 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Branch Subpixel-Guided Network for Hyperspectral Image Classification
Dec 05, 2024



Deep learning (DL) has been widely applied into hyperspectral image (HSI) classification owing to its promising feature learning and representation capabilities. However, limited by the spatial resolution of sensors, existing DL-based classification approaches mainly focus on pixel-level spectral and spatial information extraction through complex network architecture design, while ignoring the existence of mixed pixels in actual scenarios. To tackle this difficulty, we propose a novel dual-branch subpixel-guided network for HSI classification, called DSNet, which automatically integrates subpixel information and convolutional class features by introducing a deep autoencoder unmixing architecture to enhance classification performance. DSNet is capable of fully considering physically nonlinear properties within subpixels and adaptively generating diagnostic abundances in an unsupervised manner to achieve more reliable decision boundaries for class label distributions. The subpixel fusion module is designed to ensure high-quality information fusion across pixel and subpixel features, further promoting stable joint classification. Experimental results on three benchmark datasets demonstrate the effectiveness and superiority of DSNet compared with state-of-the-art DL-based HSI classification approaches. The codes will be available at https://github.com/hanzhu97702/DSNet, contributing to the remote sensing community.
Multisource Collaborative Domain Generalization for Cross-Scene Remote Sensing Image Classification
Dec 05, 2024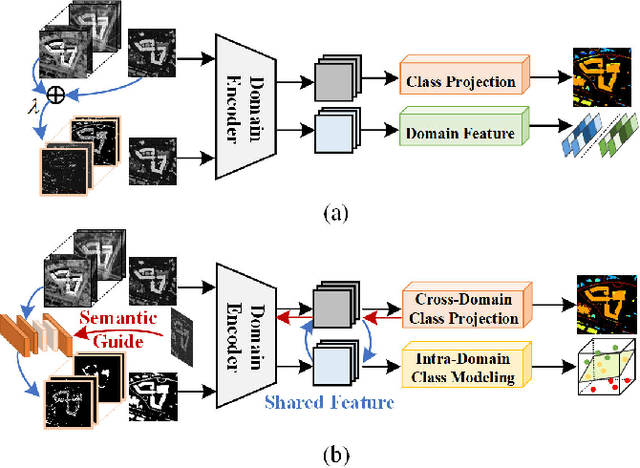

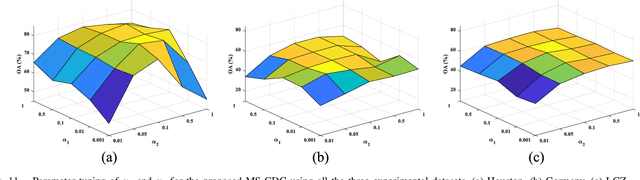
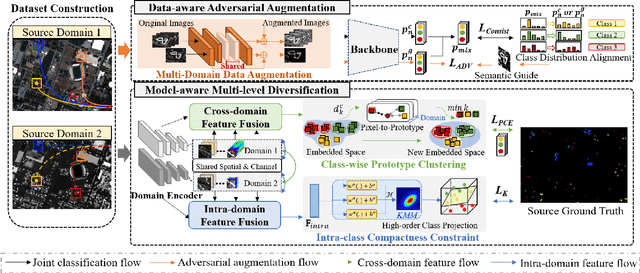
Cross-scene image classification aims to transfer prior knowledge of ground materials to annotate regions with different distributions and reduce hand-crafted cost in the field of remote sensing. However, existing approaches focus on single-source domain generalization to unseen target domains, and are easily confused by large real-world domain shifts due to the limited training information and insufficient diversity modeling capacity. To address this gap, we propose a novel multi-source collaborative domain generalization framework (MS-CDG) based on homogeneity and heterogeneity characteristics of multi-source remote sensing data, which considers data-aware adversarial augmentation and model-aware multi-level diversification simultaneously to enhance cross-scene generalization performance. The data-aware adversarial augmentation adopts an adversary neural network with semantic guide to generate MS samples by adaptively learning realistic channel and distribution changes across domains. In views of cross-domain and intra-domain modeling, the model-aware diversification transforms the shared spatial-channel features of MS data into the class-wise prototype and kernel mixture module, to address domain discrepancies and cluster different classes effectively. Finally, the joint classification of original and augmented MS samples is employed by introducing a distribution consistency alignment to increase model diversity and ensure better domain-invariant representation learning. Extensive experiments on three public MS remote sensing datasets demonstrate the superior performance of the proposed method when benchmarked with the state-of-the-art methods.
MNeRV: A Multilayer Neural Representation for Videos
Jul 10, 2024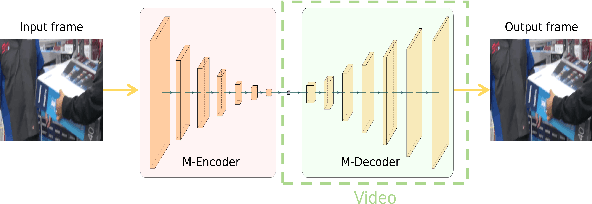
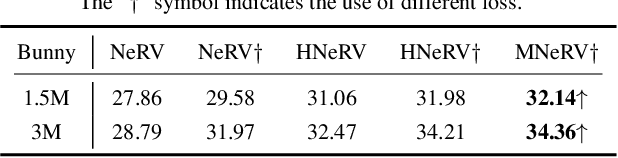
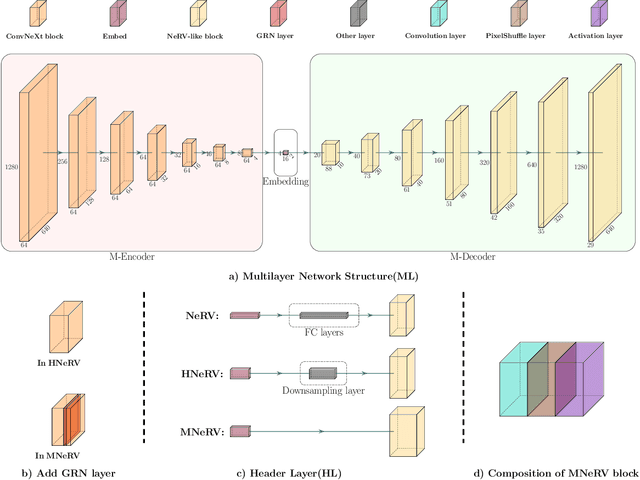
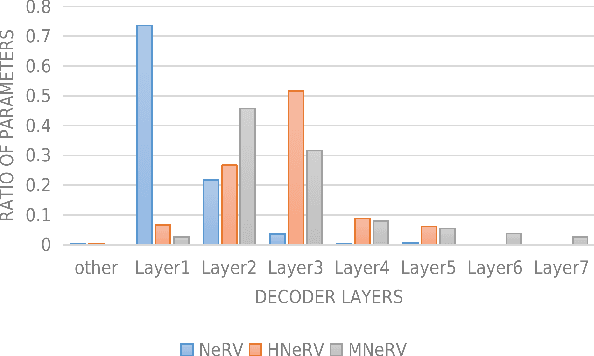
As a novel video representation method, Neural Representations for Videos (NeRV) has shown great potential in the fields of video compression, video restoration, and video interpolation. In the process of representing videos using NeRV, each frame corresponds to an embedding, which is then reconstructed into a video frame sequence after passing through a small number of decoding layers (E-NeRV, HNeRV, etc.). However, this small number of decoding layers can easily lead to the problem of redundant model parameters due to the large proportion of parameters in a single decoding layer, which greatly restricts the video regression ability of neural network models. In this paper, we propose a multilayer neural representation for videos (MNeRV) and design a new decoder M-Decoder and its matching encoder M-Encoder. MNeRV has more encoding and decoding layers, which effectively alleviates the problem of redundant model parameters caused by too few layers. In addition, we design MNeRV blocks to perform more uniform and effective parameter allocation between decoding layers. In the field of video regression reconstruction, we achieve better reconstruction quality (+4.06 PSNR) with fewer parameters. Finally, we showcase MNeRV performance in downstream tasks such as video restoration and video interpolation. The source code of MNeRV is available at https://github.com/Aaronbtb/MNeRV.
Edge-guided and Cross-scale Feature Fusion Network for Efficient Multi-contrast MRI Super-Resolution
Jul 07, 2024



In recent years, MRI super-resolution techniques have achieved great success, especially multi-contrast methods that extract texture information from reference images to guide the super-resolution reconstruction. However, current methods primarily focus on texture similarities at the same scale, neglecting cross-scale similarities that provide comprehensive information. Moreover, the misalignment between features of different scales impedes effective aggregation of information flow. To address the limitations, we propose a novel edge-guided and cross-scale feature fusion network, namely ECFNet. Specifically, we develop a pipeline consisting of the deformable convolution and the cross-attention transformer to align features of different scales. The cross-scale fusion strategy fully integrates the texture information from different scales, significantly enhancing the super-resolution. In addition, a novel structure information collaboration module is developed to guide the super-resolution reconstruction with implicit structure priors. The structure information enables the network to focus on high-frequency components of the image, resulting in sharper details. Extensive experiments on the IXI and BraTS2020 datasets demonstrate that our method achieves state-of-the-art performance compared to other multi-contrast MRI super-resolution methods, and our method is robust in terms of different super-resolution scales. We would like to release our code and pre-trained model after the paper is accepted.
Progressive Local Filter Pruning for Image Retrieval Acceleration
Jan 24, 2020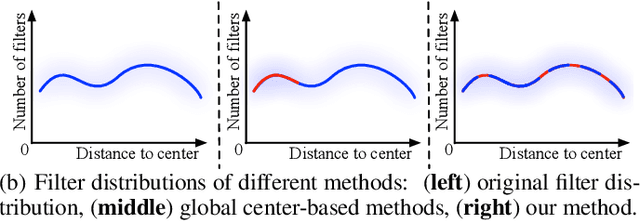
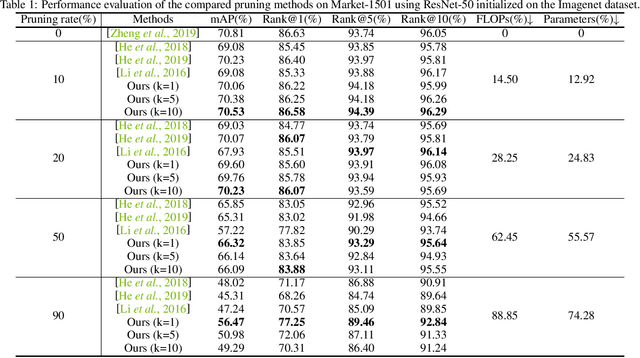
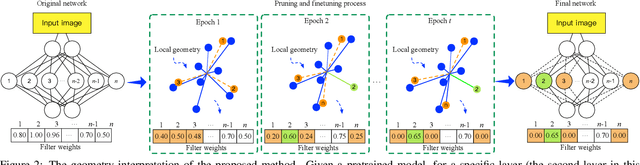
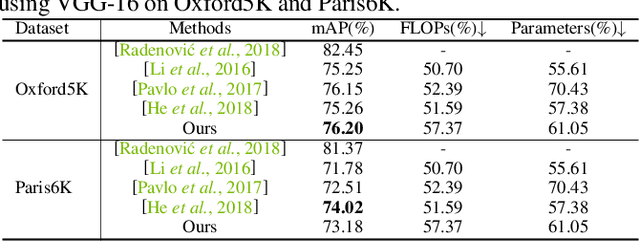
This paper focuses on network pruning for image retrieval acceleration. Prevailing image retrieval works target at the discriminative feature learning, while little attention is paid to how to accelerate the model inference, which should be taken into consideration in real-world practice. The challenge of pruning image retrieval models is that the middle-level feature should be preserved as much as possible. Such different requirements of the retrieval and classification model make the traditional pruning methods not that suitable for our task. To solve the problem, we propose a new Progressive Local Filter Pruning (PLFP) method for image retrieval acceleration. Specifically, layer by layer, we analyze the local geometric properties of each filter and select the one that can be replaced by the neighbors. Then we progressively prune the filter by gradually changing the filter weights. In this way, the representation ability of the model is preserved. To verify this, we evaluate our method on two widely-used image retrieval datasets,i.e., Oxford5k and Paris6K, and one person re-identification dataset,i.e., Market-1501. The proposed method arrives with superior performance to the conventional pruning methods, suggesting the effectiveness of the proposed method for image retrieval.