 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-SSL0.0: Towards Multi-Concept Self-Supervised Learning
Nov 30, 2021
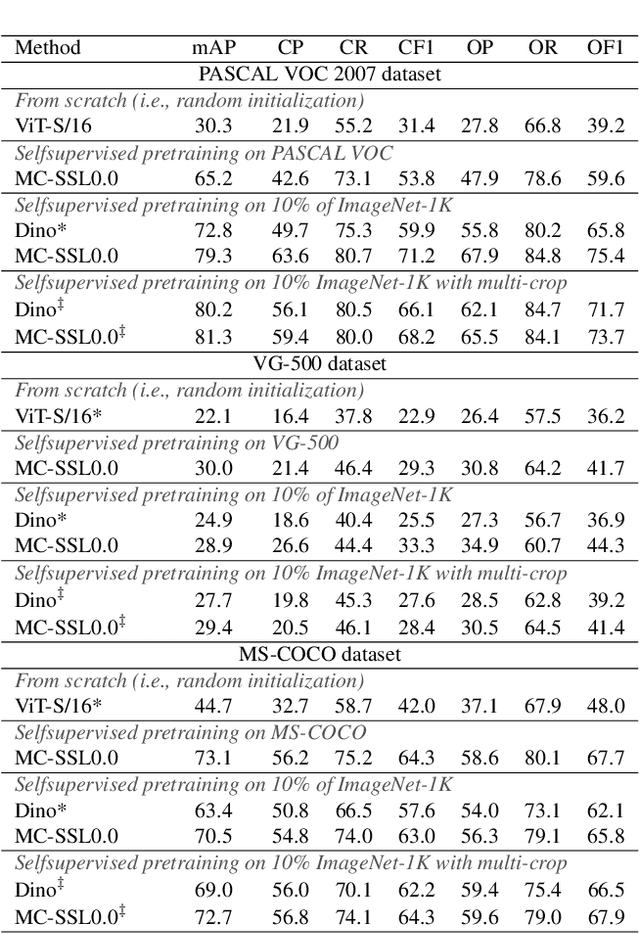
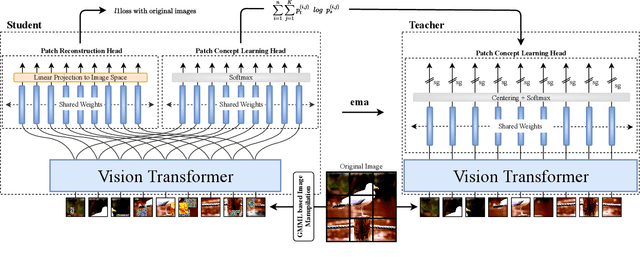
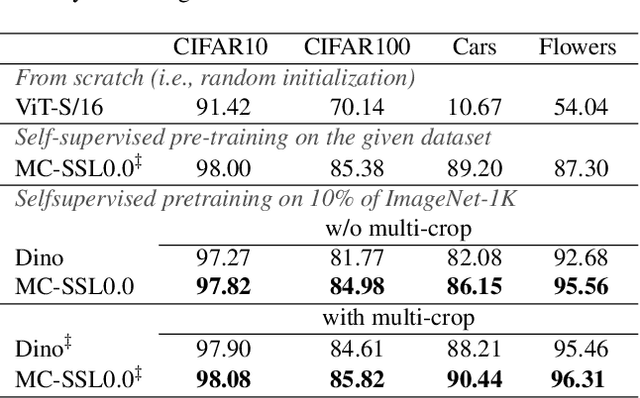
Self-supervised pretraining is the method of choice for natural language processing models and is rapidly gaining popularity in many vision tasks. Recently, self-supervised pretraining has shown to outperform supervised pretraining for many downstream vision applications, marking a milestone in the area. This superiority is attributed to the negative impact of incomplete labelling of the training images, which convey multiple concepts, but are annotated using a single dominant class label. Although Self-Supervised Learning (SSL), in principle, is free of this limitation, the choice of pretext task facilitating SSL is perpetuating this shortcoming by driving the learning process towards a single concept output. This study aims to investigate the possibility of modelling all the concepts present in an image without using labels. In this aspect the proposed SSL frame-work MC-SSL0.0 is a step towards Multi-Concept Self-Supervised Learning (MC-SSL) that goes beyond modelling single dominant label in an image to effectively utilise the information from all the concepts present in it. MC-SSL0.0 consists of two core design concepts, group masked model learning and learning of pseudo-concept for data token using a momentum encoder (teacher-student) framework. The experimental results on multi-label and multi-class image classification downstream tasks demonstrate that MC-SSL0.0 not only surpasses existing SSL methods but also outperforms supervised transfer learning. The source code will be made publicly available for community to train on bigger corpus.
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021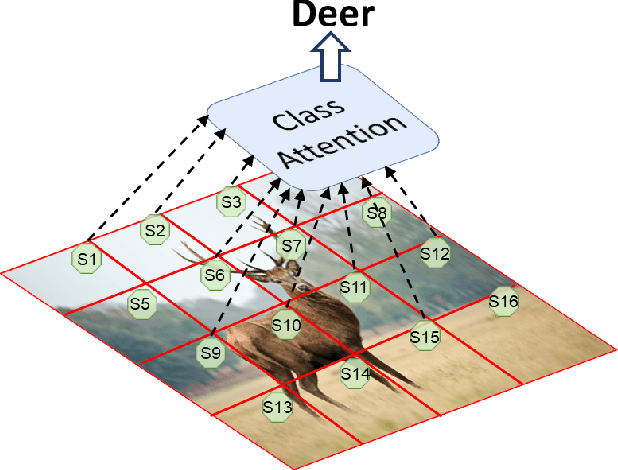
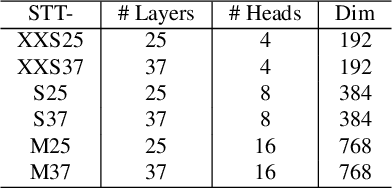
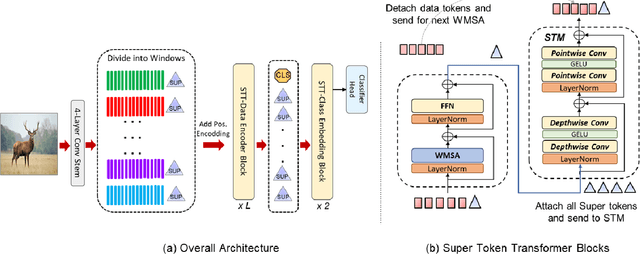
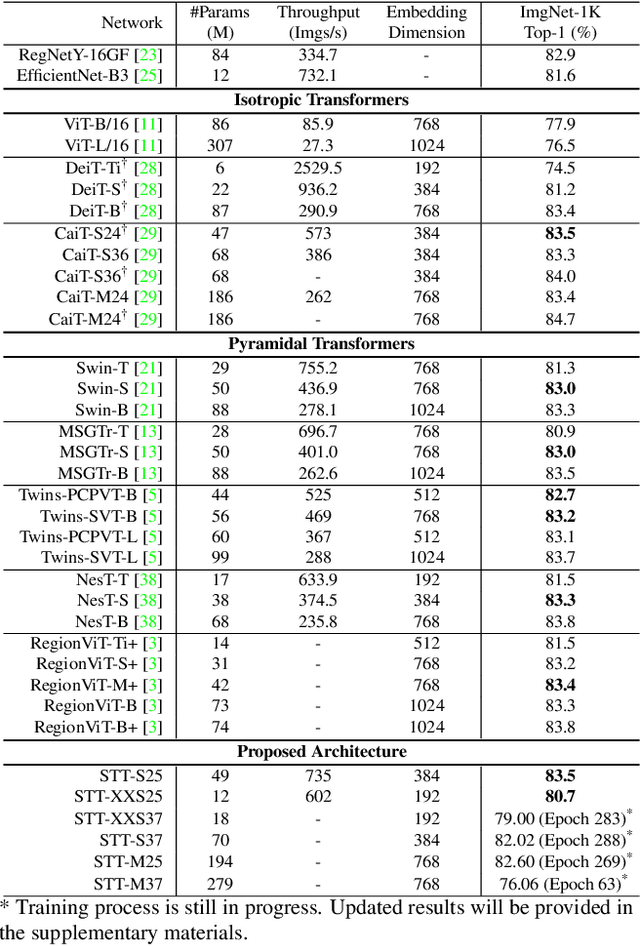
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
NPT-Loss: A Metric Loss with Implicit Mining for Face Recognition
Mar 05, 2021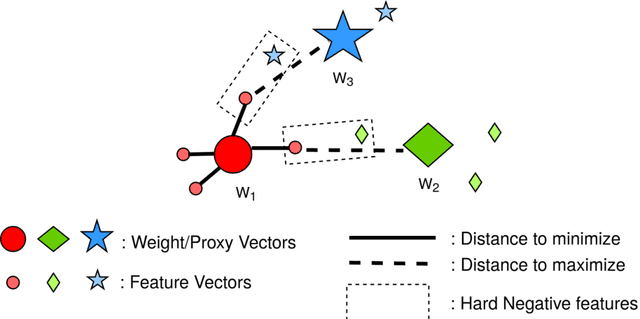

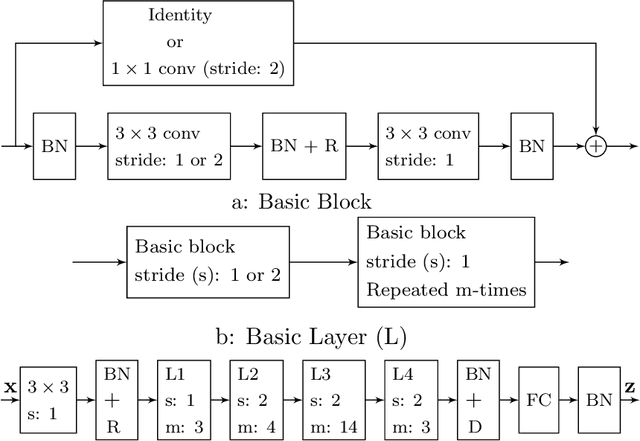
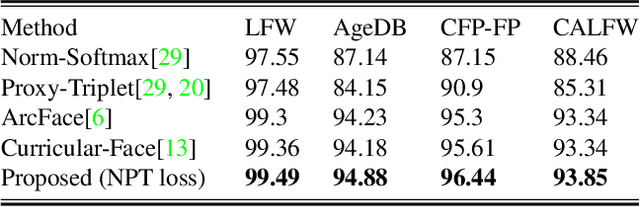
Face recognition (FR) using deep convolutional neural networks (DCNNs) has seen remarkable success in recent years. One key ingredient of DCNN-based FR is the appropriate design of a loss function that ensures discrimination between various identities. The state-of-the-art (SOTA) solutions utilise normalised Softmax loss with additive and/or multiplicative margins. Despite being popular, these Softmax+margin based losses are not theoretically motivated and the effectiveness of a margin is justified only intuitively. In this work, we utilise an alternative framework that offers a more direct mechanism of achieving discrimination among the features of various identities. We propose a novel loss that is equivalent to a triplet loss with proxies and an implicit mechanism of hard-negative mining. We give theoretical justification that minimising the proposed loss ensures a minimum separability between all identities. The proposed loss is simple to implement and does not require heavy hyper-parameter tuning as in the SOTA solutions. We give empirical evidence that despite its simplicity, the proposed loss consistently achieves SOTA performance in various benchmarks for both high-resolution and low-resolution FR tasks.
AXM-Net: Cross-Modal Context Sharing Attention Network for Person Re-ID
Jan 19, 2021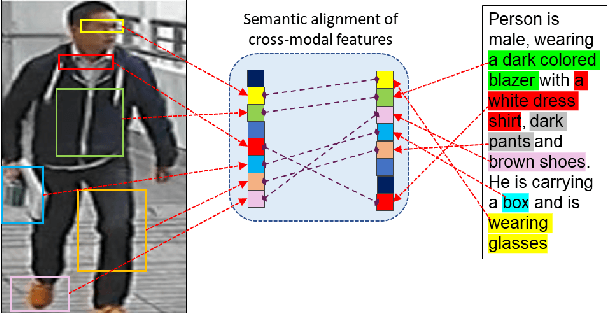
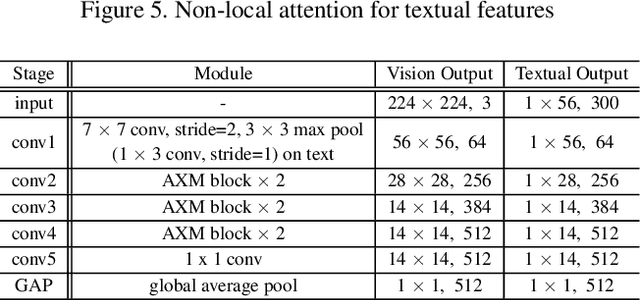
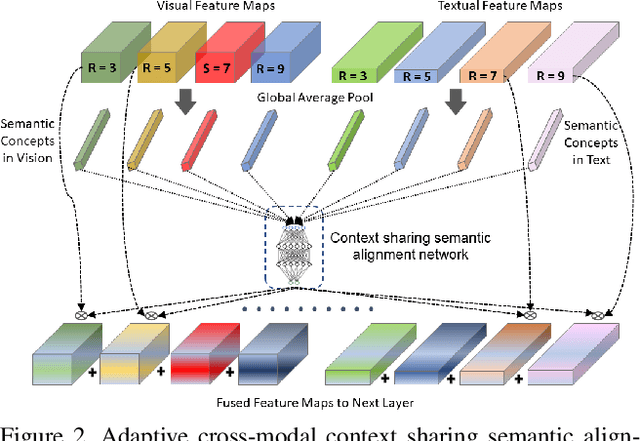
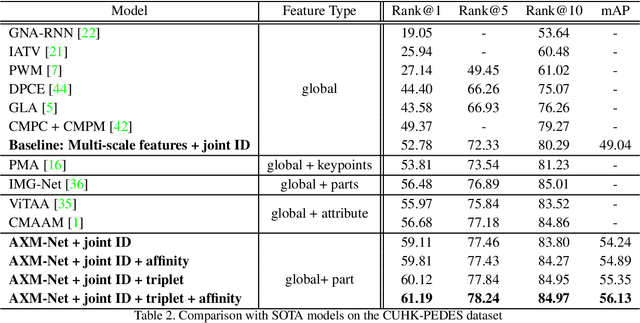
Cross-modal person re-identification (Re-ID) is critical for modern video surveillance systems. The key challenge is to align inter-modality representations according to semantic information present for a person and ignore background information. In this work, we present AXM-Net, a novel CNN based architecture designed for learning semantically aligned visual and textual representations. The underlying building block consists of multiple streams of feature maps coming from visual and textual modalities and a novel learnable context sharing semantic alignment network. We also propose complementary intra modal attention learning mechanisms to focus on more fine-grained local details in the features along with a cross-modal affinity loss for robust feature matching. Our design is unique in its ability to implicitly learn feature alignments from data. The entire AXM-Net can be trained in an end-to-end manner. We report results on both person search and cross-modal Re-ID tasks. Extensive experimentation validates the proposed framework and demonstrates its superiority by outperforming the current state-of-the-art methods by a significant margin.
A Flatter Loss for Bias Mitigation in Cross-dataset Facial Age Estimation
Oct 26, 2020
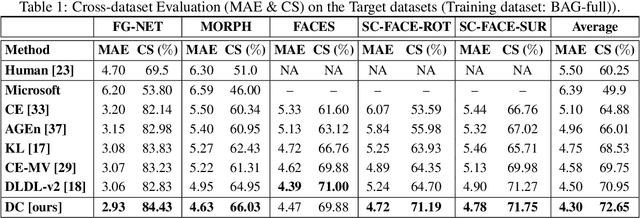
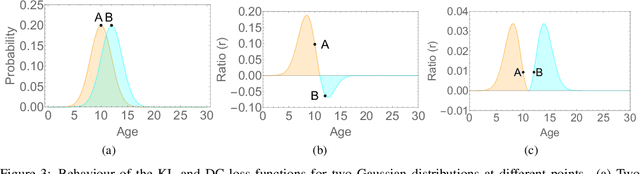
The most existing studies in the facial age estimation assume training and test images are captured under similar shooting conditions. However, this is rarely valid in real-world applications, where training and test sets usually have different characteristics. In this paper, we advocate a cross-dataset protocol for age estimation benchmarking. In order to improve the cross-dataset age estimation performance, we mitigate the inherent bias caused by the learning algorithm itself. To this end, we propose a novel loss function that is more effective for neural network training. The relative smoothness of the proposed loss function is its advantage with regards to the optimisation process performed by stochastic gradient descent (SGD). Compared with existing loss functions, the lower gradient of the proposed loss function leads to the convergence of SGD to a better optimum point, and consequently a better generalisation. The cross-dataset experimental results demonstrate the superiority of the proposed method over the state-of-the-art algorithms in terms of accuracy and generalisation capability.
A Convolutional Baseline for Person Re-Identification Using Vision and Language Descriptions
Feb 20, 2020

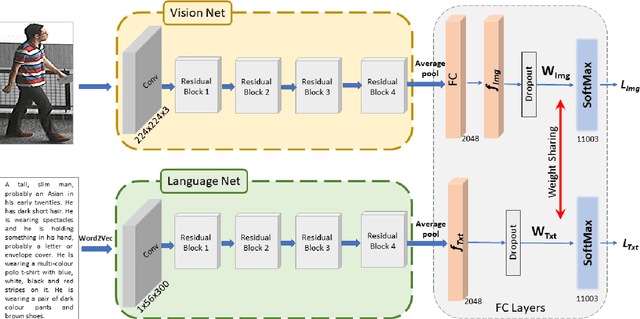

Classical person re-identification approaches assume that a person of interest has appeared across different cameras and can be queried by one of the existing images. However, in real-world surveillance scenarios, frequently no visual information will be available about the queried person. In such scenarios, a natural language description of the person by a witness will provide the only source of information for retrieval. In this work, person re-identification using both vision and language information is addressed under all possible gallery and query scenarios. A two stream deep convolutional neural network framework supervised by cross entropy loss is presented. The weights connecting the second last layer to the last layer with class probabilities, i.e., logits of softmax layer are shared in both networks. Canonical Correlation Analysis is performed to enhance the correlation between the two modalities in a joint latent embedding space. To investigate the benefits of the proposed approach, a new testing protocol under a multi modal ReID setting is proposed for the test split of the CUHK-PEDES and CUHK-SYSU benchmarks. The experimental results verify the merits of the proposed system. The learnt visual representations are more robust and perform 22\% better during retrieval as compared to a single modality system. The retrieval with a multi modal query greatly enhances the re-identification capability of the system quantitatively as well as qualitatively.