 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Drug-Drug Interaction Modeling as Generalizable Relation Learning
Jan 22, 2026Drug-drug interaction (DDI) prediction is central to drug discovery and clinical development, particularly in the context of increasingly prevalent polypharmacy. Although existing computational methods achieve strong performance on standard benchmarks, they often fail to generalize to realistic deployment scenarios, where most candidate drug pairs involve previously unseen drugs and validated interactions are scarce. We demonstrate that proximity in the embedding spaces of prevailing molecule-centric DDI models does not reliably correspond to interaction labels, and that simply scaling up model capacity therefore fails to improve generalization. To address these limitations, we propose GenRel-DDI, a generalizable relation learning framework that reformulates DDI prediction as a relation-centric learning problem, in which interaction representations are learned independently of drug identities. This relation-level abstraction enables the capture of transferable interaction patterns that generalize to unseen drugs and novel drug pairs. Extensive experiments across multiple benchmark demonstrate that GenRel-DDI consistently and significantly outperforms state-of-the-art methods, with particularly large gains on strict entity-disjoint evaluations, highlighting the effectiveness and practical utility of relation learning for robust DDI prediction. The code is available at https://github.com/SZU-ADDG/GenRel-DDI.
Rethinking Positive Pairs in Contrastive Learning
Oct 23, 2024



Contrastive learning, a prominent approach to representation learning, traditionally assumes positive pairs are closely related samples (the same image or class) and negative pairs are distinct samples. We challenge this assumption by proposing to learn from arbitrary pairs, allowing any pair of samples to be positive within our framework.The primary challenge of the proposed approach lies in applying contrastive learning to disparate pairs which are semantically distant. Motivated by the discovery that SimCLR can separate given arbitrary pairs (e.g., garter snake and table lamp) in a subspace, we propose a feature filter in the condition of class pairs that creates the requisite subspaces by gate vectors selectively activating or deactivating dimensions. This filter can be optimized through gradient descent within a conventional contrastive learning mechanism. We present Hydra, a universal contrastive learning framework for visual representations that extends conventional contrastive learning to accommodate arbitrary pairs. Our approach is validated using IN1K, where 1K diverse classes compose 500,500 pairs, most of them being distinct. Surprisingly, Hydra achieves superior performance in this challenging setting. Additional benefits include the prevention of dimensional collapse and the discovery of class relationships. Our work highlights the value of learning common features of arbitrary pairs and potentially broadens the applicability of contrastive learning techniques on the sample pairs with weak relationships.
DailyMAE: Towards Pretraining Masked Autoencoders in One Day
Mar 31, 2024Recently, masked image modeling (MIM), an important self-supervised learning (SSL) method, has drawn attention for its effectiveness in learning data representation from unlabeled data. Numerous studies underscore the advantages of MIM, highlighting how models pretrained on extensive datasets can enhance the performance of downstream tasks. However, the high computational demands of pretraining pose significant challenges, particularly within academic environments, thereby impeding the SSL research progress. In this study, we propose efficient training recipes for MIM based SSL that focuses on mitigating data loading bottlenecks and employing progressive training techniques and other tricks to closely maintain pretraining performance. Our library enables the training of a MAE-Base/16 model on the ImageNet 1K dataset for 800 epochs within just 18 hours, using a single machine equipped with 8 A100 GPUs. By achieving speed gains of up to 5.8 times, this work not only demonstrates the feasibility of conducting high-efficiency SSL training but also paves the way for broader accessibility and promotes advancement in SSL research particularly for prototyping and initial testing of SSL ideas. The code is available in https://github.com/erow/FastSSL.
Beyond Accuracy: Statistical Measures and Benchmark for Evaluation of Representation from Self-Supervised Learning
Dec 02, 2023Recently, self-supervised metric learning has raised attention for the potential to learn a generic distance function. It overcomes the limitations of conventional supervised one, e.g., scalability and label biases. Despite progress in this domain, current benchmarks, incorporating a narrow scope of classes, stop the nuanced evaluation of semantic representations. To bridge this gap, we introduce a large-scale benchmark with diversity and granularity of classes, Statistical Metric Learning Benchmark (SMLB) built upon ImageNet-21K and WordNet. SMLB is designed to rigorously evaluate the discriminative discernment and generalizability across more than 14M images, 20K classes, and 16K taxonomic nodes. Alongside, we propose novel evaluation metrics -- `overlap' for separability and `aSTD' for consistency -- to measure distance statistical information, which are efficient and robust to the change of class number. Our benchmark offers a novel perspective of evaluating the quality of representations beyond accuracy. Our findings reveal the limitations of supervised learning and the class bias inherent in SSL models, offering insights into potential areas for future model enhancement.
Masked Momentum Contrastive Learning for Zero-shot Semantic Understanding
Aug 22, 2023Self-supervised pretraining (SSP) has emerged as a popular technique in machine learning, enabling the extraction of meaningful feature representations without labelled data. In the realm of computer vision, pretrained vision transformers (ViTs) have played a pivotal role in advancing transfer learning. Nonetheless, the escalating cost of finetuning these large models has posed a challenge due to the explosion of model size. This study endeavours to evaluate the effectiveness of pure self-supervised learning (SSL) techniques in computer vision tasks, obviating the need for finetuning, with the intention of emulating human-like capabilities in generalisation and recognition of unseen objects. To this end, we propose an evaluation protocol for zero-shot segmentation based on a prompting patch. Given a point on the target object as a prompt, the algorithm calculates the similarity map between the selected patch and other patches, upon that, a simple thresholding is applied to segment the target. Another evaluation is intra-object and inter-object similarity to gauge discriminatory ability of SSP ViTs. Insights from zero-shot segmentation from prompting and discriminatory abilities of SSP led to the design of a simple SSP approach, termed MMC. This approaches combines Masked image modelling for encouraging similarity of local features, Momentum based self-distillation for transferring semantics from global to local features, and global Contrast for promoting semantics of global features, to enhance discriminative representations of SSP ViTs. Consequently, our proposed method significantly reduces the overlap of intra-object and inter-object similarities, thereby facilitating effective object segmentation within an image. Our experiments reveal that MMC delivers top-tier results in zero-shot semantic segmentation across various datasets.
Variantional autoencoder with decremental information bottleneck for disentanglement
Mar 22, 2023One major challenge of disentanglement learning with variational autoencoders is the trade-off between disentanglement and reconstruction fidelity. Previous incremental methods with only on latent space cannot optimize these two targets simultaneously, so they expand the Information Bottleneck while training to {optimize from disentanglement to reconstruction. However, a large bottleneck will lose the constraint of disentanglement, causing the information diffusion problem. To tackle this issue, we present a novel decremental variational autoencoder with disentanglement-invariant transformations to optimize multiple objectives in different layers, termed DeVAE, for balancing disentanglement and reconstruction fidelity by decreasing the information bottleneck of diverse latent spaces gradually. Benefiting from the multiple latent spaces, DeVAE allows simultaneous optimization of multiple objectives to optimize reconstruction while keeping the constraint of disentanglement, avoiding information diffusion. DeVAE is also compatible with large models with high-dimension latent space. Experimental results on dSprites and Shapes3D that DeVAE achieves \fix{R2q6}{a good balance between disentanglement and reconstruction.DeVAE shows high tolerant of hyperparameters and on high-dimensional latent spaces.
A semantic web approach to uplift decentralized household energy data
Aug 26, 2022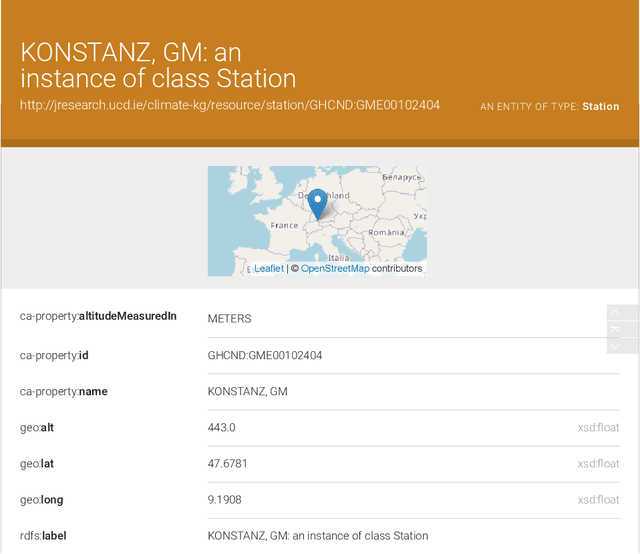

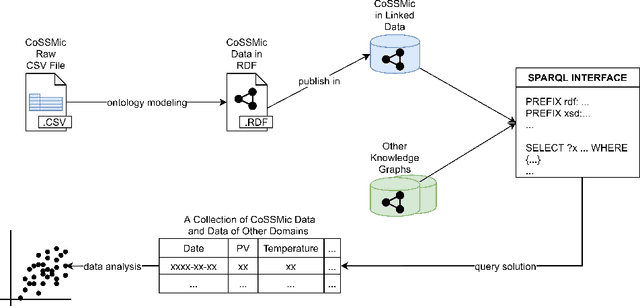

In a decentralized household energy system comprised of various devices such as home appliances, electric vehicles, and solar panels, end-users are able to dig deeper into the system's details and further achieve energy sustainability if they are presented with data on the electric energy consumption and production at the granularity of the device. However, many databases in this field are siloed from other domains, including solely information pertaining to energy. This may result in the loss of information (e.g. weather) on each device's energy use. Meanwhile, a large number of these datasets have been extensively used in computational modeling techniques such as machine learning models. While such computational approaches achieve great accuracy and performance by concentrating only on a local view of datasets, model reliability cannot be guaranteed since such models are very vulnerable to data input fluctuations when information omission is taken into account. This article tackles the data isolation issue in the field of smart energy systems by examining Semantic Web methods on top of a household energy system. We offer an ontology-based approach for managing decentralized data at the device-level resolution in a system. As a consequence, the scope of the data associated with each device may easily be expanded in an interoperable manner throughout the Web, and additional information, such as weather, can be obtained from the Web, provided that the data is organized according to W3C standards.
Object-wise Masked Autoencoders for Fast Pre-training
May 28, 2022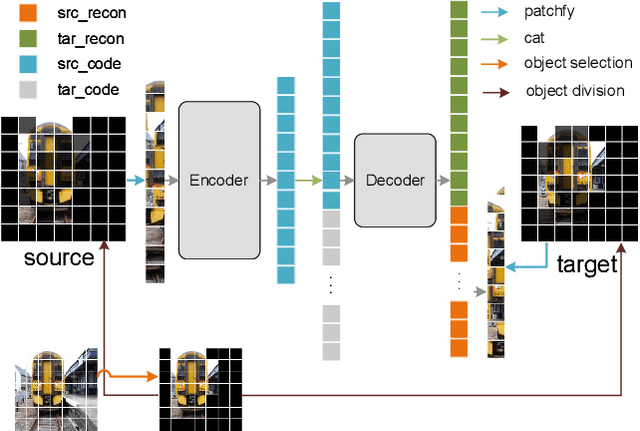

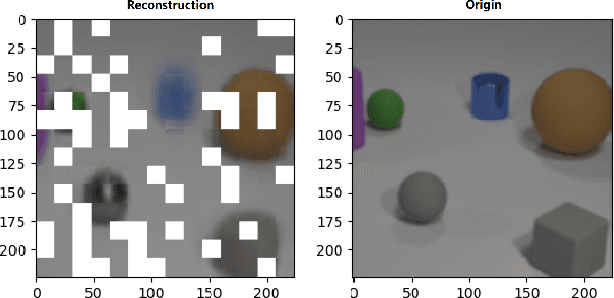
Self-supervised pre-training for images without labels has recently achieved promising performance in image classification. The success of transformer-based methods, ViT and MAE, draws the community's attention to the design of backbone architecture and self-supervised task. In this work, we show that current masked image encoding models learn the underlying relationship between all objects in the whole scene, instead of a single object representation. Therefore, those methods bring a lot of compute time for self-supervised pre-training. To solve this issue, we introduce a novel object selection and division strategy to drop non-object patches for learning object-wise representations by selective reconstruction with interested region masks. We refer to this method ObjMAE. Extensive experiments on four commonly-used datasets demonstrate the effectiveness of our model in reducing the compute cost by 72% while achieving competitive performance. Furthermore, we investigate the inter-object and intra-object relationship and find that the latter is crucial for self-supervised pre-training.
DEFT: Distilling Entangled Factors
Feb 08, 2021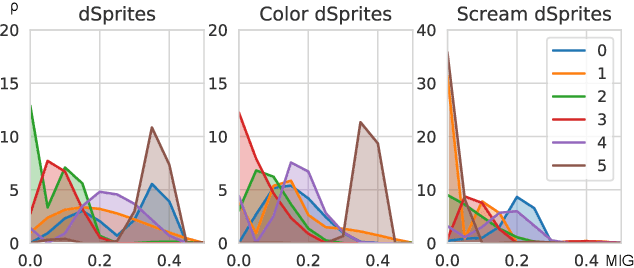
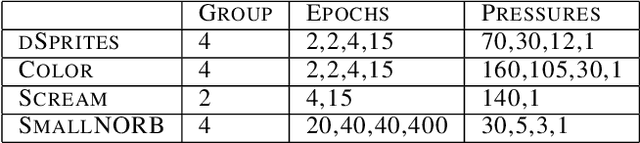
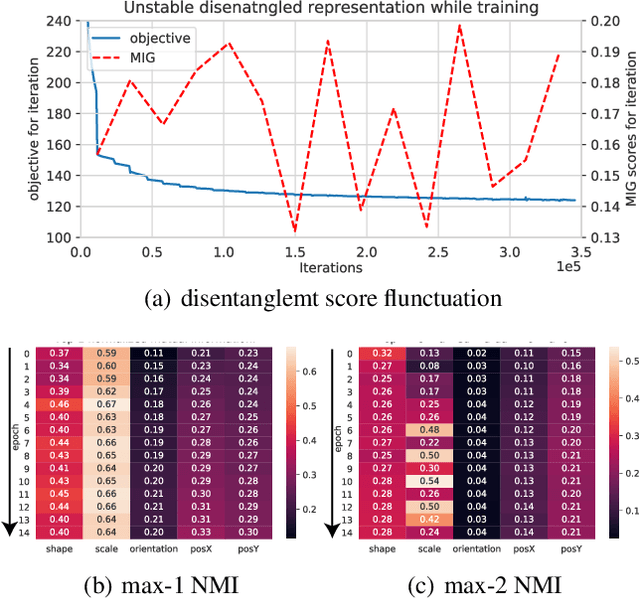
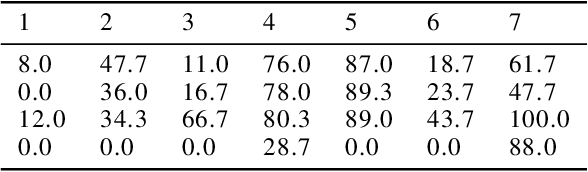
Disentanglement is a highly desirable property of representation due to its similarity with human understanding and reasoning. However, the performance of current disentanglement approaches is still unreliable and largely depends on the hyperparameter selection. Inspired by fractional distillation in chemistry, we propose DEFT, a disentanglement framework, to raise the lower limit of disentanglement approaches based on variational autoencoder. It applies a multi-stage training strategy, including multi-group encoders with different learning rates and piecewise disentanglement pressure, to stage by stage distill entangled factors. Furthermore, we provide insight into identifying the hyperparameters according to the information thresholds. We evaluate DEFT on three variants of dSprite and SmallNORB, showing robust and high-level disentanglement scores.
Disentangling Action Sequences: Discovering Correlated Samples
Oct 17, 2020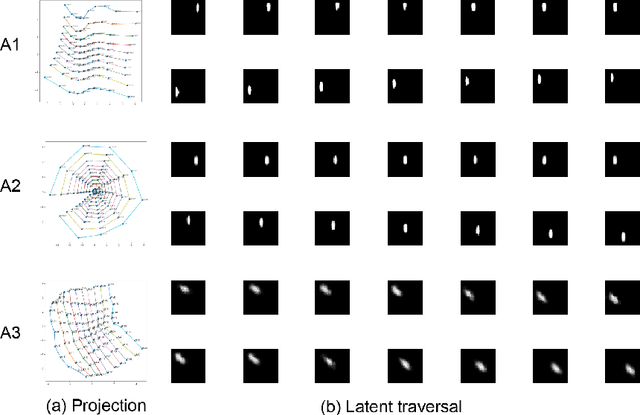



Disentanglement is a highly desirable property of representation due to its similarity with human's understanding and reasoning. This improves interpretability, enables the performance of down-stream tasks, and enables controllable generative models. However, this domain is challenged by the abstract notion and incomplete theories to support unsupervised disentanglement learning. We demonstrate the data itself, such as the orientation of images, plays a crucial role in disentanglement and instead of the factors, and the disentangled representations align the latent variables with the action sequences. We further introduce the concept of disentangling action sequences which facilitates the description of the behaviours of the existing disentangling approaches. An analogy for this process is to discover the commonality between the things and categorizing them. Furthermore, we analyze the inductive biases on the data and find that the latent information thresholds are correlated with the significance of the actions. For the supervised and unsupervised settings, we respectively introduce two methods to measure the thresholds. We further propose a novel framework, fractional variational autoencoder (FVAE), to disentangle the action sequences with different significance step-by-step. Experimental results on dSprites and 3D Chairs show that FVAE improves the stability of disentanglement.