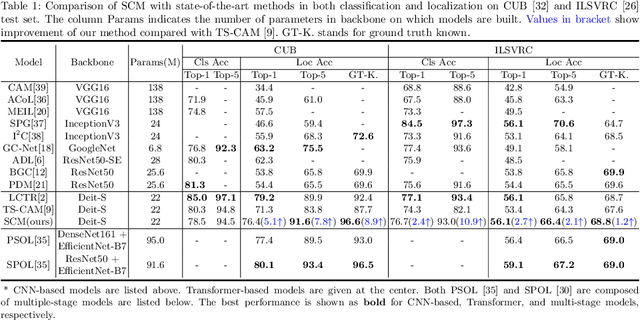
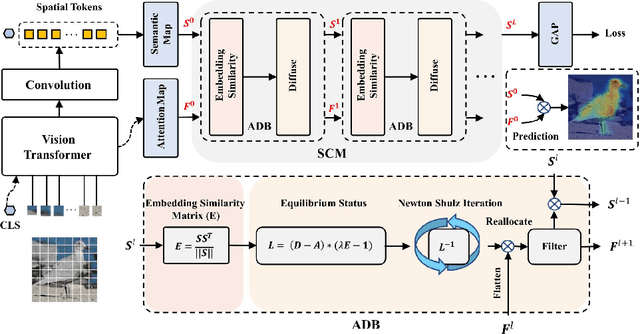
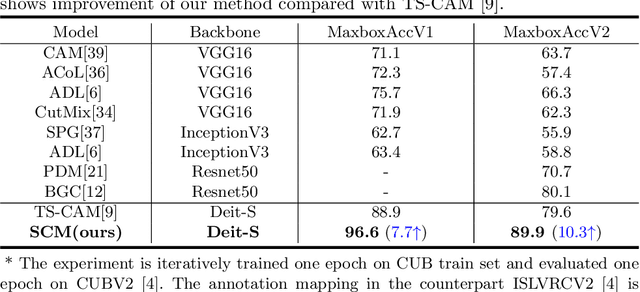
Weakly Supervised Object Localization (WSOL), which aims to localize objects by only using image-level labels, has attracted much attention because of its low annotation cost in real applications. Recent studies leverage the advantage of self-attention in visual Transformer for long-range dependency to re-active semantic regions, aiming to avoid partial activation in traditional class activation mapping (CAM). However, the long-range modeling in Transformer neglects the inherent spatial coherence of the object, and it usually diffuses the semantic-aware regions far from the object boundary, making localization results significantly larger or far smaller. To address such an issue, we introduce a simple yet effective Spatial Calibration Module (SCM) for accurate WSOL, incorporating semantic similarities of patch tokens and their spatial relationships into a unified diffusion model. Specifically, we introduce a learnable parameter to dynamically adjust the semantic correlations and spatial context intensities for effective information propagation. In practice, SCM is designed as an external module of Transformer, and can be removed during inference to reduce the computation cost. The object-sensitive localization ability is implicitly embedded into the Transformer encoder through optimization in the training phase. It enables the generated attention maps to capture the sharper object boundaries and filter the object-irrelevant background area. Extensive experimental results demonstrate the effectiveness of the proposed method, which significantly outperforms its counterpart TS-CAM on both CUB-200 and ImageNet-1K benchmarks. The code is available at https://github.com/164140757/SCM.
AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Jun 16, 2022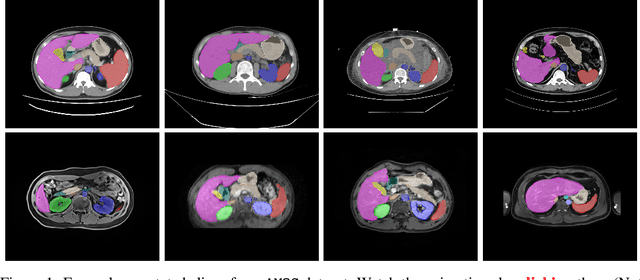
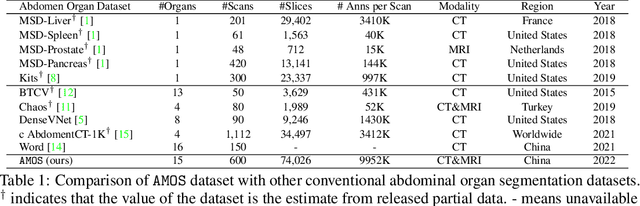
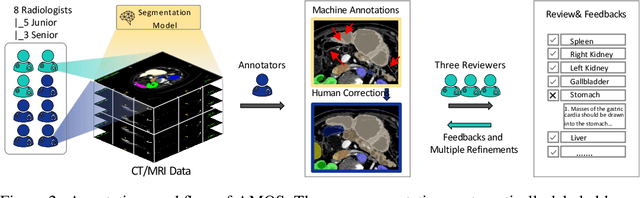
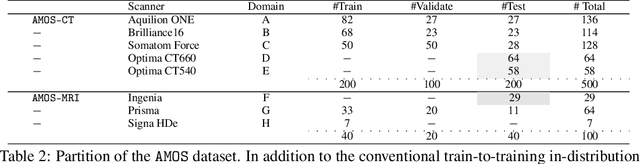
Despite the considerable progress in automatic abdominal multi-organ segmentation from CT/MRI scans in recent years, a comprehensive evaluation of the models' capabilities is hampered by the lack of a large-scale benchmark from diverse clinical scenarios. Constraint by the high cost of collecting and labeling 3D medical data, most of the deep learning models to date are driven by datasets with a limited number of organs of interest or samples, which still limits the power of modern deep models and makes it difficult to provide a fully comprehensive and fair estimate of various methods. To mitigate the limitations, we present AMOS, a large-scale, diverse, clinical dataset for abdominal organ segmentation. AMOS provides 500 CT and 100 MRI scans collected from multi-center, multi-vendor, multi-modality, multi-phase, multi-disease patients, each with voxel-level annotations of 15 abdominal organs, providing challenging examples and test-bed for studying robust segmentation algorithms under diverse targets and scenarios. We further benchmark several state-of-the-art medical segmentation models to evaluate the status of the existing methods on this new challenging dataset. We have made our datasets, benchmark servers, and baselines publicly available, and hope to inspire future research. Information can be found at https://amos22.grand-challenge.org.
Deep Learning for Omnidirectional Vision: A Survey and New Perspectives
May 24, 2022
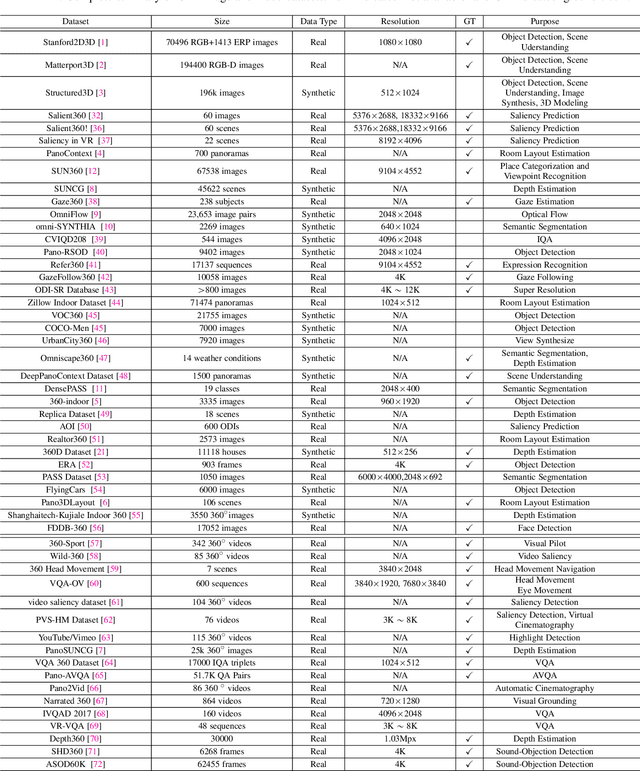


Omnidirectional image (ODI) data is captured with a 360x180 field-of-view, which is much wider than the pinhole cameras and contains richer spatial information than the conventional planar images. Accordingly, omnidirectional vision has attracted booming attention due to its more advantageous performance in numerous applications, such as autonomous driving and virtual reality. In recent years, the availability of customer-level 360 cameras has made omnidirectional vision more popular, and the advance of deep learning (DL) has significantly sparked its research and applications. This paper presents a systematic and comprehensive review and analysis of the recent progress in DL methods for omnidirectional vision. Our work covers four main contents: (i) An introduction to the principle of omnidirectional imaging, the convolution methods on the ODI, and datasets to highlight the differences and difficulties compared with the 2D planar image data; (ii) A structural and hierarchical taxonomy of the DL methods for omnidirectional vision; (iii) A summarization of the latest novel learning strategies and applications; (iv) An insightful discussion of the challenges and open problems by highlighting the potential research directions to trigger more research in the community.