 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Stage Value-Guided Inference with Margin-Based Reward Adjustment for Fast and Faithful VLM Captioning
Jun 18, 2025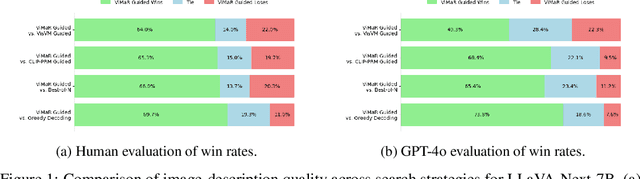
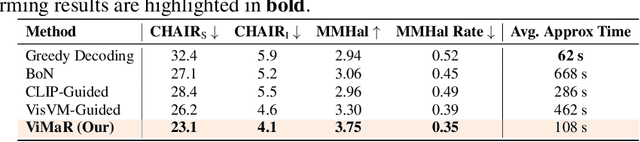
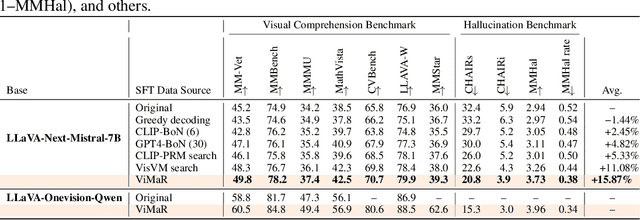

Despite significant advances in inference-time search for vision-language models (VLMs), existing approaches remain both computationally expensive and prone to unpenalized, low-confidence generations which often lead to persistent hallucinations. We introduce \textbf{Value-guided Inference with Margin-based Reward (ViMaR)}, a two-stage inference framework that improves both efficiency and output fidelity by combining a temporal-difference value model with a margin-aware reward adjustment. In the first stage, we perform a single pass to identify the highest-value caption among diverse candidates. In the second stage, we selectively refine only those segments that were overlooked or exhibit weak visual grounding, thereby eliminating frequently rewarded evaluations. A calibrated margin-based penalty discourages low-confidence continuations while preserving descriptive richness. Extensive experiments across multiple VLM architectures demonstrate that ViMaR generates captions that are significantly more reliable, factually accurate, detailed, and explanatory, while achieving over 4$\times$ speedup compared to existing value-guided methods. Specifically, we show that ViMaR trained solely on LLaVA Mistral-7B, \textit{generalizes effectively to guide decoding in a stronger unseen model}. To further validate this, we adapt the ViMaR to steer generation in LLaVA-OneVision-Qwen2-7B, leading to consistent improvements in caption quality and demonstrating robust cross-model guidance. This cross-model generalization highlights ViMaR's flexibility and modularity, positioning it as a scalable and transferable inference-time decoding strategy. Furthermore, when ViMaR-generated captions are used for self-training, the underlying models achieve substantial gains across a broad suite of visual comprehension benchmarks, underscoring the potential of fast, accurate, and self-improving VLM pipelines.
PAL: Probing Audio Encoders via LLMs -- A Study of Information Transfer from Audio Encoders to LLMs
Jun 12, 2025The integration of audio perception capabilities into Large Language Models (LLMs) has enabled significant advances in Audio-LLMs. Although application-focused developments, particularly in curating training data for specific capabilities e.g., audio reasoning, have progressed rapidly, the underlying mechanisms that govern efficient transfer of rich semantic representations from audio encoders to LLMs remain under-explored. We conceptualize effective audio-LLM interaction as the LLM's ability to proficiently probe the audio encoder representations to satisfy textual queries. This paper presents a systematic investigation on how architectural design choices can affect that. Beginning with a standard Pengi/LLaVA-style audio-LLM architecture, we propose and evaluate several modifications guided by hypotheses derived from mechanistic interpretability studies and LLM operational principles. Our experiments demonstrate that: (1) delaying audio integration until the LLM's initial layers establish textual context that enhances its ability to probe the audio representations for relevant information; (2) the LLM can proficiently probe audio representations exclusively through LLM layer's attention submodule, without requiring propagation to its Feed-Forward Network (FFN) submodule; (3) an efficiently integrated ensemble of diverse audio encoders provides richer, complementary representations, thereby broadening the LLM's capacity to probe a wider spectrum of audio information. All hypotheses are evaluated using an identical three-stage training curriculum on a dataset of 5.6 million audio-text pairs, ensuring controlled comparisons. Our final architecture, which incorporates all proposed modifications, achieves relative improvements from 10\% to 60\% over the baseline, validating our approach to optimizing cross-modal information transfer in audio-LLMs. Project page: https://ta012.github.io/PAL/
DeepChest: Dynamic Gradient-Free Task Weighting for Effective Multi-Task Learning in Chest X-ray Classification
May 29, 2025While Multi-Task Learning (MTL) offers inherent advantages in complex domains such as medical imaging by enabling shared representation learning, effectively balancing task contributions remains a significant challenge. This paper addresses this critical issue by introducing DeepChest, a novel, computationally efficient and effective dynamic task-weighting framework specifically designed for multi-label chest X-ray (CXR) classification. Unlike existing heuristic or gradient-based methods that often incur substantial overhead, DeepChest leverages a performance-driven weighting mechanism based on effective analysis of task-specific loss trends. Given a network architecture (e.g., ResNet18), our model-agnostic approach adaptively adjusts task importance without requiring gradient access, thereby significantly reducing memory usage and achieving a threefold increase in training speed. It can be easily applied to improve various state-of-the-art methods. Extensive experiments on a large-scale CXR dataset demonstrate that DeepChest not only outperforms state-of-the-art MTL methods by 7% in overall accuracy but also yields substantial reductions in individual task losses, indicating improved generalization and effective mitigation of negative transfer. The efficiency and performance gains of DeepChest pave the way for more practical and robust deployment of deep learning in critical medical diagnostic applications. The code is publicly available at https://github.com/youssefkhalil320/DeepChest-MTL
C3R: Channel Conditioned Cell Representations for unified evaluation in microscopy imaging
May 24, 2025Immunohistochemical (IHC) images reveal detailed information about structures and functions at the subcellular level. However, unlike natural images, IHC datasets pose challenges for deep learning models due to their inconsistencies in channel count and configuration, stemming from varying staining protocols across laboratories and studies. Existing approaches build channel-adaptive models, which unfortunately fail to support out-of-distribution (OOD) evaluation across IHC datasets and cannot be applied in a true zero-shot setting with mismatched channel counts. To address this, we introduce a structured view of cellular image channels by grouping them into either context or concept, where we treat the context channels as a reference to the concept channels in the image. We leverage this context-concept principle to develop Channel Conditioned Cell Representations (C3R), a framework designed for unified evaluation on in-distribution (ID) and OOD datasets. C3R is a two-fold framework comprising a channel-adaptive encoder architecture and a masked knowledge distillation training strategy, both built around the context-concept principle. We find that C3R outperforms existing benchmarks on both ID and OOD tasks, while a trivial implementation of our core idea also outperforms the channel-adaptive methods reported on the CHAMMI benchmark. Our method opens a new pathway for cross-dataset generalization between IHC datasets, without requiring dataset-specific adaptation or retraining.
One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
Feb 27, 2025Advanced image fusion methods mostly prioritise high-level missions, where task interaction struggles with semantic gaps, requiring complex bridging mechanisms. In contrast, we propose to leverage low-level vision tasks from digital photography fusion, allowing for effective feature interaction through pixel-level supervision. This new paradigm provides strong guidance for unsupervised multimodal fusion without relying on abstract semantics, enhancing task-shared feature learning for broader applicability. Owning to the hybrid image features and enhanced universal representations, the proposed GIFNet supports diverse fusion tasks, achieving high performance across both seen and unseen scenarios with a single model. Uniquely, experimental results reveal that our framework also supports single-modality enhancement, offering superior flexibility for practical applications. Our code will be available at https://github.com/AWCXV/GIFNet.
Rethinking Positive Pairs in Contrastive Learning
Oct 23, 2024



Contrastive learning, a prominent approach to representation learning, traditionally assumes positive pairs are closely related samples (the same image or class) and negative pairs are distinct samples. We challenge this assumption by proposing to learn from arbitrary pairs, allowing any pair of samples to be positive within our framework.The primary challenge of the proposed approach lies in applying contrastive learning to disparate pairs which are semantically distant. Motivated by the discovery that SimCLR can separate given arbitrary pairs (e.g., garter snake and table lamp) in a subspace, we propose a feature filter in the condition of class pairs that creates the requisite subspaces by gate vectors selectively activating or deactivating dimensions. This filter can be optimized through gradient descent within a conventional contrastive learning mechanism. We present Hydra, a universal contrastive learning framework for visual representations that extends conventional contrastive learning to accommodate arbitrary pairs. Our approach is validated using IN1K, where 1K diverse classes compose 500,500 pairs, most of them being distinct. Surprisingly, Hydra achieves superior performance in this challenging setting. Additional benefits include the prevention of dimensional collapse and the discovery of class relationships. Our work highlights the value of learning common features of arbitrary pairs and potentially broadens the applicability of contrastive learning techniques on the sample pairs with weak relationships.
C2C: Component-to-Composition Learning for Zero-Shot Compositional Action Recognition
Jul 08, 2024



Compositional actions consist of dynamic (verbs) and static (objects) concepts. Humans can easily recognize unseen compositions using the learned concepts. For machines, solving such a problem requires a model to recognize unseen actions composed of previously observed verbs and objects, thus requiring, so-called, compositional generalization ability. To facilitate this research, we propose a novel Zero-Shot Compositional Action Recognition (ZS-CAR) task. For evaluating the task, we construct a new benchmark, Something-composition (Sth-com), based on the widely used Something-Something V2 dataset. We also propose a novel Component-to-Composition (C2C) learning method to solve the new ZS-CAR task. C2C includes an independent component learning module and a composition inference module. Last, we devise an enhanced training strategy to address the challenges of component variation between seen and unseen compositions and to handle the subtle balance between learning seen and unseen actions. The experimental results demonstrate that the proposed framework significantly surpasses the existing compositional generalization methods and sets a new state-of-the-art. The new Sth-com benchmark and code are available at https://github.com/RongchangLi/ZSCAR_C2C.
Pseudo Labelling for Enhanced Masked Autoencoders
Jun 25, 2024Masked Image Modeling (MIM)-based models, such as SdAE, CAE, GreenMIM, and MixAE, have explored different strategies to enhance the performance of Masked Autoencoders (MAE) by modifying prediction, loss functions, or incorporating additional architectural components. In this paper, we propose an enhanced approach that boosts MAE performance by integrating pseudo labelling for both class and data tokens, alongside replacing the traditional pixel-level reconstruction with token-level reconstruction. This strategy uses cluster assignments as pseudo labels to promote instance-level discrimination within the network, while token reconstruction requires generation of discrete tokens encapturing local context. The targets for pseudo labelling and reconstruction needs to be generated by a teacher network. To disentangle the generation of target pseudo labels and the reconstruction of the token features, we decouple the teacher into two distinct models, where one serves as a labelling teacher and the other as a reconstruction teacher. This separation proves empirically superior to a single teacher, while having negligible impact on throughput and memory consumption. Incorporating pseudo-labelling as an auxiliary task has demonstrated notable improvements in ImageNet-1K and other downstream tasks, including classification, semantic segmentation, and detection.
Investigating Self-Supervised Methods for Label-Efficient Learning
Jun 25, 2024



Vision transformers combined with self-supervised learning have enabled the development of models which scale across large datasets for several downstream tasks like classification, segmentation and detection. The low-shot learning capability of these models, across several low-shot downstream tasks, has been largely under explored. We perform a system level study of different self supervised pretext tasks, namely contrastive learning, clustering, and masked image modelling for their low-shot capabilities by comparing the pretrained models. In addition we also study the effects of collapse avoidance methods, namely centring, ME-MAX, sinkhorn, on these downstream tasks. Based on our detailed analysis, we introduce a framework involving both mask image modelling and clustering as pretext tasks, which performs better across all low-shot downstream tasks, including multi-class classification, multi-label classification and semantic segmentation. Furthermore, when testing the model on full scale datasets, we show performance gains in multi-class classification, multi-label classification and semantic segmentation.
Revisiting RGBT Tracking Benchmarks from the Perspective of Modality Validity: A New Benchmark, Problem, and Method
Apr 30, 2024RGBT tracking draws increasing attention due to its robustness in multi-modality warranting (MMW) scenarios, such as nighttime and bad weather, where relying on a single sensing modality fails to ensure stable tracking results. However, the existing benchmarks predominantly consist of videos collected in common scenarios where both RGB and thermal infrared (TIR) information are of sufficient quality. This makes the data unrepresentative of severe imaging conditions, leading to tracking failures in MMW scenarios. To bridge this gap, we present a new benchmark, MV-RGBT, captured specifically in MMW scenarios. In contrast with the existing datasets, MV-RGBT comprises more object categories and scenes, providing a diverse and challenging benchmark. Furthermore, for severe imaging conditions of MMW scenarios, a new problem is posed, namely \textit{when to fuse}, to stimulate the development of fusion strategies for such data. We propose a new method based on a mixture of experts, namely MoETrack, as a baseline fusion strategy. In MoETrack, each expert generates independent tracking results along with the corresponding confidence score, which is used to control the fusion process. Extensive experimental results demonstrate the significant potential of MV-RGBT in advancing RGBT tracking and elicit the conclusion that fusion is not always beneficial, especially in MMW scenarios. Significantly, the proposed MoETrack method achieves new state-of-the-art results not only on MV-RGBT, but also on standard benchmarks, such as RGBT234, LasHeR, and the short-term split of VTUAV (VTUAV-ST). More information of MV-RGBT and the source code of MoETrack will be released at https://github.com/Zhangyong-Tang/MoETrack.