 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Token-Level Cryptographic Redaction for Privacy-Preserving Clinical Deployment of Large Language Models
Jun 02, 2026While large language models (LLMs) are increasingly used for clinical applications, many existing pipelines require sending raw sensitive health information to remote servers for processing, which heightens the risk of privacy leakage. A natural approach to mitigate this risk is to encrypt the data before transmission. However, straightforward solutions such as encrypting the entire dataset introduce prohibitive computational, alignment, and communication overheads, rendering large-scale practical deployment infeasible. To preserve privacy while maintaining usability, we present Healthcare Encryption & Redaction via Adaptive Linguistic Decomposition (HERALD), a token-level cryptographic redaction framework designed to achieve this balance by encrypting only sensitive tokens while preserving the surrounding context for downstream model utility. HERALD combines medical named-entity recognizer (NER) with part-of-speech (POS) driven policies to select candidate tokens, performs targeted lemmatization to stabilize surface forms, and substitutes each protected token with a deterministic ciphertext wrapped in explicit delimiters. Notably, HERALD is model-agnostic and operates entirely on the client side, ensuring that sensitive content remains encrypted throughout storage, transmission, and processing without requiring changes to downstream models. We evaluated HERALD on both classification and medical question answering (MQA) tasks on public datasets. Across different tasks, experiments illustrate that fully secured baselines suffer significant utility loss, whereas HERALD consistently recovers performance close to plaintext. Overall, HERALD provides a novel utilization pipeline.
One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
May 21, 2026Existing approaches for digital short-drama production typically rely on one-shot LLM generated scripts and loosely coupled pipelines, which fail to satisfy three key requirements of short-drama generation: (1) narrative pacing, resulting in weak hooks, insufficient escalation, and unattractive endings; (2) spatial consistency, leading to drifting scene layouts and inconsistent character positions across clips; and (3) production-level quality control, requiring extensive manual review and correction across script and visual stages. We present One Sentence, One Drama, a hierarchical multi-agent framework that transforms a user's single-sentence idea into a fully produced short drama through structured intermediate modules and iterative refinement. Our approach is built upon three key components: (1) a multi-agent debate-based story generation module that enforces short-drama pacing and narrative coherence; (2) a 3D-grounded first-frame generation mechanism that establishes a shared spatial reference for consistent character positioning and scene layout across clips; and (3) multi-stage reviewer loops that perform comprehensive error detection and targeted revision across script, visual, and video generation stages. We also introduce scene-level BGM matching and scene transition planning to improve the audience's immersive experience. To systematically evaluate this task, we introduce Short-Drama-Bench, a benchmark that extends standard video quality metrics with short-drama-specific criteria. Experimental results demonstrate that our method significantly outperforms existing pipelines in narrative quality, cross-clip consistency, and overall viewing experience.
Uni-Encoder Meets Multi-Encoders: Representation Before Fusion for Brain Tumor Segmentation with Missing Modalities
Apr 24, 2026Multimodal MRI offers complementary information for brain tumor segmentation, but clinical scans often lack one or more modalities, which degrades segmentation performance. In this paper, we propose UniME (Uni-Encoder Meets Multi-Encoders), a two-stage heterogeneous method for brain tumor segmentation with missing modalities that reconciles the trade-offs among fine-grained structure capture, cross-modal complementarity modeling, and exploitation of available modalities. The idea is to decouple representation learning from segmentation via a two-stage heterogeneous architecture. Stage 1 pretrains a single ViT Uni-Encoder with masked image modeling to establish a unified representation robust to missing modalities. Stage 2 adds modality-specific CNN Multi-Encoders to extract high-resolution, multi-scale, fine-grained features. We fuse these features with the global representation to produce precise segmentations. Experiments on BraTS 2023 and BraTS 2024 show that UniME outperforms previous methods under incomplete multi-modal scenarios. The code is available at https://github.com/Hooorace-S/UniME
Beyond Linearity: Squeeze-and-Recalibrate Blocks for Few-Shot Whole Slide Image Classification
May 21, 2025Deep learning has advanced computational pathology but expert annotations remain scarce. Few-shot learning mitigates annotation burdens yet suffers from overfitting and discriminative feature mischaracterization. In addition, the current few-shot multiple instance learning (MIL) approaches leverage pretrained vision-language models to alleviate these issues, but at the cost of complex preprocessing and high computational cost. We propose a Squeeze-and-Recalibrate (SR) block, a drop-in replacement for linear layers in MIL models to address these challenges. The SR block comprises two core components: a pair of low-rank trainable matrices (squeeze pathway, SP) that reduces parameter count and imposes a bottleneck to prevent spurious feature learning, and a frozen random recalibration matrix that preserves geometric structure, diversifies feature directions, and redefines the optimization objective for the SP. We provide theoretical guarantees that the SR block can approximate any linear mapping to arbitrary precision, thereby ensuring that the performance of a standard MIL model serves as a lower bound for its SR-enhanced counterpart. Extensive experiments demonstrate that our SR-MIL models consistently outperform prior methods while requiring significantly fewer parameters and no architectural changes.
Future-Aware Interaction Network For Motion Forecasting
Mar 09, 2025



Motion forecasting is a crucial component of autonomous driving systems, enabling the generation of accurate and smooth future trajectories to ensure safe navigation to the destination. In previous methods, potential future trajectories are often absent in the scene encoding stage, which may lead to suboptimal outcomes. Additionally, prior approaches typically employ transformer architectures for spatiotemporal modeling of trajectories and map information, which suffer from the quadratic scaling complexity of the transformer architecture. In this work, we propose an interaction-based method, named Future-Aware Interaction Network, that introduces potential future trajectories into scene encoding for a comprehensive traffic representation. Furthermore, a State Space Model (SSM), specifically Mamba, is introduced for both spatial and temporal modeling. To adapt Mamba for spatial interaction modeling, we propose an adaptive reordering strategy that transforms unordered data into a structured sequence. Additionally, Mamba is employed to refine generated future trajectories temporally, ensuring more consistent predictions. These enhancements not only improve model efficiency but also enhance the accuracy and diversity of predictions. We conduct comprehensive experiments on the widely used Argoverse 1 and Argoverse 2 datasets, demonstrating that the proposed method achieves superior performance compared to previous approaches in a more efficient way. The code will be released according to the acceptance.
MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations
Mar 06, 2025



Despite significant progress in Vision-Language Pre-training (VLP), current approaches predominantly emphasize feature extraction and cross-modal comprehension, with limited attention to generating or transforming visual content. This gap hinders the model's ability to synthesize coherent and novel visual representations from textual prompts, thereby reducing the effectiveness of multi-modal learning. In this work, we propose MedUnifier, a unified VLP framework tailored for medical data. MedUnifier seamlessly integrates text-grounded image generation capabilities with multi-modal learning strategies, including image-text contrastive alignment, image-text matching and image-grounded text generation. Unlike traditional methods that reply on continuous visual representations, our approach employs visual vector quantization, which not only facilitates a more cohesive learning strategy for cross-modal understanding but also enhances multi-modal generation quality by effectively leveraging discrete representations. Our framework's effectiveness is evidenced by the experiments on established benchmarks, including uni-modal tasks (supervised fine-tuning), cross-modal tasks (image-text retrieval and zero-shot image classification), and multi-modal tasks (medical report generation, image synthesis), where it achieves state-of-the-art performance across various tasks. MedUnifier also offers a highly adaptable tool for a wide range of language and vision tasks in healthcare, marking advancement toward the development of a generalizable AI model for medical applications.
ETSCL: An Evidence Theory-Based Supervised Contrastive Learning Framework for Multi-modal Glaucoma Grading
Jul 19, 2024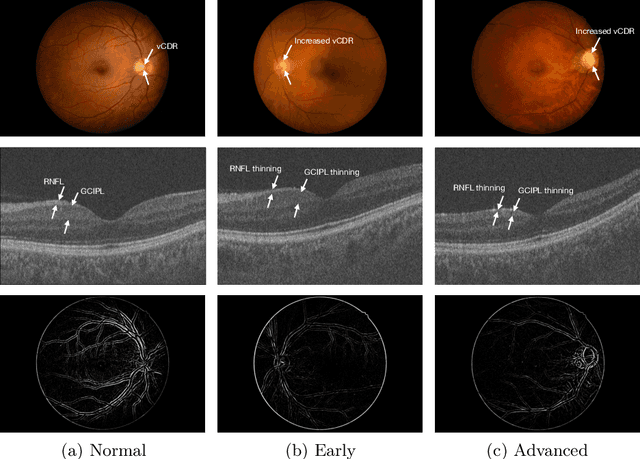

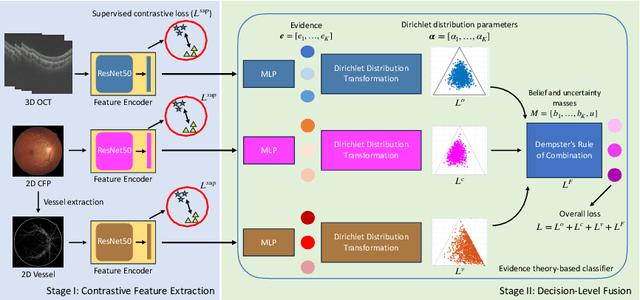
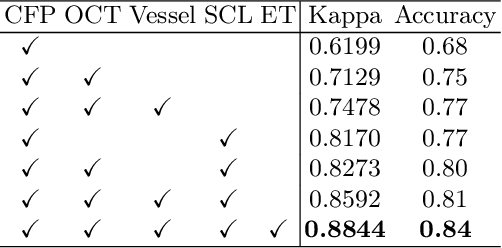
Glaucoma is one of the leading causes of vision impairment. Digital imaging techniques, such as color fundus photography (CFP) and optical coherence tomography (OCT), provide quantitative and noninvasive methods for glaucoma diagnosis. Recently, in the field of computer-aided glaucoma diagnosis, multi-modality methods that integrate the CFP and OCT modalities have achieved greater diagnostic accuracy compared to single-modality methods. However, it remains challenging to extract reliable features due to the high similarity of medical images and the unbalanced multi-modal data distribution. Moreover, existing methods overlook the uncertainty estimation of different modalities, leading to unreliable predictions. To address these challenges, we propose a novel framework, namely ETSCL, which consists of a contrastive feature extraction stage and a decision-level fusion stage. Specifically, the supervised contrastive loss is employed to enhance the discriminative power in the feature extraction process, resulting in more effective features. In addition, we utilize the Frangi vesselness algorithm as a preprocessing step to incorporate vessel information to assist in the prediction. In the decision-level fusion stage, an evidence theory-based multi-modality classifier is employed to combine multi-source information with uncertainty estimation. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The code is available at \url{https://github.com/master-Shix/ETSCL}.
Edge-guided and Cross-scale Feature Fusion Network for Efficient Multi-contrast MRI Super-Resolution
Jul 07, 2024



In recent years, MRI super-resolution techniques have achieved great success, especially multi-contrast methods that extract texture information from reference images to guide the super-resolution reconstruction. However, current methods primarily focus on texture similarities at the same scale, neglecting cross-scale similarities that provide comprehensive information. Moreover, the misalignment between features of different scales impedes effective aggregation of information flow. To address the limitations, we propose a novel edge-guided and cross-scale feature fusion network, namely ECFNet. Specifically, we develop a pipeline consisting of the deformable convolution and the cross-attention transformer to align features of different scales. The cross-scale fusion strategy fully integrates the texture information from different scales, significantly enhancing the super-resolution. In addition, a novel structure information collaboration module is developed to guide the super-resolution reconstruction with implicit structure priors. The structure information enables the network to focus on high-frequency components of the image, resulting in sharper details. Extensive experiments on the IXI and BraTS2020 datasets demonstrate that our method achieves state-of-the-art performance compared to other multi-contrast MRI super-resolution methods, and our method is robust in terms of different super-resolution scales. We would like to release our code and pre-trained model after the paper is accepted.
Revisiting Cephalometric Landmark Detection from the view of Human Pose Estimation with Lightweight Super-Resolution Head
Sep 29, 2023



Accurate localization of cephalometric landmarks holds great importance in the fields of orthodontics and orthognathics due to its potential for automating key point labeling. In the context of landmark detection, particularly in cephalometrics, it has been observed that existing methods often lack standardized pipelines and well-designed bias reduction processes, which significantly impact their performance. In this paper, we revisit a related task, human pose estimation (HPE), which shares numerous similarities with cephalometric landmark detection (CLD), and emphasize the potential for transferring techniques from the former field to benefit the latter. Motivated by this insight, we have developed a robust and adaptable benchmark based on the well-established HPE codebase known as MMPose. This benchmark can serve as a dependable baseline for achieving exceptional CLD performance. Furthermore, we introduce an upscaling design within the framework to further enhance performance. This enhancement involves the incorporation of a lightweight and efficient super-resolution module, which generates heatmap predictions on high-resolution features and leads to further performance refinement, benefiting from its ability to reduce quantization bias. In the MICCAI CLDetection2023 challenge, our method achieves 1st place ranking on three metrics and 3rd place on the remaining one. The code for our method is available at https://github.com/5k5000/CLdetection2023.
Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
Apr 18, 2022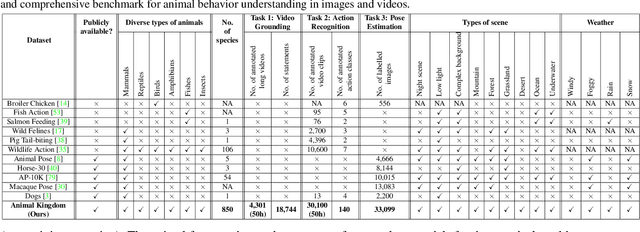
Understanding animals' behaviors is significant for a wide range of applications. However, existing animal behavior datasets have limitations in multiple aspects, including limited numbers of animal classes, data samples and provided tasks, and also limited variations in environmental conditions and viewpoints. To address these limitations, we create a large and diverse dataset, Animal Kingdom, that provides multiple annotated tasks to enable a more thorough understanding of natural animal behaviors. The wild animal footages used in our dataset record different times of the day in extensive range of environments containing variations in backgrounds, viewpoints, illumination and weather conditions. More specifically, our dataset contains 50 hours of annotated videos to localize relevant animal behavior segments in long videos for the video grounding task, 30K video sequences for the fine-grained multi-label action recognition task, and 33K frames for the pose estimation task, which correspond to a diverse range of animals with 850 species across 6 major animal classes. Such a challenging and comprehensive dataset shall be able to facilitate the community to develop, adapt, and evaluate various types of advanced methods for animal behavior analysis. Moreover, we propose a Collaborative Action Recognition (CARe) model that learns general and specific features for action recognition with unseen new animals. This method achieves promising performance in our experiments. Our dataset can be found at https://sutdcv.github.io/Animal-Kingdom.