 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Benchmarks Overstate Forward-Forward Scaling: Real-Data Limits of Layer-Local Training
Jun 04, 2026Forward-Forward (FF) learning [Hinton, 2022] replaces backpropagation with strictly layer-local goodness updates. Recent FF-CNN work has narrowed the gap to BP on 32x32 benchmarks, raising the question of whether layer-local training is becoming a viable alternative at realistic scale. To probe this rigorously, we develop DTG-FF -- dynamic temperature goodness, decoupled normalization, and multi-layer fusion -- as an instrument that sets FF-family state of the art across nine real-data benchmarks (91.8% CIFAR-10 and the first FF baseline at ImageNet-100 224x224), and use it to audit how far layer-local training actually scales. (1) Real-data scaling. Under identical recipe and backbone, an architecture-matched BP-DeepSup baseline beats DTG-FF by 2.40/5.93 pp on CIFAR-10/CIFAR-100, and the gap widens with class count. At 224x224 the same instrument reaches only 49.4% -- the first FF baseline at this scale, versus typical BP above 75% [Tian et al., 2020] -- exposing a real-data ceiling invisible at 32x32. (2) Synthetic vs. real K-conflict. DTG-FF increasingly outperforms BP as class count K grows on synthetic teacher-student tasks, yet on real images the FF-BP gap reverses sign and widens with K. A within-dataset CIFAR-100 coarse vs. fine probe isolates label-hierarchy from image distribution: synthetic K-sweeps confound output dimensionality with fine-grained discrimination difficulty and thereby overstate FF transferability. (3) Systems audit. FF can be implemented without storing depth-wide activations, but on commodity 8 GB hardware standard BP+gradient-accumulation reaches 4.18 GB / 157 imgs/s versus DTG-FF's 7.90 GB / 138 imgs/s, so a memory-based justification for FF at this scale is not supported under fair baselines.
One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
May 21, 2026Existing approaches for digital short-drama production typically rely on one-shot LLM generated scripts and loosely coupled pipelines, which fail to satisfy three key requirements of short-drama generation: (1) narrative pacing, resulting in weak hooks, insufficient escalation, and unattractive endings; (2) spatial consistency, leading to drifting scene layouts and inconsistent character positions across clips; and (3) production-level quality control, requiring extensive manual review and correction across script and visual stages. We present One Sentence, One Drama, a hierarchical multi-agent framework that transforms a user's single-sentence idea into a fully produced short drama through structured intermediate modules and iterative refinement. Our approach is built upon three key components: (1) a multi-agent debate-based story generation module that enforces short-drama pacing and narrative coherence; (2) a 3D-grounded first-frame generation mechanism that establishes a shared spatial reference for consistent character positioning and scene layout across clips; and (3) multi-stage reviewer loops that perform comprehensive error detection and targeted revision across script, visual, and video generation stages. We also introduce scene-level BGM matching and scene transition planning to improve the audience's immersive experience. To systematically evaluate this task, we introduce Short-Drama-Bench, a benchmark that extends standard video quality metrics with short-drama-specific criteria. Experimental results demonstrate that our method significantly outperforms existing pipelines in narrative quality, cross-clip consistency, and overall viewing experience.
SegWithU: Uncertainty as Perturbation Energy for Single-Forward-Pass Risk-Aware Medical Image Segmentation
Apr 16, 2026Reliable uncertainty estimation is critical for medical image segmentation, where automated contours feed downstream quantification and clinical decision support. Many strong uncertainty methods require repeated inference, while efficient single-forward-pass alternatives often provide weaker failure ranking or rely on restrictive feature-space assumptions. We present $\textbf{SegWithU}$, a post-hoc framework that augments a frozen pretrained segmentation backbone with a lightweight uncertainty head. SegWithU taps intermediate backbone features and models uncertainty as perturbation energy in a compact probe space using rank-1 posterior probes. It produces two voxel-wise uncertainty maps: a calibration-oriented map for probability tempering and a ranking-oriented map for error detection and selective prediction. Across ACDC, BraTS2024, and LiTS, SegWithU is the strongest and most consistent single-forward-pass baseline, achieving AUROC/AURC of $0.9838/2.4885$, $0.9946/0.2660$, and $0.9925/0.8193$, respectively, while preserving segmentation quality. These results suggest that perturbation-based uncertainty modeling is an effective and practical route to reliability-aware medical segmentation. Source code is available at https://github.com/ProjectNeura/SegWithU.
V-Reflection: Transforming MLLMs from Passive Observers to Active Interrogators
Mar 31, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success, yet they remain prone to perception-related hallucinations in fine-grained tasks. This vulnerability arises from a fundamental limitation: their reasoning is largely restricted to the language domain, treating visual input as a static, reasoning-agnostic preamble rather than a dynamic participant. Consequently, current models act as passive observers, unable to re-examine visual details to ground their evolving reasoning states. To overcome this, we propose V-Reflection, a framework that transforms the MLLM into an active interrogator through a "think-then-look" visual reflection mechanism. During reasoning, latent states function as dynamic probes that actively interrogate the visual feature space, grounding each reasoning step for task-critical evidence. Our approach employs a two-stage distillation strategy. First, the Box-Guided Compression (BCM) module establishes stable pixel-to-latent targets through explicit spatial grounding. Next, a Dynamic Autoregressive Compression (DAC) module maps the model's hidden states into dynamic probes that interrogate the global visual feature map. By distilling the spatial expertise of the BCM teacher into the DAC student, V-Reflection internalizes the ability to localize task-critical evidence. During inference, both modules remain entirely inactive, maintaining a purely end-to-end autoregressive decoding in the latent space with optimal efficiency. Extensive experiments demonstrate the effectiveness of our V-Reflection across six perception-intensive benchmarks, significantly narrowing the fine-grained perception gap. Visualizations confirm that latent reasoning autonomously localizes task-critical visual evidence.
SortScrews: A Dataset and Baseline for Real-time Screw Classification
Mar 13, 2026Automatic identification of screw types is important for industrial automation, robotics, and inventory management. However, publicly available datasets for screw classification are scarce, particularly for controlled single-object scenarios commonly encountered in automated sorting systems. In this work, we introduce $\textbf{SortScrews}$, a dataset for casewise visual classification of screws. The dataset contains 560 RGB images at $512\times512$ resolution covering six screw types and a background class. Images are captured using a standardized acquisition setup and include mild variations in lighting and camera perspective across four capture settings. To facilitate reproducible research and dataset expansion, we also provide a reusable data collection script that allows users to easily construct similar datasets for custom hardware components using inexpensive camera setups. We establish baseline results using transfer learning with EfficientNet-B0 and ResNet-18 classifiers pretrained on ImageNet. In addition, we conduct a well-explored failure analysis. Despite the limited dataset size, these lightweight models achieve strong classification accuracy, demonstrating that controlled acquisition conditions enable effective learning even with relatively small datasets. The dataset, collection pipeline, and baseline training code are publicly available at https://github.com/ATATC/SortScrews.
MIP Candy: A Modular PyTorch Framework for Medical Image Processing
Feb 24, 2026Medical image processing demands specialized software that handles high-dimensional volumetric data, heterogeneous file formats, and domain-specific training procedures. Existing frameworks either provide low-level components that require substantial integration effort or impose rigid, monolithic pipelines that resist modification. We present MIP Candy (MIPCandy), a freely available, PyTorch-based framework designed specifically for medical image processing. MIPCandy provides a complete, modular pipeline spanning data loading, training, inference, and evaluation, allowing researchers to obtain a fully functional process workflow by implementing a single method, $\texttt{build_network}$, while retaining fine-grained control over every component. Central to the design is $\texttt{LayerT}$, a deferred configuration mechanism that enables runtime substitution of convolution, normalization, and activation modules without subclassing. The framework further offers built-in $k$-fold cross-validation, dataset inspection with automatic region-of-interest detection, deep supervision, exponential moving average, multi-frontend experiment tracking (Weights & Biases, Notion, MLflow), training state recovery, and validation score prediction via quotient regression. An extensible bundle ecosystem provides pre-built model implementations that follow a consistent trainer--predictor pattern and integrate with the core framework without modification. MIPCandy is open-source under the Apache-2.0 license and requires Python~3.12 or later. Source code and documentation are available at https://github.com/ProjectNeura/MIPCandy.
MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations
Mar 06, 2025



Despite significant progress in Vision-Language Pre-training (VLP), current approaches predominantly emphasize feature extraction and cross-modal comprehension, with limited attention to generating or transforming visual content. This gap hinders the model's ability to synthesize coherent and novel visual representations from textual prompts, thereby reducing the effectiveness of multi-modal learning. In this work, we propose MedUnifier, a unified VLP framework tailored for medical data. MedUnifier seamlessly integrates text-grounded image generation capabilities with multi-modal learning strategies, including image-text contrastive alignment, image-text matching and image-grounded text generation. Unlike traditional methods that reply on continuous visual representations, our approach employs visual vector quantization, which not only facilitates a more cohesive learning strategy for cross-modal understanding but also enhances multi-modal generation quality by effectively leveraging discrete representations. Our framework's effectiveness is evidenced by the experiments on established benchmarks, including uni-modal tasks (supervised fine-tuning), cross-modal tasks (image-text retrieval and zero-shot image classification), and multi-modal tasks (medical report generation, image synthesis), where it achieves state-of-the-art performance across various tasks. MedUnifier also offers a highly adaptable tool for a wide range of language and vision tasks in healthcare, marking advancement toward the development of a generalizable AI model for medical applications.
CLIP the Divergence: Language-guided Unsupervised Domain Adaptation
Jul 01, 2024Unsupervised domain adaption (UDA) has emerged as a popular solution to tackle the divergence between the labeled source and unlabeled target domains. Recently, some research efforts have been made to leverage large vision-language models, such as CLIP, and then fine-tune or learn prompts from them for addressing the challenging UDA task. In this work, we shift the gear to a new direction by directly leveraging CLIP to measure the domain divergence and propose a novel language-guided approach for UDA, dubbed as CLIP-Div. Our key idea is to harness CLIP to 1) measure the domain divergence via the acquired domain-agnostic distribution and 2) calibrate the target pseudo labels with language guidance, to effectively reduce the domain gap and improve the UDA model's generalization capability. Specifically, our major technical contribution lies in the proposed two novel language-guided domain divergence measurement losses: absolute divergence and relative divergence. These loss terms furnish precise guidelines for aligning the distributions of the source and target domains with the domain-agnostic distribution derived from CLIP. Additionally, we propose a language-guided pseudo-labeling strategy for calibrating the target pseudo labels. Buttressed by it, we show that a further implementation for self-training can enhance the UDA model's generalization capability on the target domain. CLIP-Div surpasses state-of-the-art CNN-based methods by a substantial margin, achieving a performance boost of +10.3% on Office-Home, +1.5% on Office-31, +0.2% on VisDA-2017, and +24.3% on DomainNet, respectively.
eMoE-Tracker: Environmental MoE-based Transformer for Robust Event-guided Object Tracking
Jun 28, 2024The unique complementarity of frame-based and event cameras for high frame rate object tracking has recently inspired some research attempts to develop multi-modal fusion approaches. However, these methods directly fuse both modalities and thus ignore the environmental attributes, e.g., motion blur, illumination variance, occlusion, scale variation, etc. Meanwhile, no interaction between search and template features makes distinguishing target objects and backgrounds difficult. As a result, performance degradation is induced especially in challenging conditions. This paper proposes a novel and effective Transformer-based event-guided tracking framework, called eMoE-Tracker, which achieves new SOTA performance under various conditions. Our key idea is to disentangle the environment into several learnable attributes to dynamically learn the attribute-specific features for better interaction and discriminability between the target information and background. To achieve the goal, we first propose an environmental Mix-of-Experts (eMoE) module that is built upon the environmental Attributes Disentanglement to learn attribute-specific features and environmental Attributes Gating to assemble the attribute-specific features by the learnable attribute scores dynamically. The eMoE module is a subtle router that fine-tunes the transformer backbone more efficiently. We then introduce a contrastive relation modeling (CRM) module to improve interaction and discriminability between the target information and background. Extensive experiments on diverse event-based benchmark datasets showcase the superior performance of our eMoE-Tracker compared to the prior arts.
Source-Free Cross-Modal Knowledge Transfer by Unleashing the Potential of Task-Irrelevant Data
Jan 10, 2024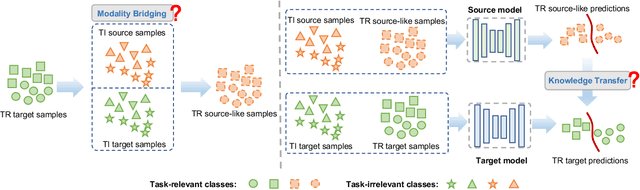
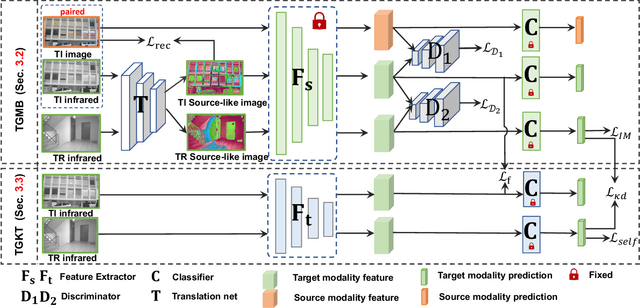

Source-free cross-modal knowledge transfer is a crucial yet challenging task, which aims to transfer knowledge from one source modality (e.g., RGB) to the target modality (e.g., depth or infrared) with no access to the task-relevant (TR) source data due to memory and privacy concerns. A recent attempt leverages the paired task-irrelevant (TI) data and directly matches the features from them to eliminate the modality gap. However, it ignores a pivotal clue that the paired TI data could be utilized to effectively estimate the source data distribution and better facilitate knowledge transfer to the target modality. To this end, we propose a novel yet concise framework to unlock the potential of paired TI data for enhancing source-free cross-modal knowledge transfer. Our work is buttressed by two key technical components. Firstly, to better estimate the source data distribution, we introduce a Task-irrelevant data-Guided Modality Bridging (TGMB) module. It translates the target modality data (e.g., infrared) into the source-like RGB images based on paired TI data and the guidance of the available source model to alleviate two key gaps: 1) inter-modality gap between the paired TI data; 2) intra-modality gap between TI and TR target data. We then propose a Task-irrelevant data-Guided Knowledge Transfer (TGKT) module that transfers knowledge from the source model to the target model by leveraging the paired TI data. Notably, due to the unavailability of labels for the TR target data and its less reliable prediction from the source model, our TGKT model incorporates a self-supervised pseudo-labeling approach to enable the target model to learn from its predictions. Extensive experiments show that our method achieves state-of-the-art performance on three datasets (RGB-to-depth and RGB-to-infrared).