 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalM$2$: An Extremely Lightweight Saliency Mamba Model for Real-Time Cognitive Awareness of Driver Attention
Feb 22, 2025



Driver attention recognition in driving scenarios is a popular direction in traffic scene perception technology. It aims to understand human driver attention to focus on specific targets/objects in the driving scene. However, traffic scenes contain not only a large amount of visual information but also semantic information related to driving tasks. Existing methods lack attention to the actual semantic information present in driving scenes. Additionally, the traffic scene is a complex and dynamic process that requires constant attention to objects related to the current driving task. Existing models, influenced by their foundational frameworks, tend to have large parameter counts and complex structures. Therefore, this paper proposes a real-time saliency Mamba network based on the latest Mamba framework. As shown in Figure 1, our model uses very few parameters (0.08M, only 0.09~11.16% of other models), while maintaining SOTA performance or achieving over 98% of the SOTA model's performance.
Adaptive Frequency Enhancement Network for Single Image Deraining
Jul 19, 2024Image deraining aims to improve the visibility of images damaged by rainy conditions, targeting the removal of degradation elements such as rain streaks, raindrops, and rain accumulation. While numerous single image deraining methods have shown promising results in image enhancement within the spatial domain, real-world rain degradation often causes uneven damage across an image's entire frequency spectrum, posing challenges for these methods in enhancing different frequency components. In this paper, we introduce a novel end-to-end Adaptive Frequency Enhancement Network (AFENet) specifically for single image deraining that adaptively enhances images across various frequencies. We employ convolutions of different scales to adaptively decompose image frequency bands, introduce a feature enhancement module to boost the features of different frequency components and present a novel interaction module for interchanging and merging information from various frequency branches. Simultaneously, we propose a feature aggregation module that efficiently and adaptively fuses features from different frequency bands, facilitating enhancements across the entire frequency spectrum. This approach empowers the deraining network to eliminate diverse and complex rainy patterns and to reconstruct image details accurately. Extensive experiments on both real and synthetic scenes demonstrate that our method not only achieves visually appealing enhancement results but also surpasses existing methods in performance.
First Mapping the Canopy Height of Primeval Forests in the Tallest Tree Area of Asia
Apr 23, 2024



We have developed the world's first canopy height map of the distribution area of world-level giant trees. This mapping is crucial for discovering more individual and community world-level giant trees, and for analyzing and quantifying the effectiveness of biodiversity conservation measures in the Yarlung Tsangpo Grand Canyon (YTGC) National Nature Reserve. We proposed a method to map the canopy height of the primeval forest within the world-level giant tree distribution area by using a spaceborne LiDAR fusion satellite imagery (Global Ecosystem Dynamics Investigation (GEDI), ICESat-2, and Sentinel-2) driven deep learning modeling. And we customized a pyramid receptive fields depth separable CNN (PRFXception). PRFXception, a CNN architecture specifically customized for mapping primeval forest canopy height to infer the canopy height at the footprint level of GEDI and ICESat-2 from Sentinel-2 optical imagery with a 10-meter spatial resolution. We conducted a field survey of 227 permanent plots using a stratified sampling method and measured several giant trees using UAV-LS. The predicted canopy height was compared with ICESat-2 and GEDI validation data (RMSE =7.56 m, MAE=6.07 m, ME=-0.98 m, R^2=0.58 m), UAV-LS point clouds (RMSE =5.75 m, MAE =3.72 m, ME = 0.82 m, R^2= 0.65 m), and ground survey data (RMSE = 6.75 m, MAE = 5.56 m, ME= 2.14 m, R^2=0.60 m). We mapped the potential distribution map of world-level giant trees and discovered two previously undetected giant tree communities with an 89% probability of having trees 80-100 m tall, potentially taller than Asia's tallest tree. This paper provides scientific evidence confirming southeastern Tibet--northwestern Yunnan as the fourth global distribution center of world-level giant trees initiatives and promoting the inclusion of the YTGC giant tree distribution area within the scope of China's national park conservation.
Lane detection in complex scenes based on end-to-end neural network
Oct 26, 2020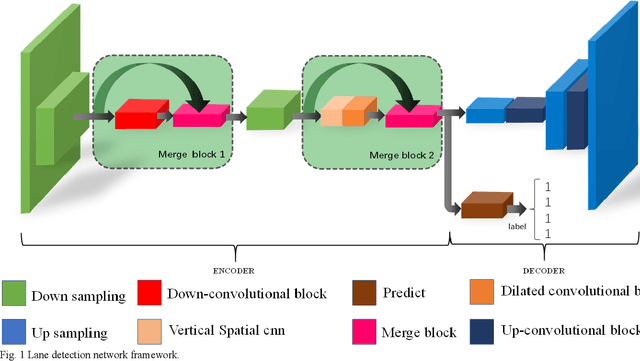
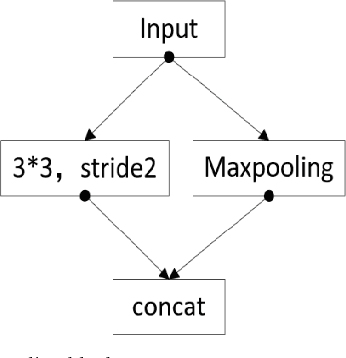
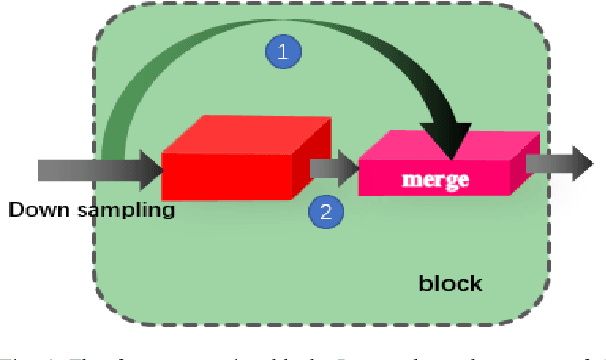

The lane detection is a key problem to solve the division of derivable areas in unmanned driving, and the detection accuracy of lane lines plays an important role in the decision-making of vehicle driving. Scenes faced by vehicles in daily driving are relatively complex. Bright light, insufficient light, and crowded vehicles will bring varying degrees of difficulty to lane detection. So we combine the advantages of spatial convolution in spatial information processing and the efficiency of ERFNet in semantic segmentation, propose an end-to-end network to lane detection in a variety of complex scenes. And we design the information exchange block by combining spatial convolution and dilated convolution, which plays a great role in understanding detailed information. Finally, our network was tested on the CULane database and its F1-measure with IOU threshold of 0.5 can reach 71.9%.
Lane Detection Model Based on Spatio-Temporal Network with Double ConvGRUs
Aug 10, 2020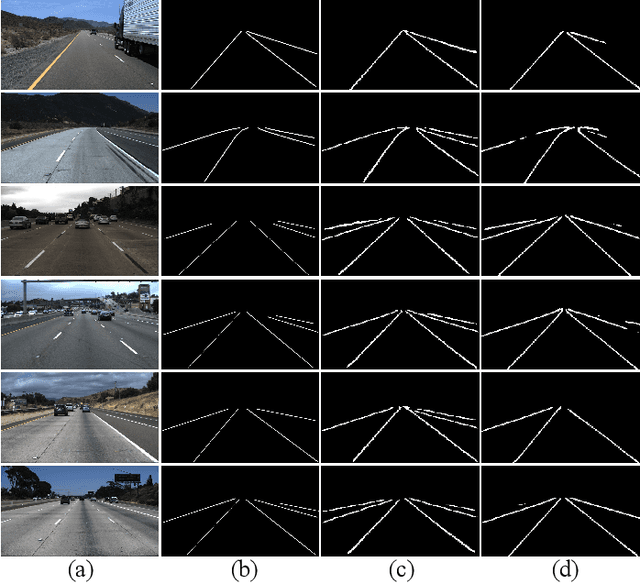
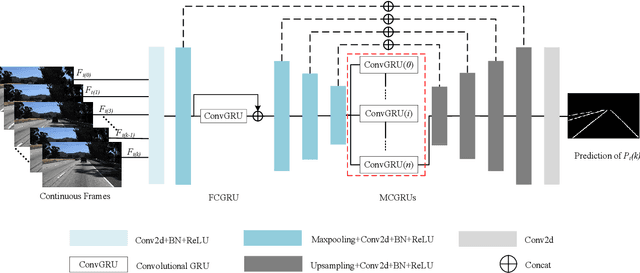
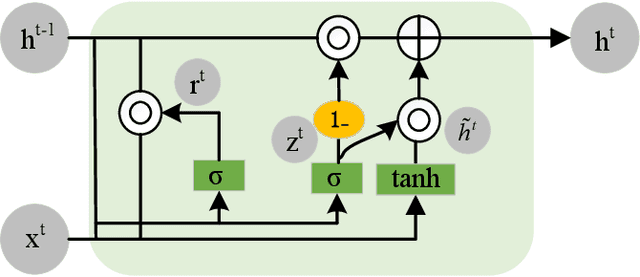
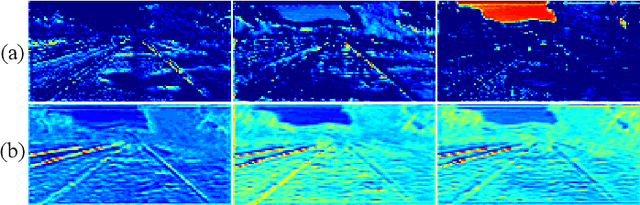
Lane detection is one of the indispensable and key elements of self-driving environmental perception. Many lane detection models have been proposed, solving lane detection under challenging conditions, including intersection merging and splitting, curves, boundaries, occlusions and combinations of scene types. Nevertheless, lane detection will remain an open problem for some time to come. The ability to cope well with those challenging scenes impacts greatly the applications of lane detection on advanced driver assistance systems (ADASs). In this paper, a spatio-temporal network with double Convolutional Gated Recurrent Units (ConvGRUs) is proposed to address lane detection in challenging scenes. Both of ConvGRUs have the same structures, but different locations and functions in our network. One is used to extract the information of the most likely low-level features of lane markings. The extracted features are input into the next layer of the end-to-end network after concatenating them with the outputs of some blocks. The other one takes some continuous frames as its input to process the spatio-temporal driving information. Extensive experiments on the large-scale Tusimple lane marking challenge dataset and Unsupervised LLAMAS dataset demonstrate that the proposed model can effectively detect lanes in the challenging driving scenes. Our model can outperform the state-of-the-art lane detection models.
A Critical and Moving-Forward View on Quantum Image Processing
Jun 15, 2020
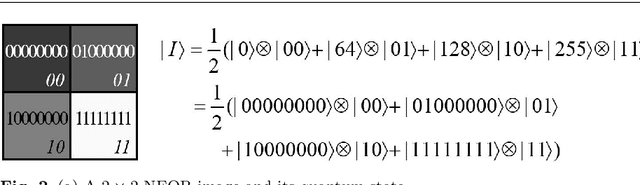


Physics and computer science have a long tradition of cross-fertilization. One of the latest outcomes of this mutually beneficial relationship is quantum information science, which comprises the study of information processing tasks that can be accomplished using quantum mechanical systems. Quantum Image Processing (QIMP) is an emergent field of quantum information science whose main goal is to strengthen our capacity for storing, processing, and retrieving visual information from images and video either by transitioning from digital to quantum paradigms or by complementing digital imaging with quantum techniques. The expectation is that harnessing the properties of quantum mechanical systems in QIMP will result in the realization of advanced technologies that will outperform, enhance or complement existing and upcoming digital technologies for image and video processing tasks.
A Convolutional Baseline for Person Re-Identification Using Vision and Language Descriptions
Feb 20, 2020

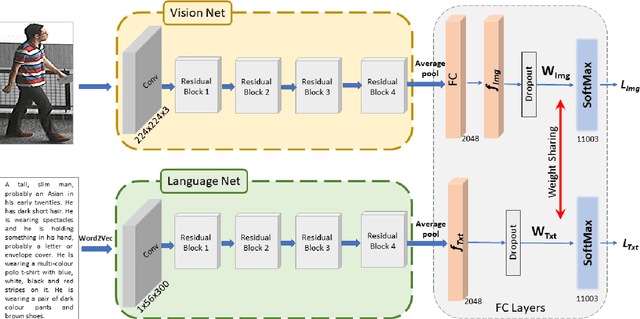

Classical person re-identification approaches assume that a person of interest has appeared across different cameras and can be queried by one of the existing images. However, in real-world surveillance scenarios, frequently no visual information will be available about the queried person. In such scenarios, a natural language description of the person by a witness will provide the only source of information for retrieval. In this work, person re-identification using both vision and language information is addressed under all possible gallery and query scenarios. A two stream deep convolutional neural network framework supervised by cross entropy loss is presented. The weights connecting the second last layer to the last layer with class probabilities, i.e., logits of softmax layer are shared in both networks. Canonical Correlation Analysis is performed to enhance the correlation between the two modalities in a joint latent embedding space. To investigate the benefits of the proposed approach, a new testing protocol under a multi modal ReID setting is proposed for the test split of the CUHK-PEDES and CUHK-SYSU benchmarks. The experimental results verify the merits of the proposed system. The learnt visual representations are more robust and perform 22\% better during retrieval as compared to a single modality system. The retrieval with a multi modal query greatly enhances the re-identification capability of the system quantitatively as well as qualitatively.
Progressive Local Filter Pruning for Image Retrieval Acceleration
Jan 24, 2020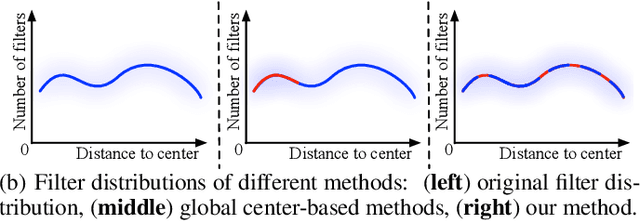
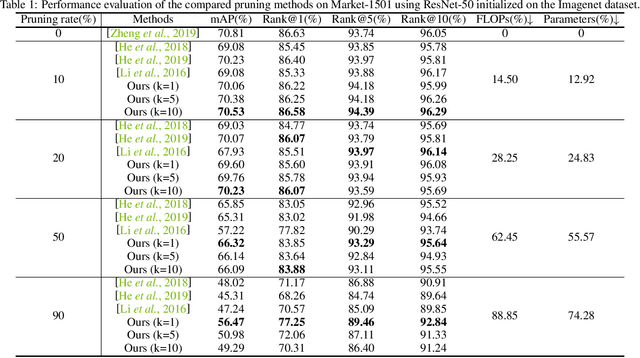
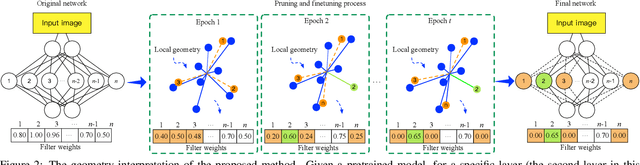
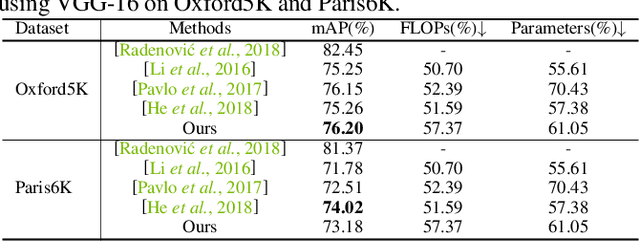
This paper focuses on network pruning for image retrieval acceleration. Prevailing image retrieval works target at the discriminative feature learning, while little attention is paid to how to accelerate the model inference, which should be taken into consideration in real-world practice. The challenge of pruning image retrieval models is that the middle-level feature should be preserved as much as possible. Such different requirements of the retrieval and classification model make the traditional pruning methods not that suitable for our task. To solve the problem, we propose a new Progressive Local Filter Pruning (PLFP) method for image retrieval acceleration. Specifically, layer by layer, we analyze the local geometric properties of each filter and select the one that can be replaced by the neighbors. Then we progressively prune the filter by gradually changing the filter weights. In this way, the representation ability of the model is preserved. To verify this, we evaluate our method on two widely-used image retrieval datasets,i.e., Oxford5k and Paris6K, and one person re-identification dataset,i.e., Market-1501. The proposed method arrives with superior performance to the conventional pruning methods, suggesting the effectiveness of the proposed method for image retrieval.
Person Re-Identification with Vision and Language
Oct 03, 2017
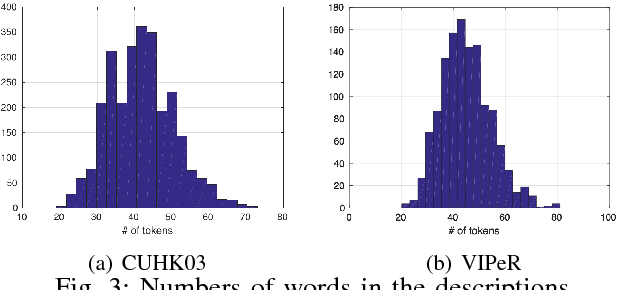

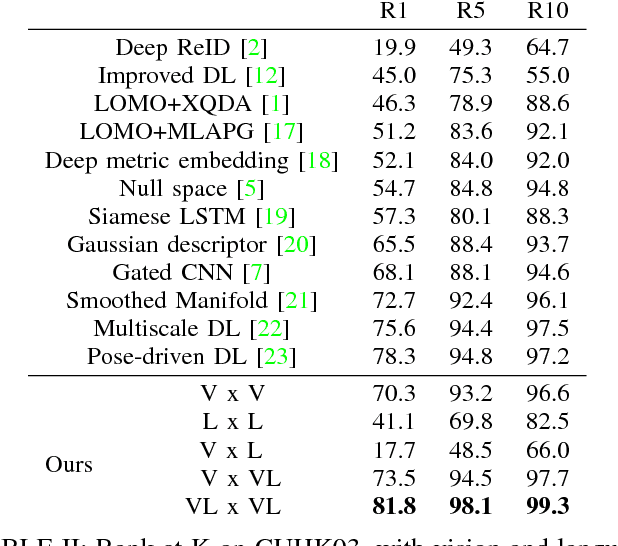
In this paper we propose a new approach to person re-identification using images and natural language descriptions. We propose a joint vision and language model based on CCA and CNN architectures to match across the two modalities as well as to enrich visual examples for which there are no language descriptions. We also introduce new annotations in the form of natural language descriptions for two standard Re-ID benchmarks, namely CUHK03 and VIPeR. We perform experiments on these two datasets with techniques based on CNN, hand-crafted features as well as LSTM for analysing visual and natural description data. We investigate and demonstrate the advantages of using natural language descriptions compared to attributes as well as CNN compared to LSTM in the context of Re-ID. We show that the joint use of language and vision can significantly improve the state-of-the-art performance on standard Re-ID benchmarks.
BreakingNews: Article Annotation by Image and Text Processing
Mar 23, 2016
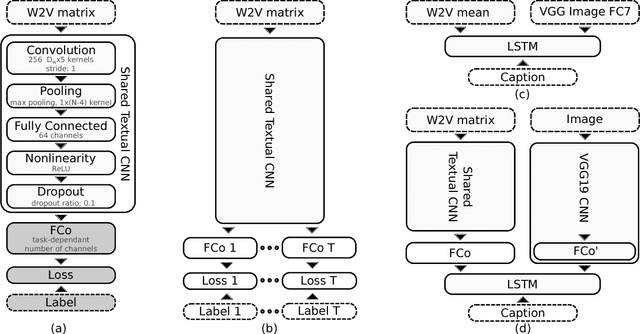

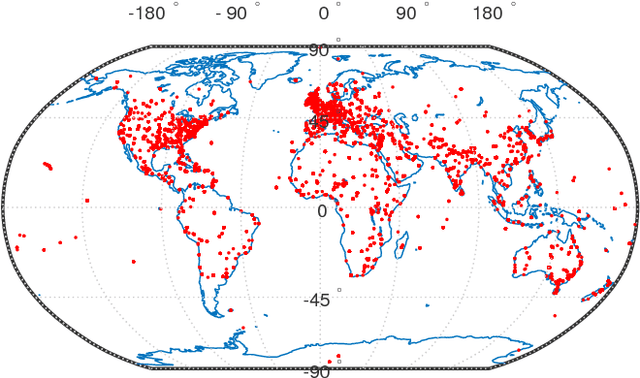
Building upon recent Deep Neural Network architectures, current approaches lying in the intersection of computer vision and natural language processing have achieved unprecedented breakthroughs in tasks like automatic captioning or image retrieval. Most of these learning methods, though, rely on large training sets of images associated with human annotations that specifically describe the visual content. In this paper we propose to go a step further and explore the more complex cases where textual descriptions are loosely related to the images. We focus on the particular domain of News articles in which the textual content often expresses connotative and ambiguous relations that are only suggested but not directly inferred from images. We introduce new deep learning methods that address source detection, popularity prediction, article illustration and geolocation of articles. An adaptive CNN architecture is proposed, that shares most of the structure for all the tasks, and is suitable for multitask and transfer learning. Deep Canonical Correlation Analysis is deployed for article illustration, and a new loss function based on Great Circle Distance is proposed for geolocation. Furthermore, we present BreakingNews, a novel dataset with approximately 100K news articles including images, text and captions, and enriched with heterogeneous meta-data (such as GPS coordinates and popularity metrics). We show this dataset to be appropriate to explore all aforementioned problems, for which we provide a baseline performance using various Deep Learning architectures, and different representations of the textual and visual features. We report very promising results and bring to light several limitations of current state-of-the-art in this kind of domain, which we hope will help spur progress in the field.